

本文旨在提供一个全面且详细的DeepSeek本地部署指南,帮助大家在自己的设备上成功运行DeepSeek模型。无论你是AI领域的初学者还是经验丰富的开发者,都能通过本文的指导,轻松完成DeepSeek的本地部署。
一、本地部署的适用场景
每当有新的语言模型公开发布时,我总会忍不住拿它来做一些看似简单、实则暗藏难点的小测试。我把这当作给模型做“压力测试”,用来检验它们在逻辑推理上到底行不行。
DeepSeek R-1 刚发布不久,就因为它是开源、且推理能力强大而备受关注。基准测试显示,DeepSeek R-1 在很多场景下能与一些封闭的商业模型(比如 OpenAI 的 o1 或 Anthropic 的 Claude 3.5 Sonnet)相媲美,甚至表现更好。
既然 DeepSeek R-1 的推理能力如此被看好,我就想拿以下 5 个“刁钻”问题考考它,看看它能不能顺利通过:
“strawberry” 这个单词里有几个 “r”?
列出 5 个国家名称,其中在第 3 个字母位置出现“A”。
比较 9.9 和 9.11,哪个更大?
0.1 + 0.2 等于多少?
Alice 有四个兄弟,还另有一个姐妹。问:Alice 的兄弟共有几个姐妹?
一起来看看 DeepSeek R-1 的表现如何!
1. “strawberry” 里有几个字母 “r”?
当初我测 OpenAI 的早期模型(比如 GPT-4o)时,发现它在这种简单的字母计数问题上有时会出错。乍一看,这类问题对 AI 来说应该很容易,但 AI 有时就是会犯一些莫名其妙的错误。
我把同样的问题抛给了 DeepSeek R-1,结果它的回答是正确的:单词 “strawberry” 一共包含 3 个 “r”。虽然题目很简单,但能体现出模型对最基本的模式识别和文本处理是否扎实。
下面是deepseek的回答:

2. 列出 5 个国家,名字中第 3 个字母是 “A”
很多模型在这个问题上会阴沟翻船。比如,我之前用 GPT-4o 和 o1 的早期版本,得到的回答里常出现 “Japan” 这类不符合要求的国家,因为它们忽略了第 3 个字母实际是 “p” 而非 “a”。
测试 DeepSeek R-1 后,它轻松列出了 5 个符合条件的国家,没有出错。值得一提的是,我后面又用最新版本的 o1(通过 ChatGPT)做同样的测试,这次它也答对了,可见不断更新的模型在修复之前的错误。
下面是 DeepSeek的回答:

3. 谁更大:9.9 还是 9.11?
这是另一个看似简单、却能让早期 GPT-4 版本“跌倒”的题目。很多人看到 9.9 和 9.11 可能会下意识被小数点后位数误导,尤其对于某些模型而言,它们初期不擅长处理这类数字比较的问题。
DeepSeek R-1 在这个问题上表现不错,给出了正确答案,并且还详细解释了为什么 9.11 小于 9.9(从数值大小比较,而不是把它当做日期或版本号对比)。它甚至给出了一些示例,帮助你理解数值排序的原理。

4. 0.1 + 0.2 等于多少?
别小看这道加法题,不少 AI 模型都曾在这里犯错。浮点数在计算机内部的二进制表示并不精确,常常会出现 0.30000000000000004 之类的“经典错误”。
我用这个问题考 DeepSeek R-1,它给出的答案是 0.3,并没有出现那些多余的浮点尾数。对于那些老是回答 0.30000000000000004 的模型来说,这道题是考察它们是否能识别并处理计算机浮点误差的好方法。
为什么会出现 0.30000000000000004?
因为 0.1 和 0.2 在计算机中的二进制形式都无法精准表示,二者相加后再转换回十进制,就会多出一点小误差。

