

2025 年 5 月的一篇论文中,何恺明与 CMU、MIT 联合团队提出了一种全新的一步生成框架 MeanFlow。
 图片
图片
论文标题是:《Mean Flows for One-step Generative Modeling》。从论文的实验曲线来看,只跑1 步,图像质量居然能甩开跑 250 步的老牌扩散模型(2021 年前后的经典扩散模型,如 ADM)。
这篇论文给一度陷入瓶颈的“一步生成”领域重新点燃了希望:作者们将传统 Flow Matching 中“瞬时速度”视角,替换成“平均速度”视角,一举把 ImageNet 256×256 的单次前向生成 FID 做到 3.43,较此前最佳 Shortcut-XL 的 10.60 提升近 70% 。
忍不住感叹:从 ResNet 到 Faster R-CNN,再到今天的 MeanFlow,何恺明这位「卷王」依旧在用最底层的思路改写上层玩法。
1.一条隐藏多年的“支流”
2015 年,GAN 让“自动造图”第一次进入公众视野,但训练不稳定,像一条湍急的河。2020 年,DDPM 把随机噪声反推回清晰图像,用上百步“蹚河”,稳,却慢。2023 年,Consistency Model 把河道分成十几段,研究员们开始想:能不能一步就上岸?
问题卡在“速度场”——以往 Flow Matching 追的是瞬时速度,像每一帧都按下快门;Consistency 强行让不同时间的输出对齐,训练要靠“小步→大步”。
平均流的灵感很朴素:真正决定终点的,是位移而不是瞬时速度。
论文用一道看似中学物理的恒等式把“平均速度—瞬时速度—时间导数”连在一起,给网络一个可微、闭合的目标。
回到连续动力系统视角,数据分布与先验噪声之间存在一条流场 v(z,t) (瞬时速度);而从时刻 r 走到 t 的平均速度可写为:
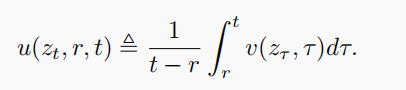 图片
图片
作者推导出一个MeanFlow 恒等式:
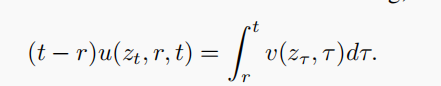 图片
图片
对等式两边关于 t 求导,并将 r视为与 t 无关的量,从而得到:
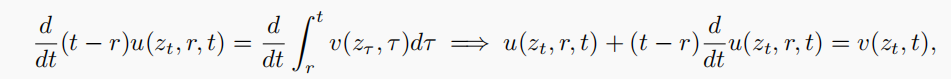 图片
图片
其中,左边的运算使用了乘积法则,而右边则运用了微积分基本定理。整理各项后,我们得到以下恒等式:
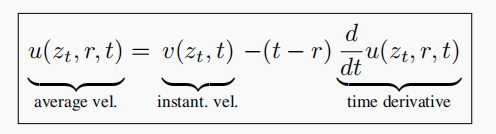 图片
图片
这条恒等式把可积分但难显式计算的平均速度,转换成了“瞬时速度 + 一阶导数”这样的可监督目标,从而摆脱了课程学习和蒸馏。于是, MeanFlow 在 ImageNet 256 × 256 上用 1-NFE 拿到 3.43 FID,直接把最佳记录砍掉近七成。
 图注:MeanFlow:训练流程
图注:MeanFlow:训练流程
2.为什么只改“一行公式”,就能把整条河道打直?
