

如果你体验过与任何一款对话式 AI 机器人的交流,你一定能想起某些极具「挫败感」的时刻。比如,你在前一天的对话中讲述过的要点,被 AI 忘得干干净净……
这是因为当前的多数 LLM 只能记住有限的上下文,就像为考试而临时抱佛脚的学生,稍加盘问就会「露出马脚」。
想象一下,如果 AI 助手在聊天中能够根据上下文参考几周或几个月前的对话,或者,你可以要求 AI 助手总结长达数千页的报告,这样的能力是不是令人羡慕?
为了让 LLM 记住更多、记得更好,研究者们正在不断努力。最近,来自 MIT、Meta AI、CMU 的研究者提出了一种名为「StreamingLLM」的方法,使语言模型能够流畅地处理无穷无尽的文本。

论文地址:https://arxiv.org/pdf/2309.17453.pdf
项目地址:https://github.com/mit-han-lab/streaming-llm
StreamingLLM 的工作原理是识别并保存模型固有的「注意力池」(attention sinks)锚定其推理的初始 token。结合最近 token 的滚动缓存,StreamingLLM 的推理速度提高了 22 倍,而不需要牺牲任何的准确性。短短几天,该项目在 GitHub 平台已斩获 2.5K 星:
具体地说,StreamingLLM 使得语言模型能准确无误地记住上一场比赛的触地得分、新生儿的名字、冗长的合同或辩论内容,就像升级了 AI 助理的内存,可以完美地处理更繁重的工作。

接下来让我们看看技术细节。
方法创新
通常,LLM 在预训练时受到注意力窗口的限制。尽管为扩大这一窗口大小、提高训练和推理效率,此前已有很多工作,但 LLM 可接受的序列长度仍然是有限的,这对于持久部署来说并不友好。
在这篇论文中,研究者首先介绍了 LLM 流应用的概念,并提出了一个问题:「能否在不牺牲效率和性能的情况下以无限长输入部署 LLM?」
将 LLM 应用于无限长输入流时,会面临两个主要挑战:
1、在解码阶段,基于 transformer 的 LLM 会缓存所有先前 token 的 Key 和 Value 状态(KV),如图 1 (a) 所示,这可能会导致内存使用过多,并增加解码延迟;
2、现有模型的长度外推能力有限,即当序列长度超过预训练时设定的注意力窗口大小时,其性能就会下降。
