

摘要
本文介绍了OpenAI的最新进展,重点关注其在多模态技术领域的突破。文章首先探讨了GPT-4 Turbo模型的优化和多模态功能的融合,如图像生成和文本到语音转换。随后,作者深入解析多模态技术的工作原理,特别是文本到图像的转换过程。通过实际应用和编程实例,展示了如何利用这些技术对图像和视频内容进行识别,以及将识别内容转换为语音,体现了多模态技术在实际应用中的广泛潜力和影响力。
开篇
OpenAI最近在其平台上宣布了一系列引人注目的新增和改进功能,这些更新旨在进一步推动人工智能的边界扩展。这些更新不仅包括了性能更强大且成本更低的新型GPT-4 Turbo模型,而且还引入了多模态能力,这将极大地扩展开发者和研究人员的创新空间。以下是这些更新的要点:
1.GPT-4 Turbo模型:这个新模型代表了大规模语言模型的最新进展。它不仅性能更强大,而且价格更亲民。这一模型支持高达128K的上下文窗口,意味着可以处理更长的对话和文本。GPT-4 Turbo的出现,显著提升了开发者利用大型语言模型潜能的能力,让模型成为了一个真正的“全才”。
2.多模态功能:在多模态领域的最新进展尤为引人注目。OpenAI平台上的新功能包括了视觉能力的提升、图像创造(DALL·E 3)以及文本到语音(TTS)技术。这些多模态功能的结合不仅开启了新的应用场景,还为用户提供了一个更加丰富和互动的体验。
3.助手API(Assistants API):OpenAI新推出的助手API让开发者更加便捷地构建目标明确的AI应用。这个API提供了调用模型和工具的简化方式,从而使开发复杂的辅助性AI应用成为可能,无论是为了业务流程自动化,还是为了增强用户体验。
看到这些功能的加入,让人热血澎湃,我迫不及待地登陆GPT尝鲜这些功能。特别是多模态的功能让我印象深刻,这里我将实践操作以及代码的分析与大家做一个分享。
多模态初探
多模态技术是一个日益流行的领域,它结合了不同类型的数据输入和输出,如文本、声音、图像和视频,以创造更丰富、更直观的用户体验。以下是多模态技术的几个关键方面:
1.综合多种感知模式:多模态技术整合了视觉(图像、视频)、听觉(语音、音频)、触觉等多种感知模式。这种集成使得AI系统能够更好地理解和解释复杂的环境和情境。
2.增强的用户交互:通过结合文本、图像和声音,多模态技术提供了更自然、更直观的用户交互方式。例如,用户可以通过语音命令询问问题,同时接收图像和文本形式的答案。
3.上下文感知能力:多模态系统能够分析和理解不同类型数据之间的关系,从而提供更准确的信息和响应。例如,在处理自然语言查询时,系统能够考虑相关的图像或视频内容,从而提供更为丰富的回答。
4.创新应用:多模态技术的应用范围广泛,包括但不限于自动化客服、智能助手、内容创作、教育、医疗和零售等领域。它允许创建新型的应用程序,这些应用程序能够更好地理解和响应用户的需求。
5.技术挑战:虽然多模态技术提供了巨大的潜力,但它也带来了诸如数据融合、处理不同数据类型的复杂性以及确保准确性和效率的挑战。
6. OpenAI的多模态实例:在OpenAI的框架下,多模态功能的一个显著例子是DALL·E 3,它是一个先进的图像生成模型,可以根据文本描述创建详细和创造性的图像。此外,文本到语音(TTS)技术则将文本转换为自然 sounding的语音,进一步丰富了人机交互的可能性。
多模态原理解析
前面我们对多模态进行了基本的描述,多模态是指能够理解和处理多种类型数据(如文本、图像、声音等)的技术。实现文本-图片-声音-视频之间的转换。转化是表象,实质需要理解。
在人工智能领域,多模态方法通常结合了自然语言处理(NLP)、计算机视觉(CV)和其他信号处理技术,以实现更全面的数据理解和处理能力。