如果把 DDPM 的 250 步想象成在激流里踩 250 块石头,MeanFlow 的做法是:直接把河底拓平,然后告诉你水面在哪——一步就能蹚过去。这听上去像魔法,可推导其实就三件事:
第一,承认“平均速度”才是终点位移的真正代言人;第二,用那条中学物理恒等式,把平均速度拆解成“瞬时速度+一阶导数”;第三,把一阶导数塞进 Jacobian-vector-product,反向传播只比普通卷积慢 20%。
训练端多掏 20% 计算,推断端却省下 249 次前向。更妙的是,恒等式天生闭合,不需要 Consistency Model 那种“小步→大步”的课程学习,也省掉了蒸馏的大模型教师。网络一旦收敛,就等于把整条时间轴折叠进了权重里。
实验阶段,论文作者把 Base、Large、XL 三个尺寸统统跑了一遍:
Base/2 版只用 12 B 参数,1-NFE 就把 FID 打到 5.1,比同级的 Consistency 好一个身位;
换成 XL/2,跑 240 epoch 后,FID 滑到 3.43;
把 NFE 开到 2 并把训练拉满 1000 epoch,成绩甚至追平了 DiT-XL 在 250-step 时的 2.27。
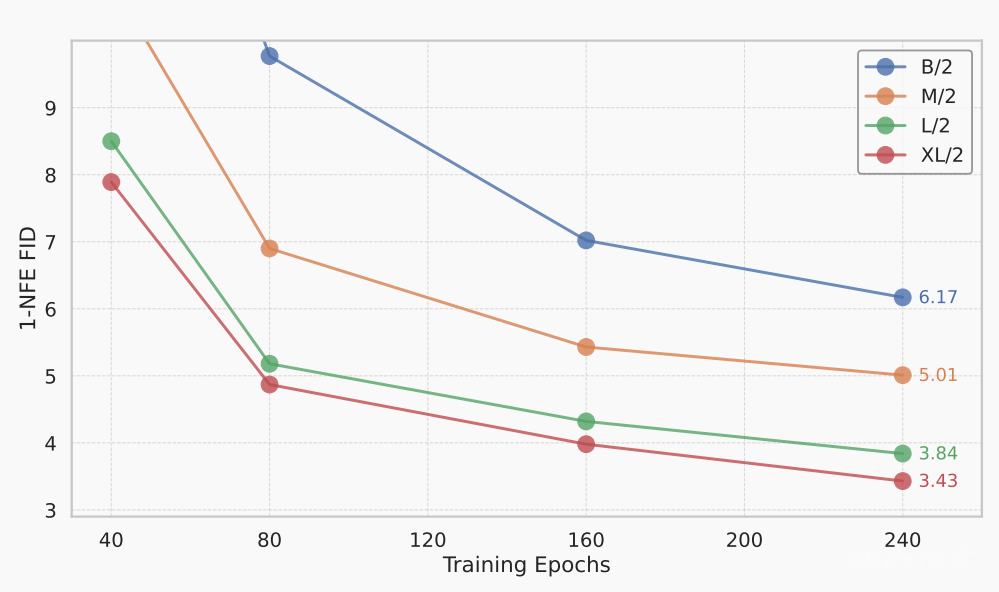 图注:MeanFlow模型在ImageNet 256×256数据集上的可扩展性表现。
图注:MeanFlow模型在ImageNet 256×256数据集上的可扩展性表现。
把文中的公开数据拉出来横向算一遍,会发现:在 1-NFE 场景里,把模型从 B/2 升级到 XL/2 往往比把同一尺寸的步数从 1 增加到 2 带来的收益更大;而长训版 XL/2+ 的 2-NFE FID 2.20 已经略低于 DiT-XL 在 250-step 时的 2.27。结论还不算板上钉钉,但至少说明:在端侧部署的硬算力预算里,“堆参数”有时比“堆步数”见效更快。
当然,MeanFlow 也没到“一统江湖”的时刻。最大的问题有三桩:
骨干挑食:论文全程抱着 DiT-style ViT 不放,UNet 在高分辨率下会不会“找不到河道”还没人验证;
轨迹弯曲:如果数据流形像阿尔卑斯山脉一样迂回,一步把山脉摊平成平原也许会扭曲细节,adaptive-NFE 该怎么做还是空白;
VAE 依赖:高分辨率生成目前得先把图像压进 latent,再解码回来,这条“先压后打”的管道仍旧是瓶颈。
但就像 2015 年没人敢想 GAN 能画 4K,2025 年的“一步生成”也刚刚发轫。平均速度这条支流,一旦被捅开,就很难再被堵回去。接下来你大概率会看到两股风潮:
一是 “快速物理”。气候模拟、湍流预测都在求一条从噪声到稳态的最短路径,MeanFlow 的数学骨骼天然契合;
二是 “巴掌模型”。有人已经在把平均速度塞进 LoRA、Adapter 里,试图用十几个 million 的参数卷出可商用的端侧版本。
论文:https://arxiv.org/abs/2505.13447https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html




还没有评论,来说两句吧...