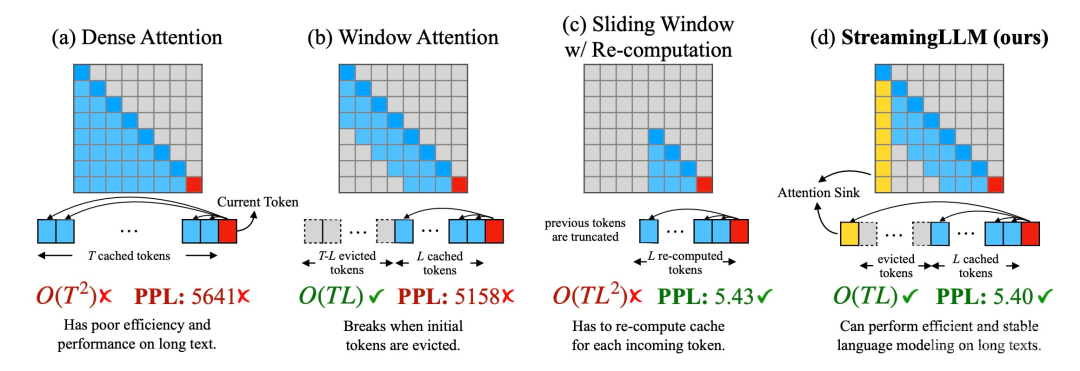
一种直观的方法被称为窗口注意力(Window Attention)(如图 1 b),这种方法只在最近 token 的 KV 状态上保持一个固定大小的滑动窗口,虽然能确保在缓存填满后仍能保持稳定的内存使用率和解码速度,但一旦序列长度超过缓存大小,甚至只是驱逐第一个 token 的 KV,模型就会崩溃。另一种方法是重新计算滑动窗口(如图 1 c 所示),这种方法会为每个生成的 token 重建最近 token 的 KV 状态,虽然性能强大,但需要在窗口内计算二次注意力,因此速度明显更慢,在实际的流应用中并不理想。
在理解窗口注意力失效的过程中,研究者发现了自回归 LLM 的一个有趣现象:如图 2 所示,大量注意力分数被分配给了初始 token,而不管这些 token 与语言建模任务是否相关。
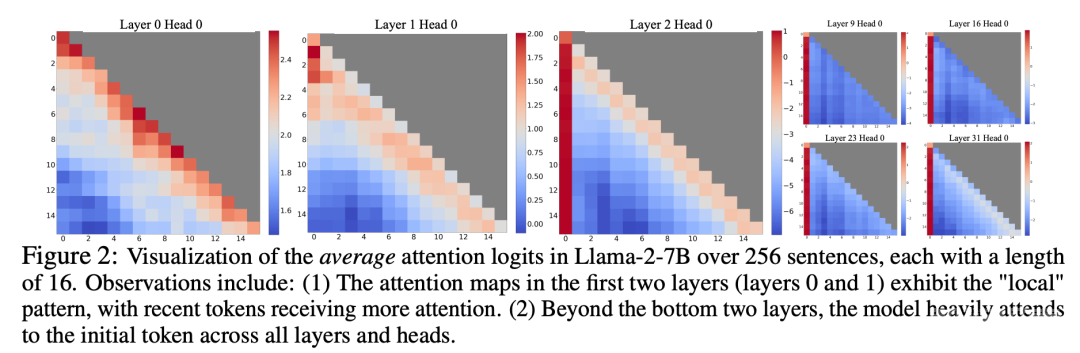
研究者将这些 token 称为「注意力池」:尽管它们缺乏语义上的意义,但却占据了大量的注意力分数。研究者将这一现象归因于于 Softmax(要求所有上下文 token 的注意力分数总和为 1),即使当前查询在许多以前的 token 中没有很强的匹配,模型仍然需要将这些不需要的注意力值分配到某处,从而使其总和为 1。初始 token 成为「池」的原因很直观:由于自回归语言建模的特性,初始 token 对几乎所有后续 token 都是可见的,这使得它们更容易被训练成注意力池。
基于上述洞察,研究者提出了 StreamingLLM,这是一个简单而高效的框架,它可以让使用有限注意力窗口训练的注意力模型在不进行微调的情况下处理无限长的文本。
StreamingLLM 利用了注意力池具有高注意力值这一事实,保留这些注意力池可以使注意力分数分布接近正态分布。因此,StreamingLLM 只需保留注意力池 token 的 KV 值(只需 4 个初始 token 即可)和滑动窗口的 KV 值,就能锚定注意力计算并稳定模型的性能。
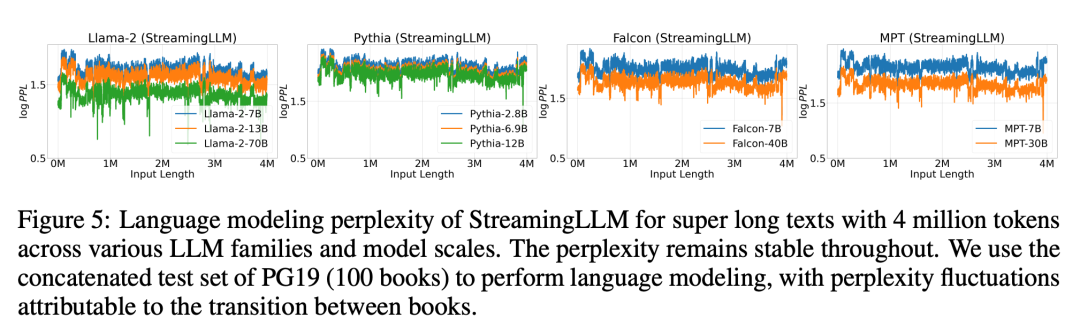