5. Alice 有四个兄弟,还有一个姐妹。Alice 的兄弟共有几个姐妹?
很多人第一反应都是:Alice 自己就是一个姐妹?再加上另一个姐妹?于是结果是兄弟们有 2 个姐妹。但有些模型就会漏算,可能只算成 1 个姐妹。
DeepSeek R-1 给出的结论是正确的:每个兄弟都有 2 个姐妹(Alice 和那位额外的姐妹)。更有意思的是,DeepSeek R-1 还展示了它的推理过程,先理清家庭成员,再总结兄弟所拥有的姐妹数量。曾经 GPT-4o 之类的模型也可能在这种地方掉链子。
当然,目前 o1 配备了更好的推理能力,也可以答对,但这更说明在某些场景下,必须让 AI 做“多步逻辑推理”来得到正确答案。

总结
DeepSeek R-1 在这 5 道小测试里都表现得非常出色,能给出正确答案并提供了清晰的解释。从这些小测试可以看出,它确实具备一定的深层思考与推理能力。尽管它还无法宣称要全面取代更成熟的商业大模型(像 o1 或 Claude 3.5),但这次测试结果证明它确实是个强有力的竞争者。
对那些在乎成本或喜欢开源方案的人来说,DeepSeek R-1 是个非常值得关注的模型,它用较低成本就能提供不错的推理性能。
如果你也想测测自己最常用的聊天机器人或语言模型,不妨尝试以上 5 个问题,看它们是不是能准确回答。或者,如果你还有更多让 AI 容易出错的题目,欢迎在评论里分享,让我们一起看看这些模型到底能走多远!
