create_prompt <- function(schema, rows_sample, query, table_name) {
glue::glue("Act as if you're a data scientist. You have a SQLite table named {table_name} with the following schema:
```
{schema} ```
The first rows look like this:
```{rows_sample}```
Based on this data, write a SQL query to answer the following question: {query}. Return the SQL query ONLY. Do not include any additional explanation.")}1.2.3.4.5.6.7.8.9.10.11.12.13.
> my_query <- "What were the highest and lowest Population changes in 2020 by Division?"> my_prompt <- get_query(states_schema_string, states_sample_string, my_query, "states")> cat(my_prompt)Act as if you're a data scientist. You have a SQLite table named states with the following schema:
```0 State TEXT 0 NA 0
1 Pop_2000 INTEGER 0 NA 0
2 Pop_2010 INTEGER 0 NA 0
3 Pop_2020 INTEGER 0 NA 0
4 PctChange_2000 REAL 0 NA 0
5 PctChange_2010 REAL 0 NA 0
6 PctChange_2020 REAL 0 NA 0
7 State Code TEXT 0 NA 0
8 Region TEXT 0 NA 0
9 Division TEXT 0 NA 0```The first rows look like this: ```Delaware 783600 897934 989948 17.6 14.6 10.2 DE South South Atlantic
Montana 902195 989415 1084225 12.9 9.7 9.6 MT West Mountain
Arizona 5130632 6392017 7151502 40.0 24.6 11.9 AZ West Mountain```Based on this data, write a SQL query to answer the following question: What were the highest and lowest Population changes in 2020 by Division?. Return the SQL query ONLY. Do not include any additional explanation.1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.
提示输入OpenAI API playground和生成的SQL代码
以下是运行建议的SQL时的结果:
sqldf("SELECT Division, MAX(PctChange_2020) AS Highest_PctChange_2020, MIN(PctChange_2020) AS Lowest_PctChange_2020 FROM states GROUP BY Division;")
Division Highest_PctChange_2020 Lowest_PctChange_20201 East North Central 4.7 -0.12 East South Central 8.9 -0.23 Middle Atlantic 5.7 2.44 Mountain 18.4 2.35 New England 7.4 0.96 Pacific 14.6 3.37 South Atlantic 14.6 -3.28 West North Central 15.8 2.89 West South Central 15.9 2.71.2.3.4.5.6.7.8.9.10.11.
library(openai)my_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list(
list(role = "user", content = my_prompt))) the_answer <- my_results$choices$message.contentcat(the_answer)SELECT Division, MAX(PctChange_2020) AS Highest_Population_Change, MIN(PctChange_2020) AS Lowest_Population_ChangeFROM statesGROUP BY Division;sqldf(the_answer)
Division Highest_Population_Change Lowest_Population_Change1 East North Central 4.7 -0.12 East South Central 8.9 -0.23 Middle Atlantic 5.7 2.44 Mountain 18.4 2.35 New England 7.4 0.96 Pacific 14.6 3.37 South Atlantic 14.6 -3.28 West North Central 15.8 2.89 West South Central 15.9 1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.
library(shiny)library(openai)library(dplyr)library(sqldf)# Load hard-coded dataset
states <- read.csv("states.csv") |>
dplyr::filter(!is.na(Region) & Region != "")states_schema <- sqldf::sqldf("PRAGMA table_info(states)")states_schema_string <- paste(apply(states_schema, 1, paste, collapse = "\t"), collapse = "\n")states_sample <- dplyr::sample_n(states, 3)states_sample_string <- paste(apply(states_sample, 1, paste, collapse = "\t"), collapse = "\n")# Function to process user input
get_prompt <- function(query, schema = states_schema_string, rows_sample = states_sample_string, table_name = "states") {
my_prompt <- glue::glue("Act as if you're a data scientist. You have a SQLite table named {table_name} with the following schema:
```
{schema} ```
The first rows look like this:
```{rows_sample}```
Based on this data, write a SQL query to answer the following question: {query} Return the SQL query ONLY. Do not include any additional explanation.")
print(my_prompt)
return(my_prompt)}ui <- fluidPage(
titlePanel("Query state database"),
sidebarLayout(
sidebarPanel(
textInput("query", "Enter your query", placeholder = "e.g., What is the total 2020 population by Region?"),
actionButton("submit_btn", "Submit")
),
mainPanel(
uiOutput("the_sql"),
br(),
br(),
verbatimTextOutput("results")
)
))server <- function(input, output) {# Create the prompt from the user query to send to GPT
the_prompt <- eventReactive(input$submit_btn, {
req(input$query, states_schema_string, states_sample_string)
my_prompt <- get_prompt(query = input$query)
}) # send prompt to GPT, get SQL, run SQL, print resultsobserveEvent(input$submit_btn, {
req(the_prompt()) # text to send to GPT
# Send results to GPT and get response
# withProgress adds a Shiny progress bar. Commas now needed after each statement withProgress(message = 'Getting results from GPT', value = 0, { # Add Shiny progress message
my_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list(
list(role = "user", content = the_prompt())
))
the_gpt_sql <- my_results$choices$message.content
# print the SQL
sql_html <- gsub("\n", "<br />", the_gpt_sql)
sql_html <- paste0("<p>", sql_html, "</p>")
# Run SQL on data to get results
gpt_answer <- sqldf(the_gpt_sql)
setProgress(value = 1, message = 'GPT results received') # Send msg to user that
})
# Print SQL and results
output$the_sql <- renderUI(HTML(sql_html))
if (is.vector(gpt_answer) ) {
output$results <- renderPrint(gpt_answer)
} else {
output$results <- renderPrint({ print(gpt_answer) })
} }) }shinyApp(ui = ui, server = server)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.



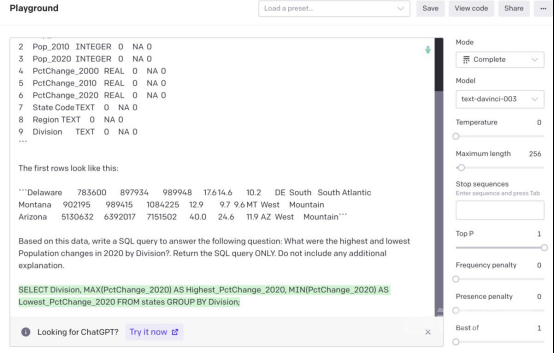 提示输入OpenAI API playground和生成的SQL代码
提示输入OpenAI API playground和生成的SQL代码



还没有评论,来说两句吧...