

多模态王炸大模型GPT-4V,166页“说明书”重磅发布!而且还是微软团队出品。
什么样的论文,能写出166页?
不仅详细测评了GPT-4V在十大任务上的表现,从基础的图像识别、到复杂的逻辑推理都有展示;
还传授了一整套多模态大模型提示词使用技巧——
回答专业程度一看就懂,属实是把GPT-4V的使用门槛打到不存在了。
值得一提的是,这篇论文的作者也是“全华班”,7名作者全部是华人,领衔的是一位在微软工作了17年的女性首席研究经理。
在166页报告发布前,他们还参与了OpenAI最新DALL·E 3的研究,对这个领域了解颇深。
相比OpenAI的18页GPT-4V论文,这篇166页“食用指南”一发布,立刻被奉为GPT-4V用户必读之物:
有网友感慨:这哪里是论文,这简直快成一本166页的小书了。
还有网友看完已经感到慌了:
不要只看GPT-4V的回答细节,我真的对AI展现出来的潜在能力感到害怕。

所以,微软这篇“论文”究竟讲了啥,又展现出了GPT-4V的哪些“潜力”?
微软166页报告讲了啥?
这篇论文钻研GPT-4V的方法,核心就靠一个字——“试”。
微软研究员们设计了涵盖多个领域的一系列输入,将它们喂给GPT-4V,并观察和记录GPT-4V的输出。
随后,他们对GPT-4V完成各类任务的能力进行评估,还给出了使用GPT-4V的新提示词技巧,具体包括4大方面:
1、GPT-4V的用法:
5种使用方式:输入图像(images)、子图像(sub-images)、文本(texts)、场景文本(scene texts)和视觉指针(visual pointers)。
3种支持的能力:指令遵循(instruction following)、思维链(chain-of-thoughts)、上下文少样本学习(in-context few-shot learning)。
例如这是基于思维链变更提问方式后,GPT-4V展现出的指令遵循能力:
2、GPT-4V在10大任务中的表现:
开放世界视觉理解(open-world visual understanding)、视觉描述(visual description)、多模态知识(multimodal knowledge)、常识(commonsense)、场景文本理解(scene text understandin)、文档推理(document reasoning)、写代码(coding)、时间推理(temporal reasonin)、抽象推理(abstract reasoning)、情感理解(emotion understanding)
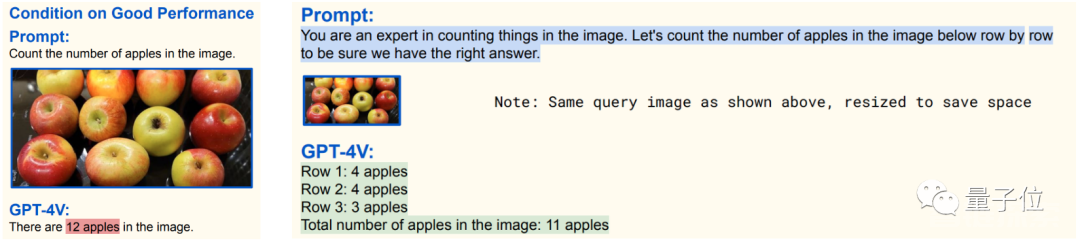
其中就包括这种,需要一些智商才能做出来的“图像推理题”:

3、类GPT-4V多模态大模型的提示词技巧:
提出了一种新的多模态提示词技巧“视觉参考提示”(visual referring prompting),可以通过直接编辑输入图像来指示感兴趣的任务,并结合其他提示词技巧使用。

4、多模态大模型的研究&落地潜力:
预测了多模态学习研究人员应该关注的2类领域,包括落地(潜在应用场景)和研究方向。
例如这是研究人员发现的GPT-4V可用场景之一——故障检测:

但无论是新的提示词技巧、还是GPT-4V的应用场景,大伙儿最关注的还是GPT-4V的真正实力。
所以,这份“说明书”随后用了150多页来展示各种demo,详细剧透了GPT-4V在面对不同回答时展现出的能力。
一起来看看GPT-4V如今的多模态能力进化到哪一步了。
精通专业领域图像,还能现学知识
图像识别
最基础的识别自然是不在话下,比如科技、体育界以及娱乐圈的各路名人:

而且不仅能看出这些人是谁,还能解读他们正在做什么,比如下图中老黄正在介绍英伟达新推出的显卡产品。

除了人物,地标建筑对于GPT-4V来说同样是小菜一碟,不仅能判断名称和所在地,还能给出详细的介绍。

△左:纽约时代广场,右:京都金阁寺
不过越是有名的人和地点,判断起来也就越容易,所以要难度更大的图才能展现GPT-4V的能力。
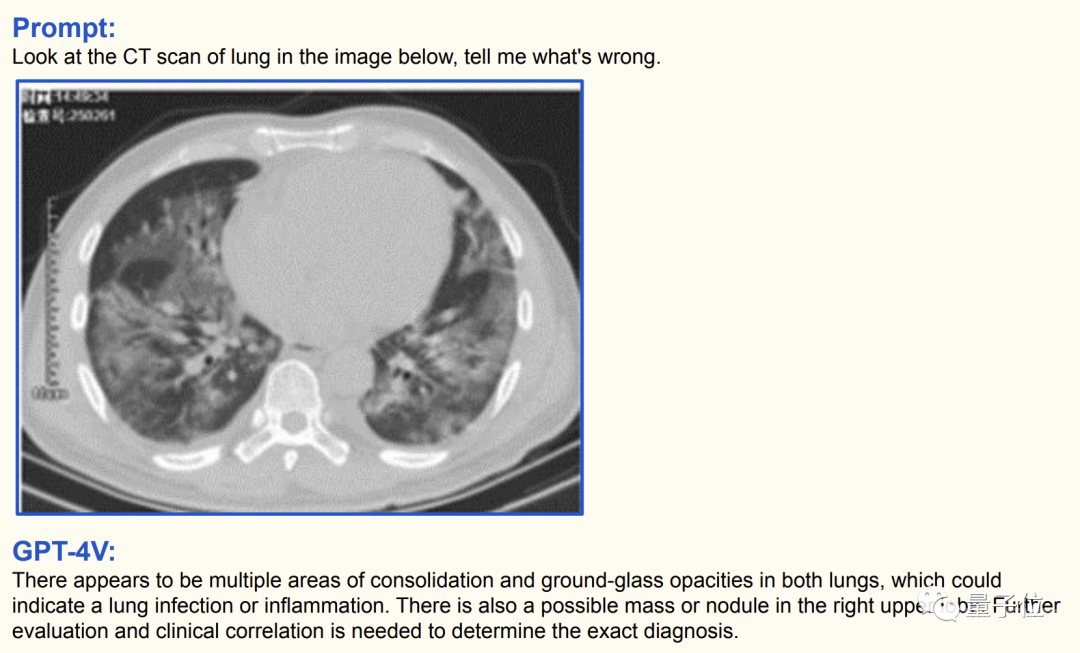
比如医学影像,针对下面这张肺部CT,GPT-4V给出了这样的结论:
双肺多个区域存在实变和磨玻璃混浊,肺部可能存在感染或炎症。右肺上叶也可能有肿块或结节。
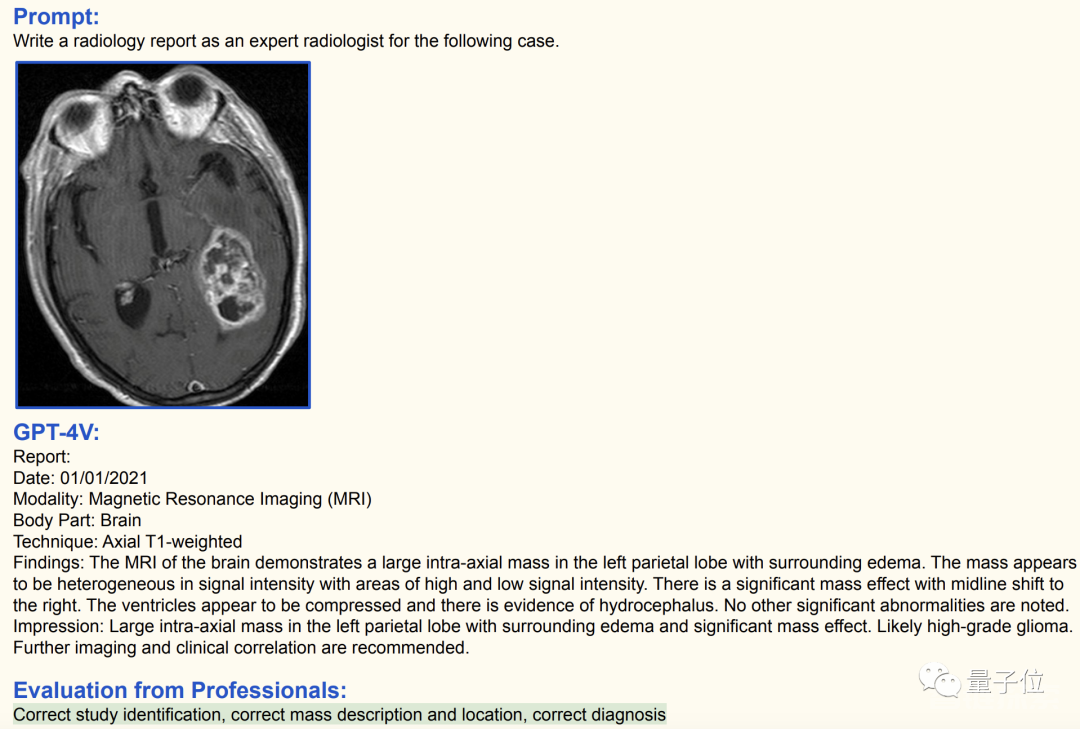
甚至不告诉GPT-4V影像的种类和位置,它自己也能判断。
这张图中,GPT-4V成功识别出了这是一张脑部的核磁共振(MRI)影像。
同时,GPT-4V还发现存在大量积液,认为很可能是高级别脑胶质瘤。
经过专业人士判断,GPT-4V给出的结论完全正确。
除了这些“正经”的内容之外,当代人类社会的“非物质文化遗产”表情包也被GPT-4V给拿捏了。
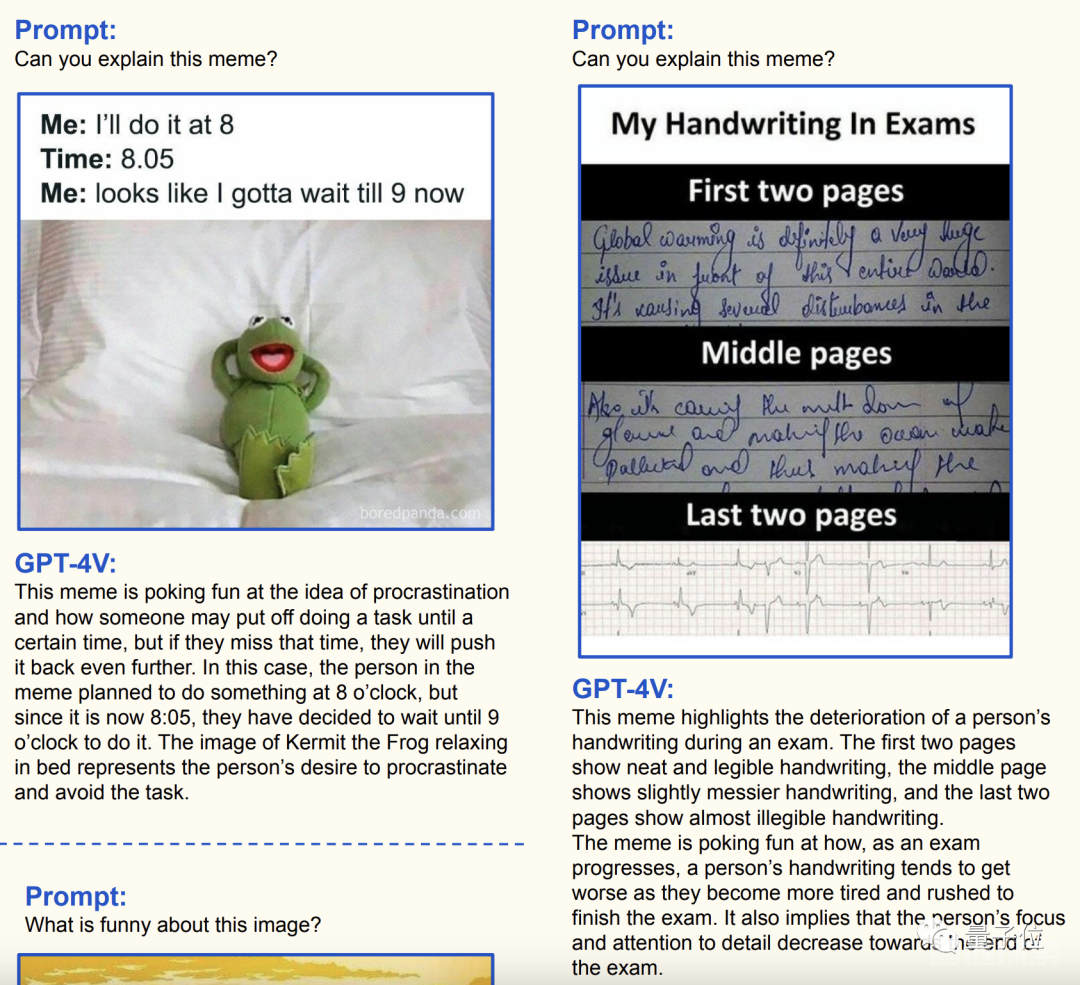