为了说明多模态的工作原理,我们这里举一个从文字转图片的例子,帮助大家理解。我们将整个过程展示如下:
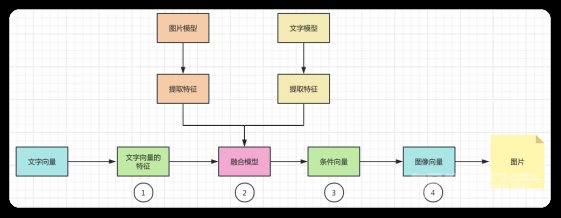
1. 文本特征提取:
首先,文本输入通过一个文本模型(例如一个预训练的语言模型)来提取文本特征。这个过程涉及将文本转换成一个高维空间的向量,这个向量能够表示文本的语义内容。
2. 融合模型:
在某些情况下,确实会存在一个专门的融合模型,它是在训练阶段通过学习如何结合不同模态的数据而得到的。这个融合模型将在推理阶段使用。
在其他情况下,融合模型可能是隐含的。例如,在条件生成模型中,文本特征向量直接用作生成图像的条件,而不需要显式的融合步骤。
3.条件生成:
融合模型(或者直接从文本模型得到的特征向量)用于为图像生成模型设定条件。这个条件可以理解为指导生成模型“理解”文本内容,并据此生成匹配的图像。
4.图像生成:
最后,图像生成模型(如DALL·E或其他基于生成对抗网络的模型)接收这个条件向量,并生成与之相匹配的图像。这个过程通常涉及到大量的内部计算,模型会尝试生成与条件最匹配的图像输出。
整个流程可以简化为:文本输入 → 文本特征提取 → 特征融合(如果有)→ 条件生成 → 图像输出。在这个过程中,“融合模型”可能是一个独立的模型,也可能是条件生成模型的一部分。关键点是,推理时的特征融合是基于在训练阶段学到的知识和参数进行的。
多模型体验
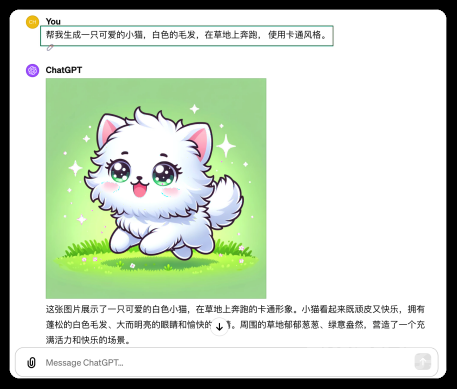
了解了多模型实现原理之后,我们来登陆ChatGPT体验一下,现在在ChatGPT4中已经集成了DALLE 3 的功能,我们只需要输入指令就可以生成对应的图片。如下所示,我们通过文字描述一只可爱的猫咪,ChatGPT 就能够帮我完成图片的生成。
不止于此,OpenAI还能够识别图片,当你提供图片之后,OpenAI会根据图片描述其中的内容,如下图我们从网络上找到一张小猫的图片,丢给OpenAI让它识别一下。

这次我们通过调用OpenAI的API,来实现上述功能。毕竟作为程序员不敲敲代码,只是用工具输入文字还是不太过瘾。
这段代码使用 Python 和 OpenAI 库来与 OpenAI 的 GPT-4 API 交互。目的是创建一个聊天会话,其中用户可以向模型发送图像地址。代码通过URL地址,读取图像并且对其进行识别,最终输出理解的文字。
虽然代码比较简单,我们这里还是解释一下。
导入库:代码首先导入 os 和 openai。os 库用于读取环境变量中的 API 密钥,而 openai 库用于执行与 OpenAI API 的交互。
创建聊天请求:
Model:指定了要使用的 OpenAI 模型为 "gpt-4-vision-preview",这个版本的大模型具备处理图像的能力。
Messages:这是一个字典列表,模拟了用户与 AI 聊天的过程。在这个例子中,用户通过文本询问一张图片的含义,并提供了图片的 URL。
max_tokens:定义了模型回答的最大长度,这里设置为 200 tokens。
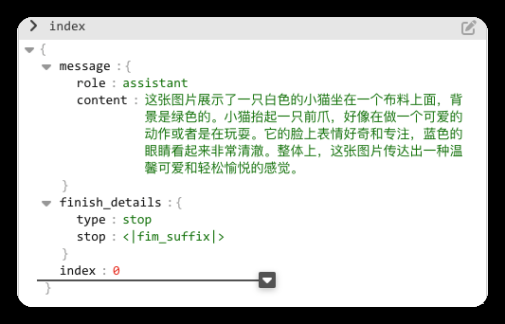
执行之后,结果是一段JSON文本,我们使用编辑器打开,如下图所示,程序识别出图片的内容,是一只白色的小猫,并且对动作和表情都进行了精确的描述。
从识别图片到识别视频
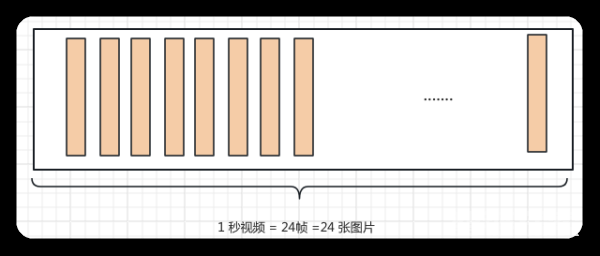
实际上OpenAI这次提供的功能不只是对图片的识别,还可以对其进行扩展,将对图片识别的能力推广到视频上。如下图所示,假设一段1秒钟的视频是由24帧图片组成,如果我们能够将每张图片进行识别,并且将识别的信息进行总结生成摘要是不是就可以对视频进行识别了呢?