DeepSeek本地部署适合以下场景:
高性能硬件配置:如果你的电脑配置较高,特别是拥有独立显卡和足够的存储空间,那么本地部署将能充分利用这些硬件资源。
数据安全需求:对于需要处理敏感数据的用户,本地部署可以避免数据上传至云端,确保数据的安全性和隐私性。
高频任务处理:对于需要频繁处理大量或复杂任务的用户,本地部署能提供更高的灵活性和响应速度。
成本控制:对于日常使用量大、API调用费用较高的用户,本地部署能显著降低运行成本。
个性化需求:本地部署允许用户对模型进行二次开发和定制,满足特定的应用场景和需求。
三、环境准备与依赖安装
1. 硬件要求
操作系统:推荐Linux(如Ubuntu 20.04及以上版本)或Windows系统。
Python版本:需要安装Python 3.8及以上版本。
GPU支持:需要支持CUDA的NVIDIA GPU,推荐显存16GB及以上。
2.硬件配置
模型 | 显存需求 | 内存需求 | 推荐显卡 |
7B | 10-12GB | 16GB | RTX 3060 |
14B | 20-24GB | 32GB | RTX 3090 |
32B | 40-48GB | 64GB | RTX 4090 |
2. 软件依赖
CUDA与CUDNN:根据NVIDIA GPU型号和驱动版本,安装合适的CUDA(11.2及以上版本)和CUDNN(8.1及以上版本)。
3. 安装步骤
更新系统(Linux为例)
安装必要依赖
创建并激活虚拟环境
安装PyTorch
根据CUDA版本选择合适的PyTorch安装命令。例如,CUDA 11.2的安装命令如下:
四、DeepSeek模型下载与部署
1. 克隆DeepSeek代码库
2. 安装项目依赖
3. 下载并放置预训练模型
从官方提供的链接下载DeepSeek预训练模型权重,并将其放置在models/目录下。
4. 配置环境变量
设置模型路径和GPU设备号等环境变量
5. 运行模型
使用以下命令启动DeepSeek模型进行推理或训练。
五、简化部署方案:使用Ollama
对于初学者或不希望手动配置环境的用户,可以使用Ollama工具简化DeepSeek的本地部署过程。
1.下载安装Ollama
在本地部署DeepSeek会使用到Ollama,所以,需要现在本地下载安装Ollama。
Ollama官方地址:https://ollama.com
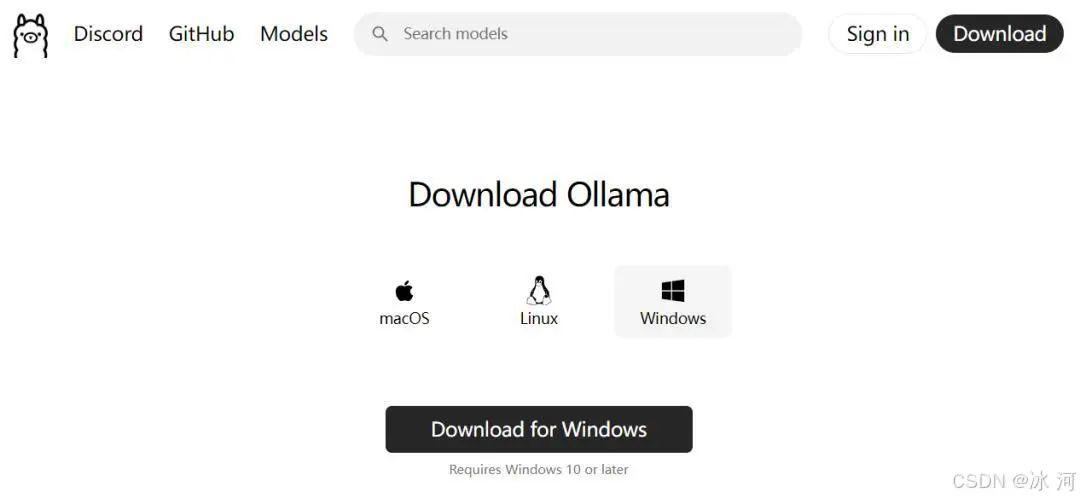
小伙伴们可以根据自己的需要下载MacOS、Linux和Windows版本的Ollama,由于冰河目前使用的是Windows系统,所以,这里我下载的是Windows版本的Ollama。