使用 StreamingLLM,包括 Llama-2-[7,13,70] B、MPT-[7,30] B、Falcon-[7,40] B 和 Pythia [2.9,6.9,12] B 在内的模型可以可靠地模拟 400 万个 token,甚至更多。
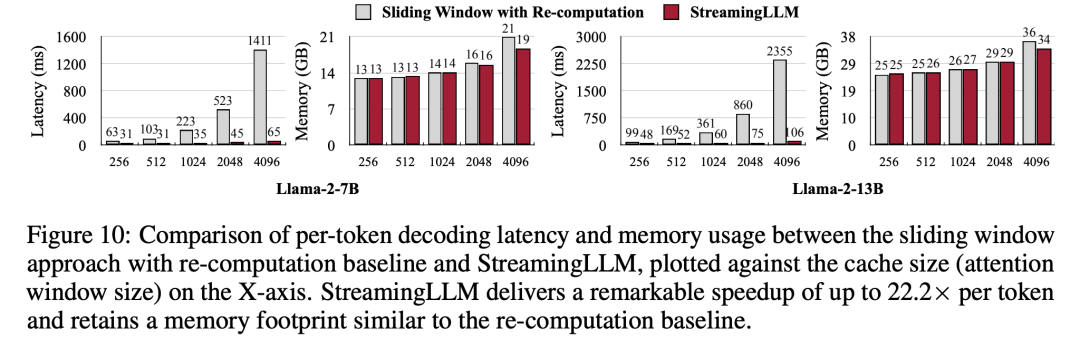
与唯一可行的 baseline—— 重新计算滑动窗口相比,StreamingLLM 的速度提高了 22.2 倍,而没有损耗性能。
测评
在实验环节,如图 3 所示,在跨度为 20K token 的文本上,StreamingLLM 的困惑度可以与 Oracle 基线(重新计算滑动窗口)相媲美。同时,当输入长度超过预训练窗口时,密集注意力就会失效,而当输入长度超过缓存大小时,窗口注意力就会陷入困境,导致初始 token 被剔除。
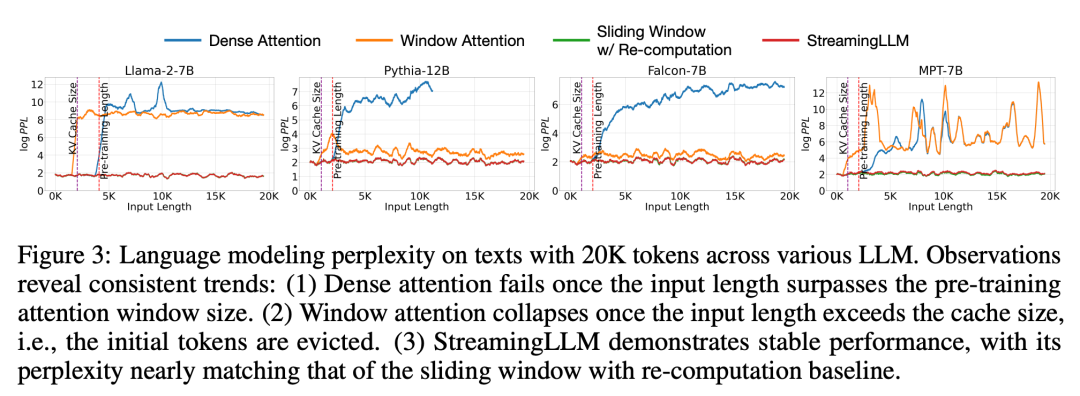
图 5 进一步证实了 StreamingLLM 可以可靠地处理非常规规模的文本,包括 400 多万个 token,涵盖了各种模型系列和规模。这包括 Llama-2-[7,13,70] B、Falcon-[7,40] B、Pythia-[2.8,6.9,12] B 和 MPT-[7,30] B。
随后,研究者证实了「注意力池」的假设,并证明语言模型可以通过预训练,在流式部署时只需要一个注意力池 token。具体来说,他们建议在所有训练样本的开头多加一个可学习的 token,作为指定的注意力池。通过从头开始预训练 1.6 亿个参数的语言模型,研究者证明了本文方法可以保持模型的性能。这与当前的语言模型形成了鲜明对比,后者需要重新引入多个初始 token 作为注意力池才能达到相同的性能水平。
最后,研究者将 StreamingLLM 的解码延迟和内存使用率与重新计算滑动窗口进行了比较,并使用 Llama-2-7B 和 Llama-2-13B 模型在单个英伟达 A6000 GPU 上进行了测试。如图 10 所示,随着缓存大小的增加,StreamingLLM 的解码速度呈线性增长。后者解码延迟则呈二次曲线上升。实验证明,StreamingLLM 实现了令人印象深刻的提速,每个 token 速度的提升高达 22.2 倍。




还没有评论,来说两句吧...