这个想法不错,但是需要通过实践去验证,我们使用一段代码加入早已准备好的视频,通过OpenCV组件加载视频,并且对视频的内容进行读取。将读取之后的视频内容,分成一帧一帧的图片,通过对图片的识别达到对视频识别的目的。
代码如下:
1.导入组件库
当然,我会按照您的要求调整代码注释的位置,使其位于相关代码行的上方。
视频处理
打开一个视频文件("the-sea.mp4"),读取其中的每一帧,并将这些帧转换成 JPEG 格式后编码为 base64 字符串。这种处理方式在需要以文本格式存储或传输图像数据的场景中非常有用,如在网络通信中发送图像数据。
导入和初始化:首先导入所需的 OpenCV 库,并创建一个空列表 base64Frames 用于存储编码后的帧。
读取视频帧:通过 while 循环和 video.read() 方法逐帧读取视频。如果读取成功,将帧编码为 JPEG 格式,然后将这些 JPEG 格式的帧转换为 base64 编码,并添加到列表中。
资源管理和输出:循环结束后,使用 video.release() 释放视频文件,随后打印出读取的帧数,作为处理的结果。这提供了对视频内容处理情况的直观了解。
显示视频帧
遍历一个包含 base64 编码的图像帧列表,连续显示这些帧,从而实现视频播放的效果。
初始化显示句柄:首先创建一个 display_handle,它是一个可以更新的显示对象。这样做可以在之后循环中更新显示的图像,而不是创建新的图像显示。
遍历和显示图像帧:使用 for 循环遍历 base64Frames 列表中的每一个 base64 编码的图像帧。在循环内部,使用 display_handle.update() 方法来更新当前显示的图像。这里涉及将 base64 编码的字符串解码为二进制数据,并使用 Image 对象将其转换为可显示的图像。
控制播放速度:在每次更新图像后,使用 time.sleep(0.025) 来暂停一段时间(0.025秒),这样可以在图像帧之间创建短暂的延迟,使得连续播放的视频效果更加平滑。
查看视频效果如下,我们截取了视频中的一张图片,可以看出是一段描述海上日落的视频。

识别视频内容
使用 OpenAI 的 API 来描述一个视频帧的内容。首先设置请求的参数,包括模型、API 密钥、请求的提示信息,然后调用 API 并打印返回的内容。
设置提示信息:PROMPT_MESSAGES 包含了 API 请求的核心信息,其中包括用户角色标记和要处理的内容。这里的内容是请求模型描述视频帧的内容,视频帧作为 base64 编码的字符串传入。
配置 API 调用参数:在 params 字典中配置了 API 调用所需的所有参数,包括模型名称、提示信息、API 密钥、API 版本和请求的最大令牌数。
发起 API 调用:使用 openai.ChatCompletion.create 方法发起 API 调用,传入之前配置的参数。这个调用将请求模型根据提供的视频帧内容进行描述。
输出结果:最后,打印出 API 返回的结果,即模型对视频帧内容的描述。
展示最终结果,如下:
看来OpenAI不仅描绘了视频中的画面,还对其的内涵进行了引申,这是要赶超人类的节奏了。
从识别内容到语音播报
好了到现在,我们已经完成了从图片到文字,视频到文字的转换了。假设我们要将视频上传到网站时,并且对视频进行解释,此时不仅需要文字更需要一段专业的语音播报。好吧!我是想展示下面的功能,如何将视频识别的文字转化成语音播报。
下面这段代码使用 Python 和 OpenAI 的语音合成 API 来将文本转换为语音,即将视频生成的文本(描述日落景象的文本)转换成语音。然后,它接收并汇总响应中的音频数据,并使用 Audio 对象来播放这段音频。
准备和发起请求:首先导入所需的库,并准备发起一个 POST 请求到 OpenAI 的语音合成 API。请求头部包含了 API 密钥(从环境变量获取),请求体包含了模型名称、要转换的文本内容以及语音类型。
接收音频数据:从 API 响应中逐块读取音频数据。这里使用了 1 MB 作为每个数据块的大小限制。通过循环,将这些数据块累加到一个字节串 audio 中。
播放音频:最后,使用 Audio 对象来播放累积的音频数据。这允许在 Jupyter Notebook 环境中直接播放音频。
音频结果如下:
大家可以尝试上面的代码,生成自己的语音文件。
总结
文章通过详尽地探讨OpenAI的多模态功能,展示了人工智能领域的最新进展。从GPT-4 Turbo模型的介绍到多模态技术的应用实例,不仅提供了技术的理论背景,还通过具体的代码示例,展现了如何将这些技术实际应用于图像生成、视频内容识别和语音转换。这不仅彰显了AI技术的前沿动向,也为读者提供了实践AI技术的洞见和启发。




还没有评论,来说两句吧...