下载后在本地安装Ollama。
2.下载DeepSeek-R1
(1)定位Models
进入Ollama官网,找到Models。

(2)找到DeepSeek-R1模型
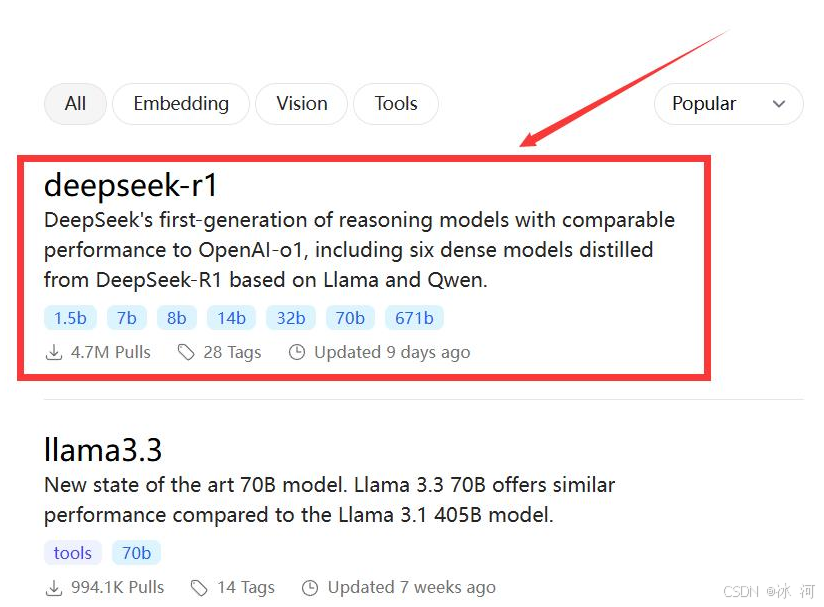
(3)选择对应的模型下载
DeepSeek-R1有很多不同的版本可供下载,例如1.5b、7b、8b、14b、32b、70b或671b,版本越高,模型越大,对于电脑的内存、显卡等资源的配置要求就越高。
这里为了方便安装演示,我先给大家演示如何部署8b的模型。后续带着大家在服务上部署更高版本的模型。
进入DeepSeek-R1模型的详情,选择8b模型,如下所示。
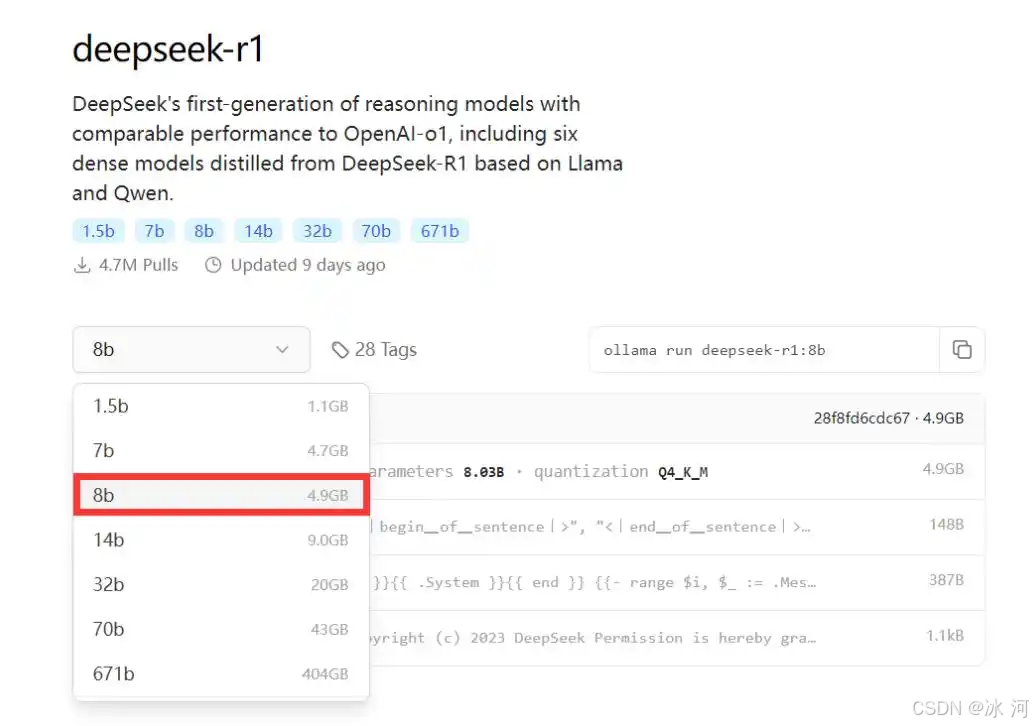
(4)打开电脑终端
以管理员身份打开电脑终端,如下所示。
(5)部署8b模型
首先,如下图所示复制8b模型的代码。
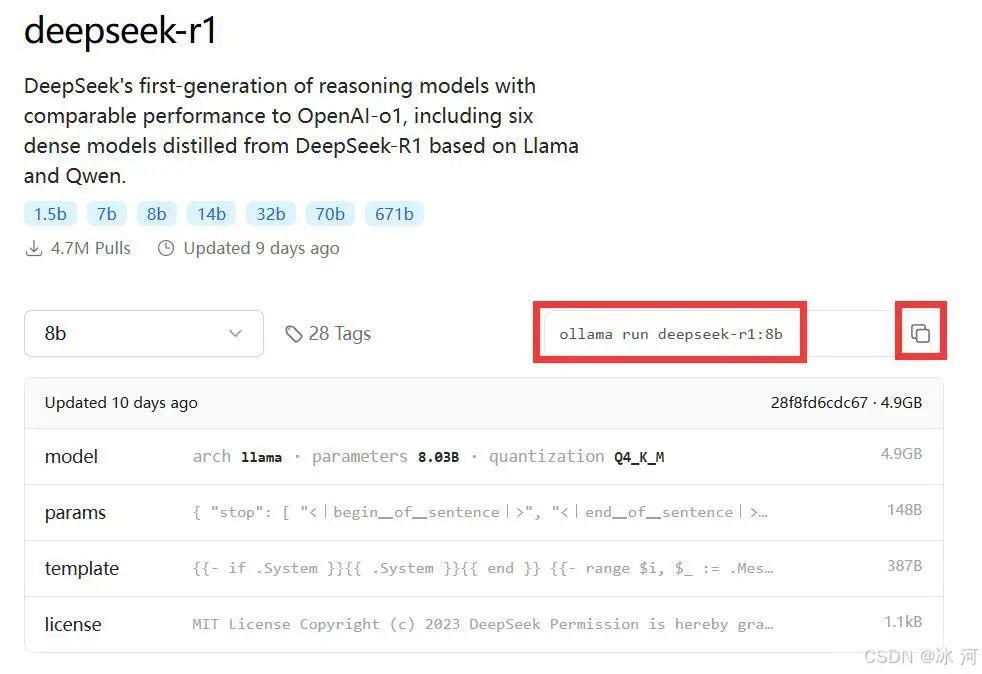
随后,将其粘贴到命令行终端,如下所示。
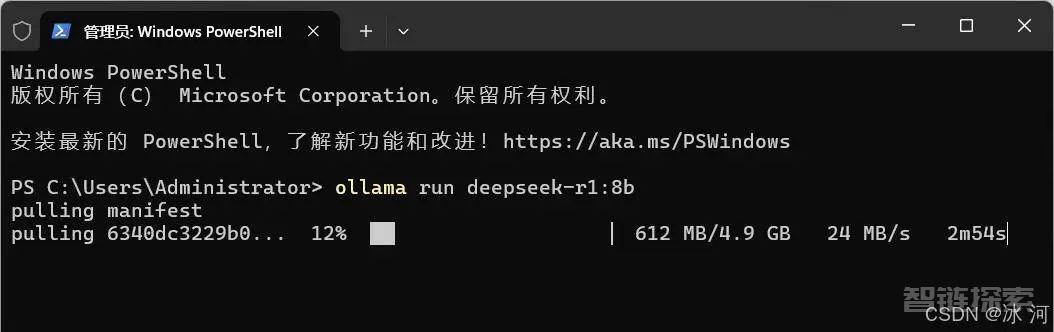
如果出现下图所示的进度,则说明正在下载模型。
等待一段时间,如果出现success字样,则说明部署成功,如下所示。