△机器翻译,仅供参考
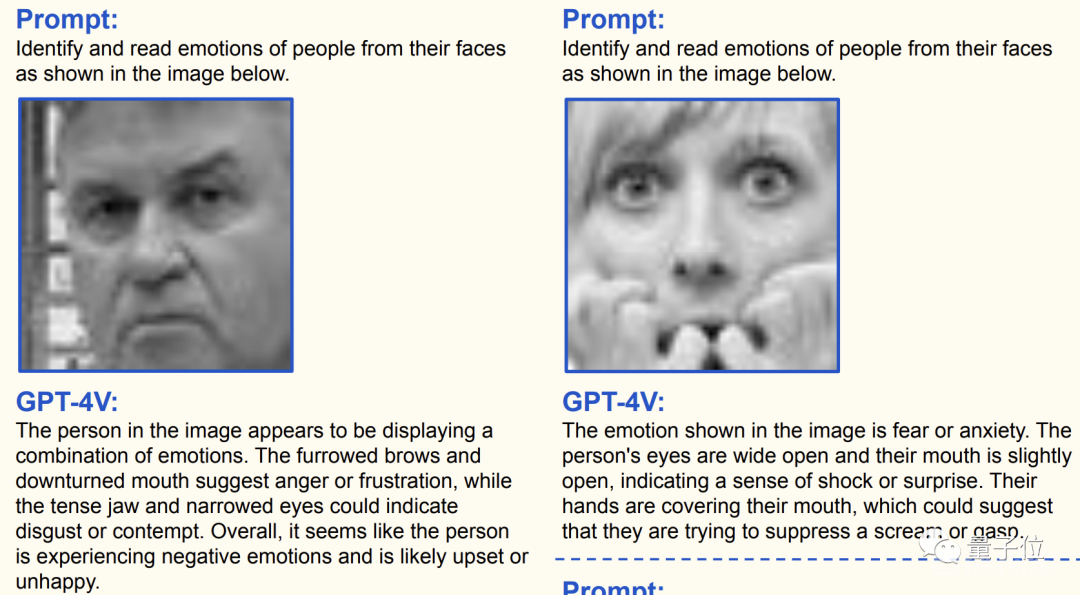
不仅是解读表情包中的梗,真实世界中人类的表情所表达的情感也能被GPT-4看穿。

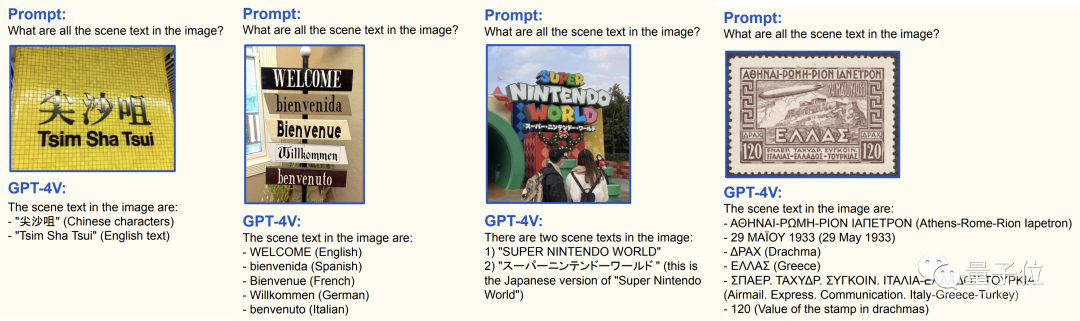
除了这些真·图像之外,文本识别也是机器视觉中的一项重要任务。
这方面,GPT-4V除了可以识别拉丁文字拼写的语言之外,中文、日文、希腊文等其他文字也都认识。
甚至是手写的数学公式:

图像推理
前面展示的DEMO,无论多么专业或多么难懂,都还停留在识别的范畴,但这只是GPT-4V技能的冰山一角。
除了看懂图片中的内容,GPT-4V还具有一定的推理能力。
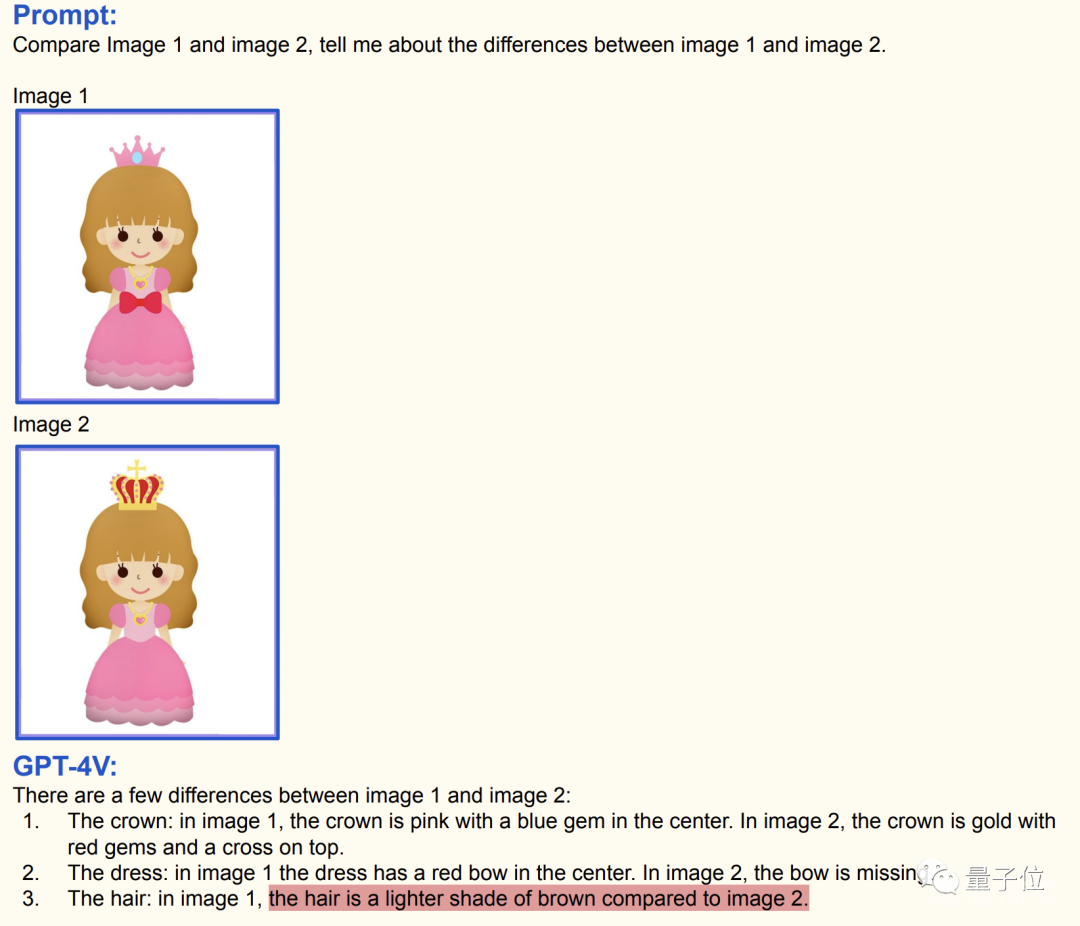
简单一些的,GPT-4V可以发现两张图中的不同(虽然还有些错误)。
下面的一组图中,王冠和蝴蝶结的区别都被GPT-4V发现了。
如果加大难度,GPT-4V还能解决IQ测试当中的图形问题。
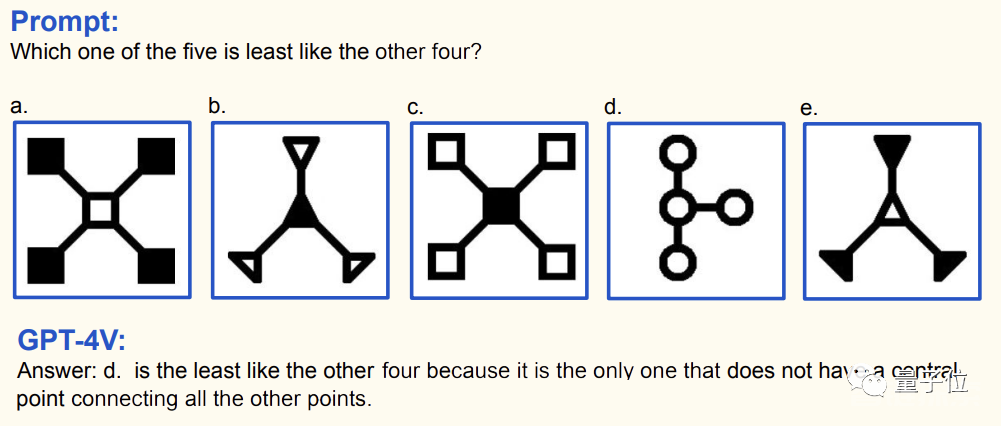
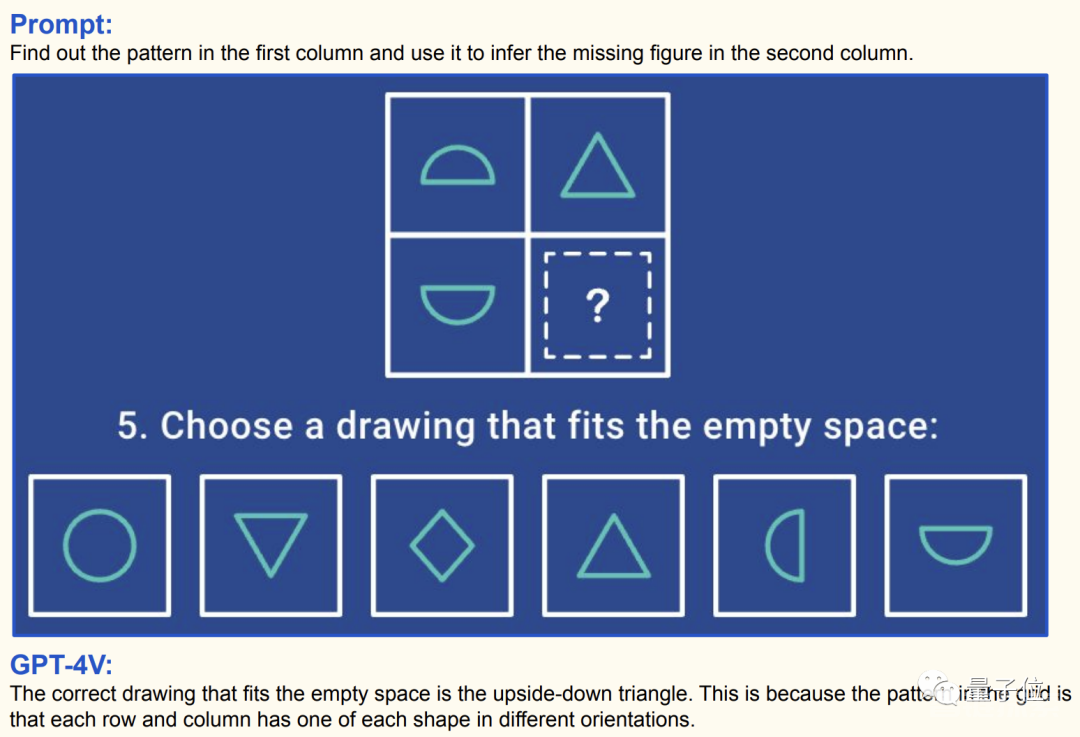
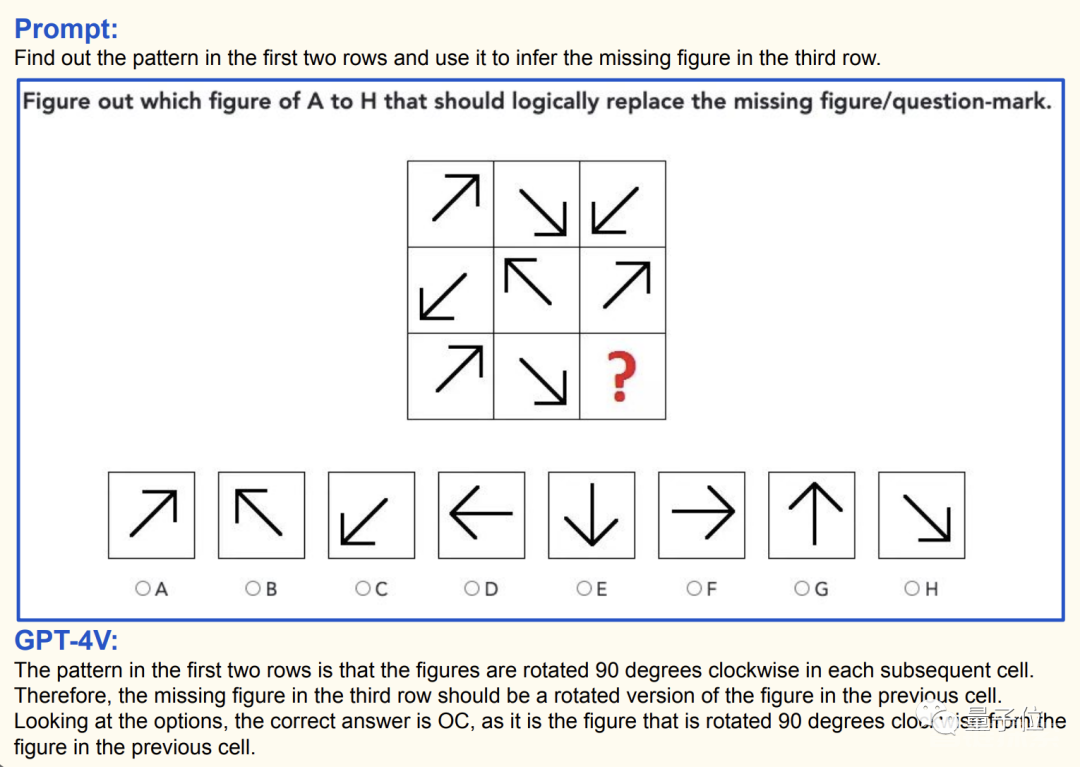
上面的这三道题中的特征或逻辑关系都还比较简单,但接下来就要上难度了:
当然难度不是在于图形本身,注意图中的第4条文字说明,原题目中图形的排列方式不是图中展示的样子。