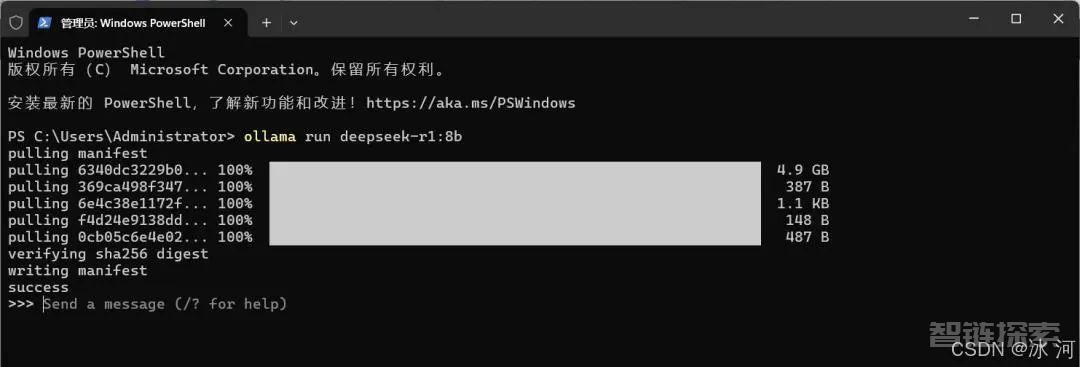
部署成功后,我们可以试着在命令行发送一条消息给DeepSeek,这里我发送一个“你好”给DeepSeek。
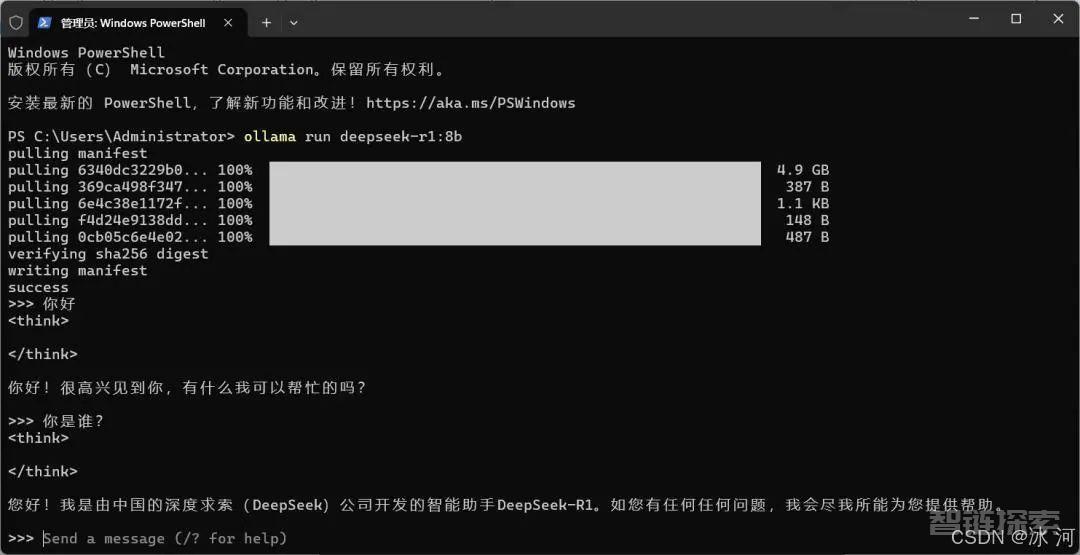
可以看到,向DeepSeek发送你好后,它也回复了一段内容。
至此,我们就可以和DeepSeek在命令行进行对话了。不过,只是在命令行与DeepSeek对话,那就显得有点不怎么方便了,所以,我们继续部署Chatbox。
3.安装Chatbox
通过部署Chatbox,我们可以使用在网页或者客户端与DeepSeek进行交互。Chatbox的安装步骤如下所示。
(1)下载安装Chatbox
Chatbox官网:https://chatboxai.app/zh
直接进入官网下载客户端,如下所示。
下载完成后,双击进行安装即可。
(2)配置DeepSeek-R1模型
打开Chatbox,选择设置—>Ollama API,如下所示。
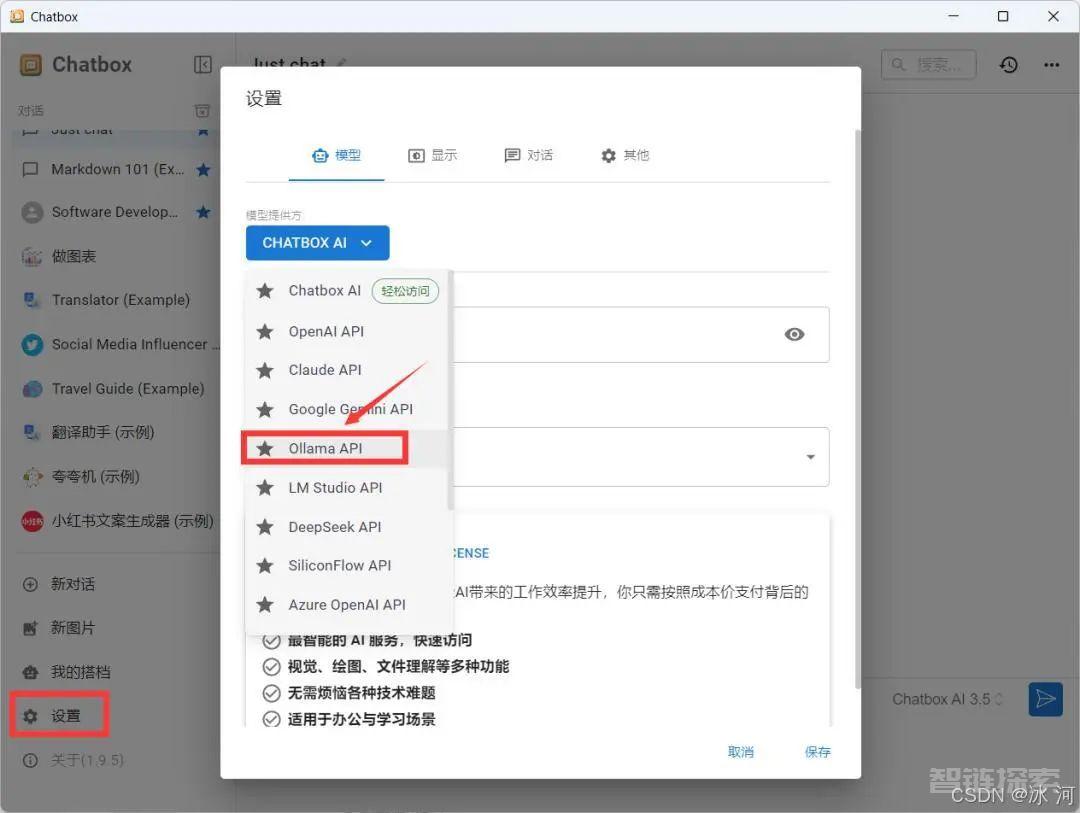
选择已经安装好的DeepSeek-R1 8b模型,进行保存。
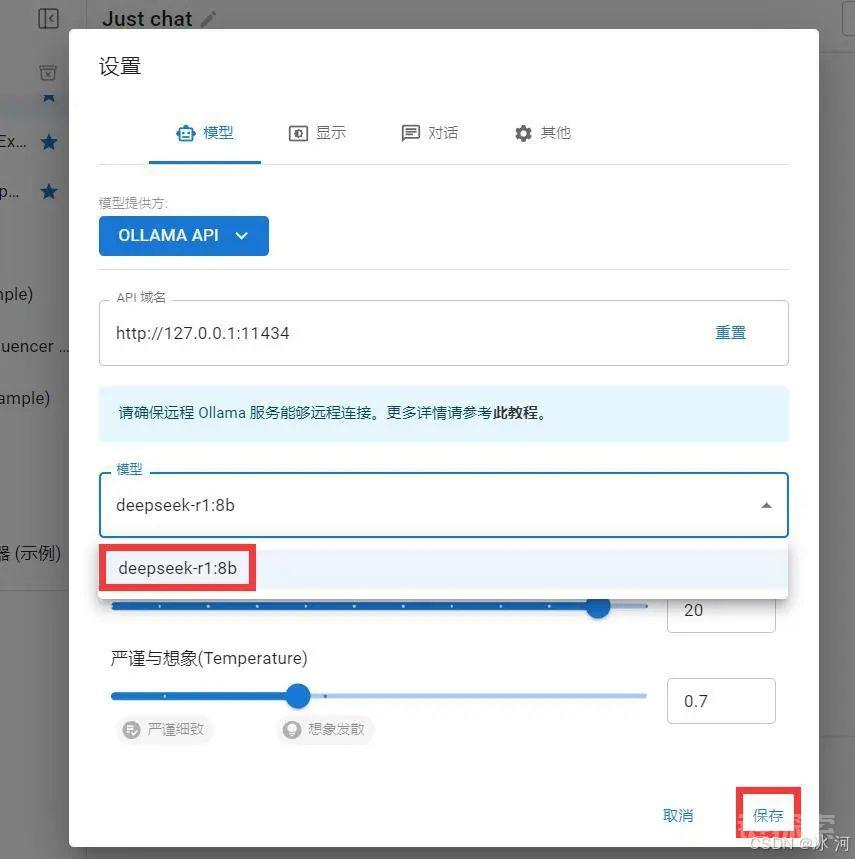
等待部署完成,就可以在Chatbox页面中与DeepSeek进行对话了。