图片标注
除了用文本回答各种问题,GPT-4V还可以在图片中执行一系列操作。
比如我们手里有一张四位AI巨头的合影,要GPT-4V框出其中的人物并标注他们的姓名和简介。

GPT-4V先是用文本回答了这些问题,紧接着便给出了处理之后的图片:

动态内容分析
除了这些静态内容,GPT-4V还能做动态分析,不过不是直接喂给模型一段视频。
下面的五张图是从一段制作寿司的教程视频中截取的,GPT-4V的任务是(在理解内容的基础上)推测这些图片出现的顺序。
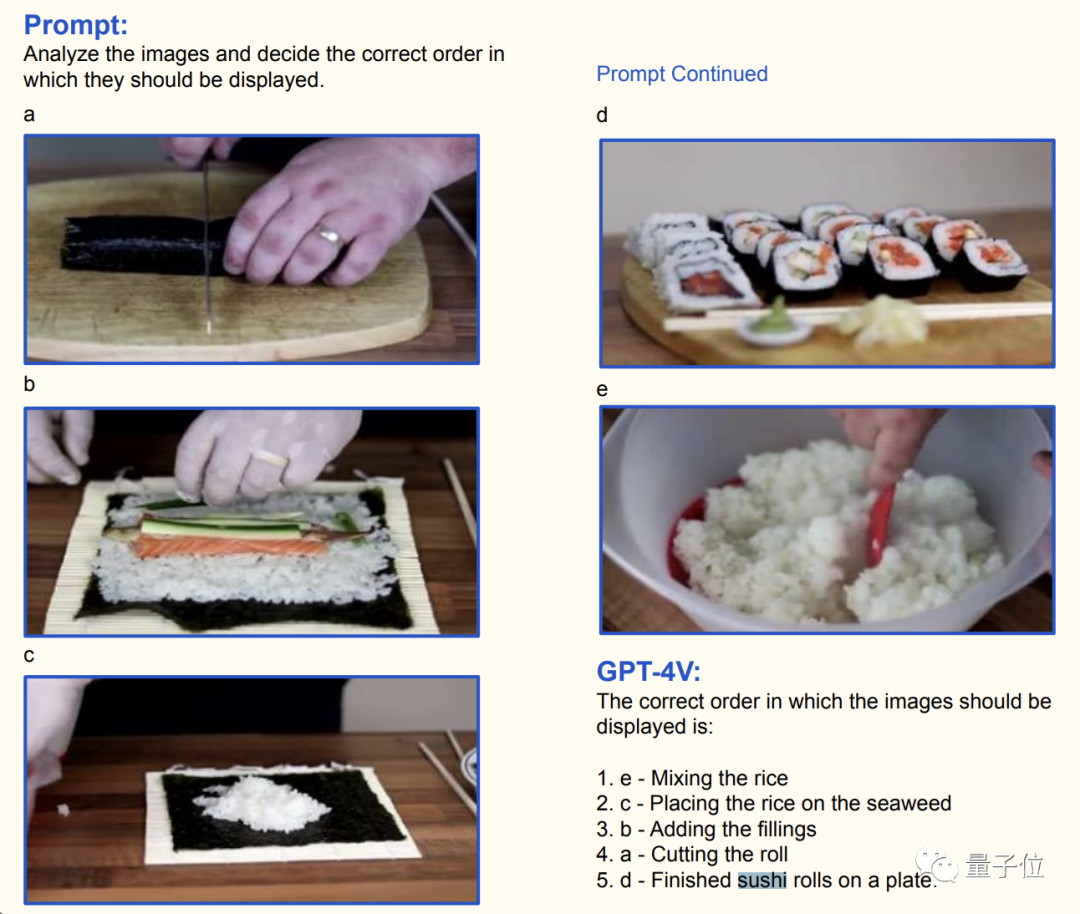
而针对同一系列的图片,可能会有不同的理解方式,这是GPT-4V会结合文本提示进行判断。
比如下面的一组图中,人的动作究竟是开门还是关门,会导致排序结果截然相反。

当然,通过多张图片中人物状态的变化,还可以推测出他们正在做的事情。

甚至是预测接下来会发生什么:

“现场学习”
GPT-4V不仅视觉本领强,关键是还能现学现卖。
还是举个例子,让GPT-4V读汽车仪表盘,一开始得出的答案是错误的:
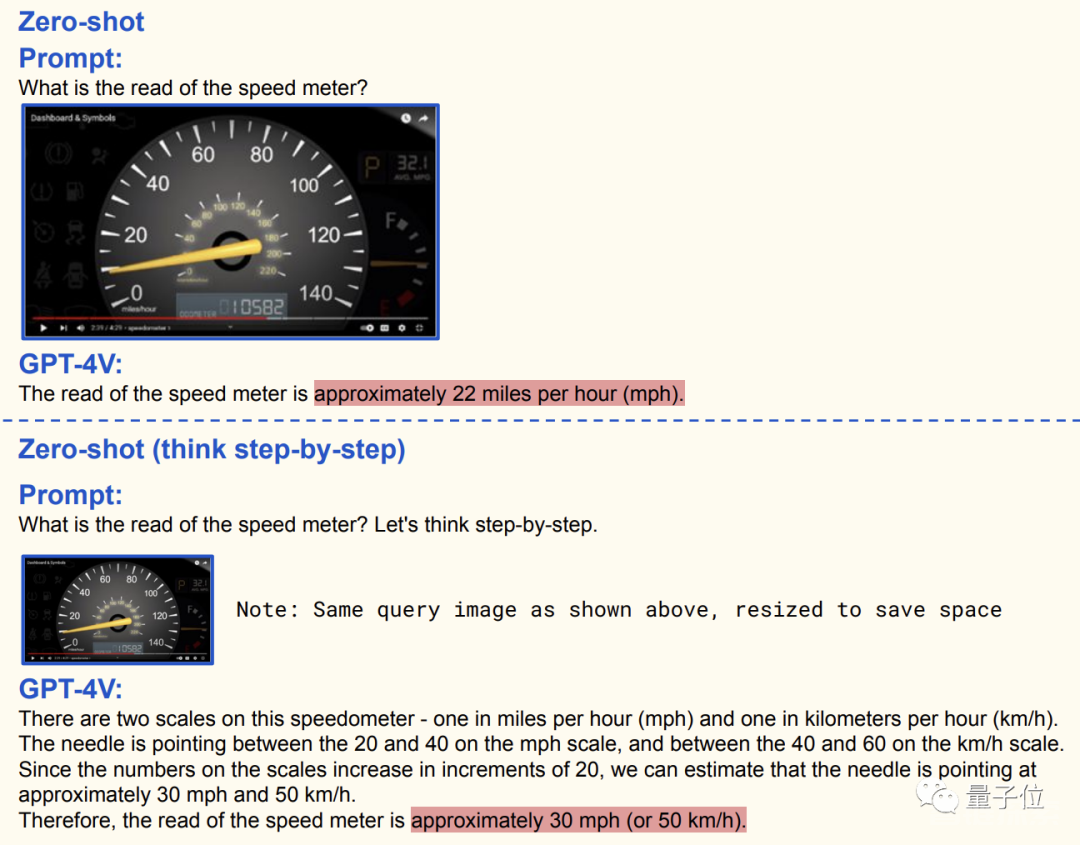
紧接着把方法用文字交给GPT-4V,但这是的答案依然不对:
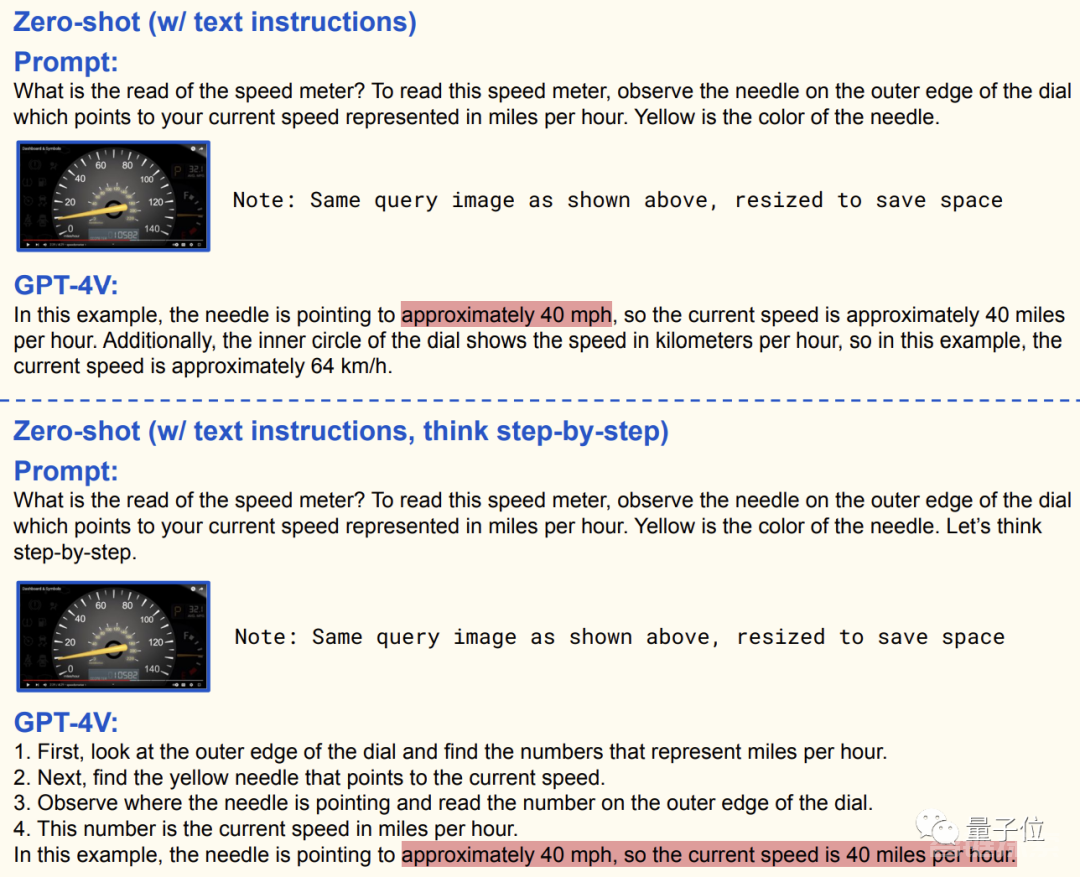
然后又把例子展示给GPT-4V,答案倒是有样学样,可惜数字是胡编乱造出来的。

只有一个例子的确是有点少,不过随着样本数量的提高(其实只多了一个),终于功夫不负有心人,GPT-4V给出了正确答案。
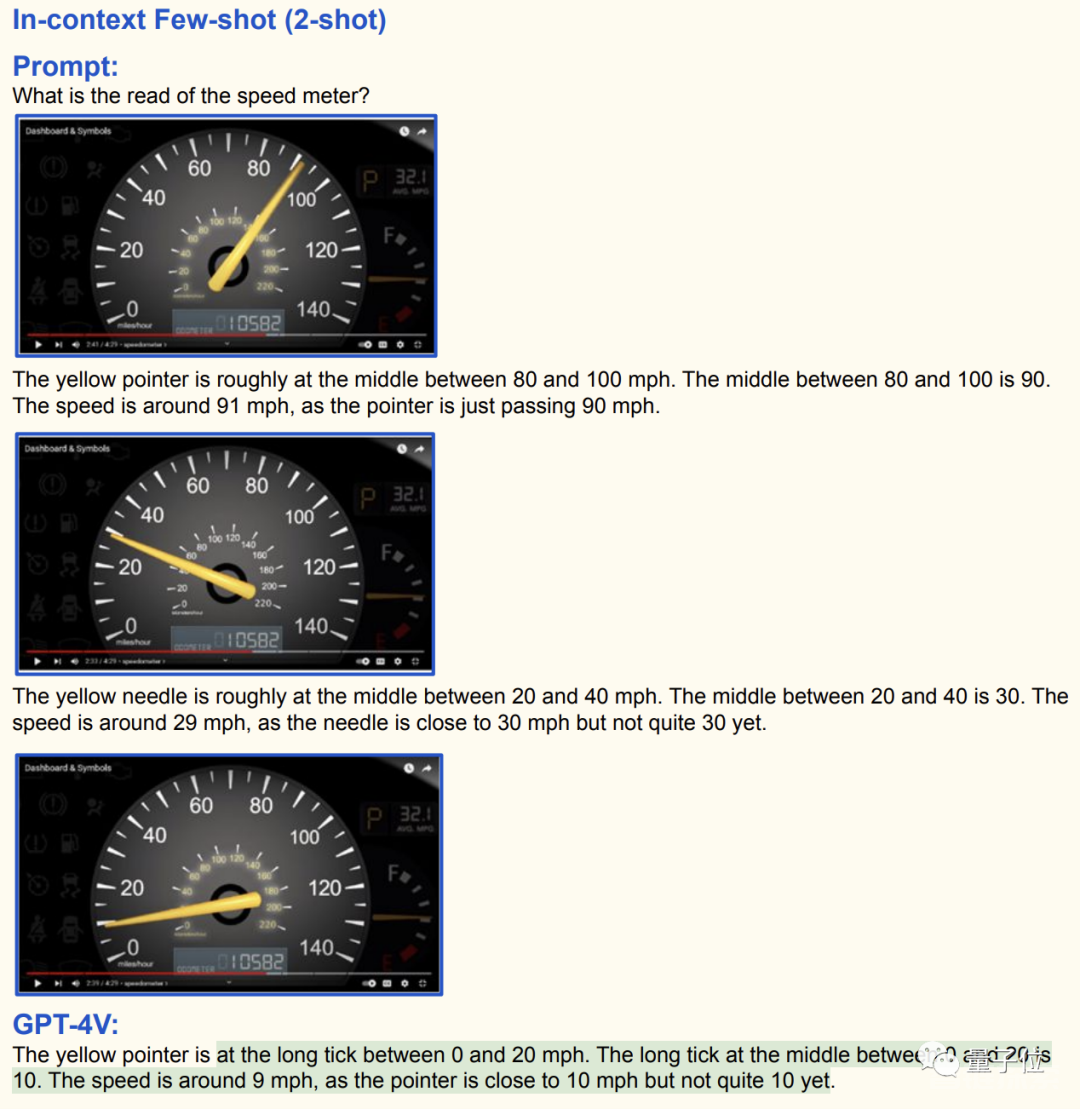
GPT-4V的效果就展示这么多,当然它还支持更多的领域和任务,这里无法一一展示,感兴趣的话可以阅读原始报告。
那么,GPT-4V这些神器的效果背后,是怎样的一个团队呢?
清华校友领衔
这篇论文的作者一共有7位,均为华人,其中6位是核心作者。

项目领衔作者Lijuan Wang,是微软云计算与AI首席研究经理。

她本科毕业于华中科技大学,在中国清华大学获得博士学位,于2006年加入微软亚洲研究院,并于2016年加入位于雷德蒙德的微软研究院。
她的研究领域是基于多模态感知智能的深度学习和机器学习,具体又包括视觉语言模型预训练、图像字幕生成、目标检测等AI技术。
原文地址:https://arxiv.org/abs/2309.17421




还没有评论,来说两句吧...