六、安装Open-WebUI
1.安装Docker
安装Open-WebUI前,我们可以先安装Docker。进入Docker官网:https://www.docker.com,下载Docker。
下载后安装到自己电脑即可。
2.安装open-webui
如果是在Linux系统下,则可以打开命令行,输入以下命令安装 Open-WebUI。
安装完成后,打开浏览器,访问 http://localhost:3000,注册一个账号并登录,即可进入open-webui。
在界面左上角选择对应的模型,即可开始对话。
如果是Windows系统,则在浏览器搜索Open-WebUI,进入官网,并复制下图所示的命令。
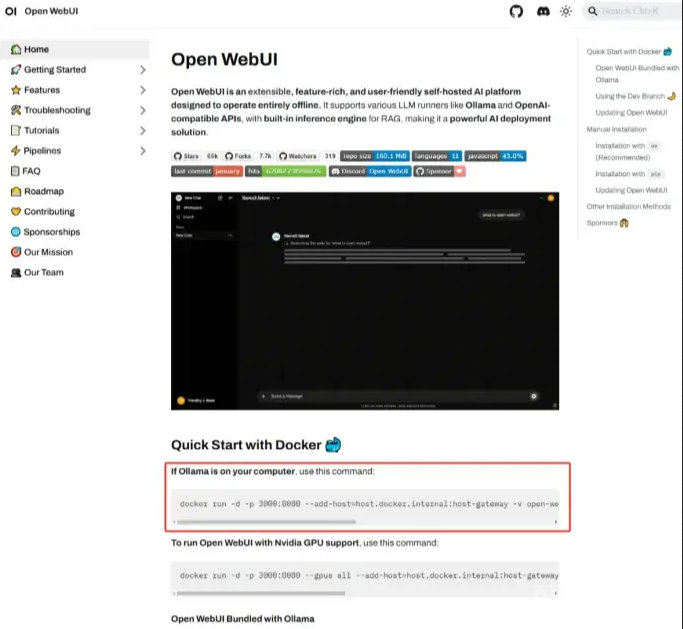
随后打开Windows命令行,输入复制的命令后等待安装完成。
安装完成后,打开浏览器,访问 http://localhost:3000,注册一个账号并登录,即可进入open-webui。
七、常见问题解决方案
问题现象 | 解决方案 |
显存不足报错 | 使用量化模型或换用更小模型 |
响应速度慢 | 设置环境变量 |
生成内容中断 | 输入 |
中文输出夹杂英文 | 在提问末尾添加「请使用纯中文回答」 |
历史记忆混乱 | 输入 |




还没有评论,来说两句吧...