


1、写在前面
官方开源的版本除了满血的 671b 外,还有 1.5b,7b,8b,14b,32b,70b 六个蒸馏后的尺寸,笔者使用 Ollama 在电脑本地部署了 7b 的模型,在终端中测试了虽然回答没有满血版的那么惊艳,但凑活能用。
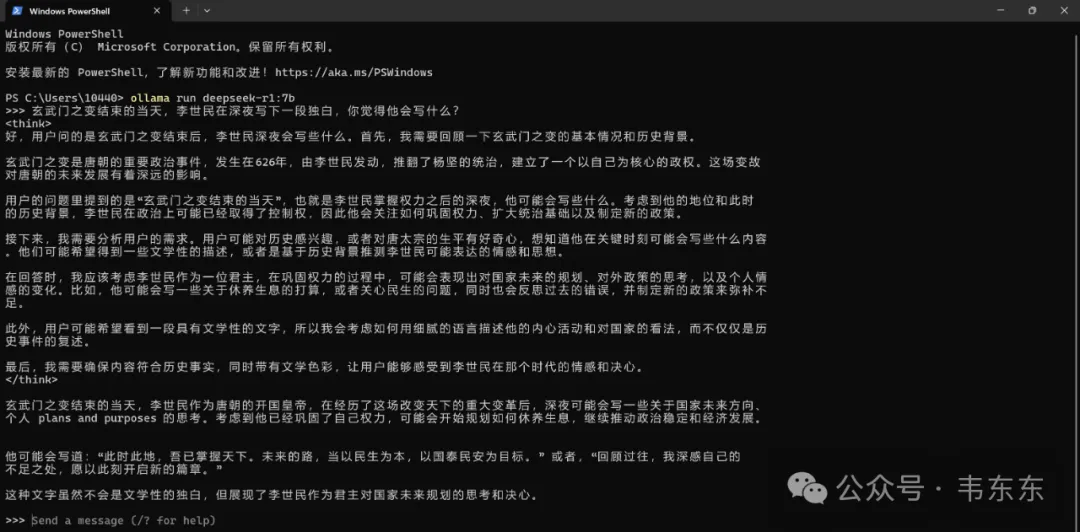
作为一款高阶模型开源,确实要 salute 一下。不过进一步的问题是,我们面对这样的强思维链模型,除了在官网间或 Chat 一下,如何进一步的将其变成工作或生活场景的生产力工具?本篇试图给出一种基于RAG的回答。
2、场景分析
本篇主要介绍一个本地RAG问答系统的简要示例,项目已开源在github。
适合对数据隐私和安全性要求高的场景,如医疗机构处理病历档案、金融企业分析内部报告、法律部门管理合同文书,以及希望在确保数据不出企业的前提下实现智能问答的个人或者企业。可以在完全离线环境下独立部署和使用。
🔒 私有数据安全:全程本地处理,敏感文档无需上传第三方服务
⚡ 实时响应:基于本地向量数据库实现毫秒级语义检索
💡 领域适配:可针对专业领域文档定制知识库
🌐 离线可用:无需互联网连接,保护数据隐私
💰 成本可控:避免云服务按次计费,长期使用成本更低
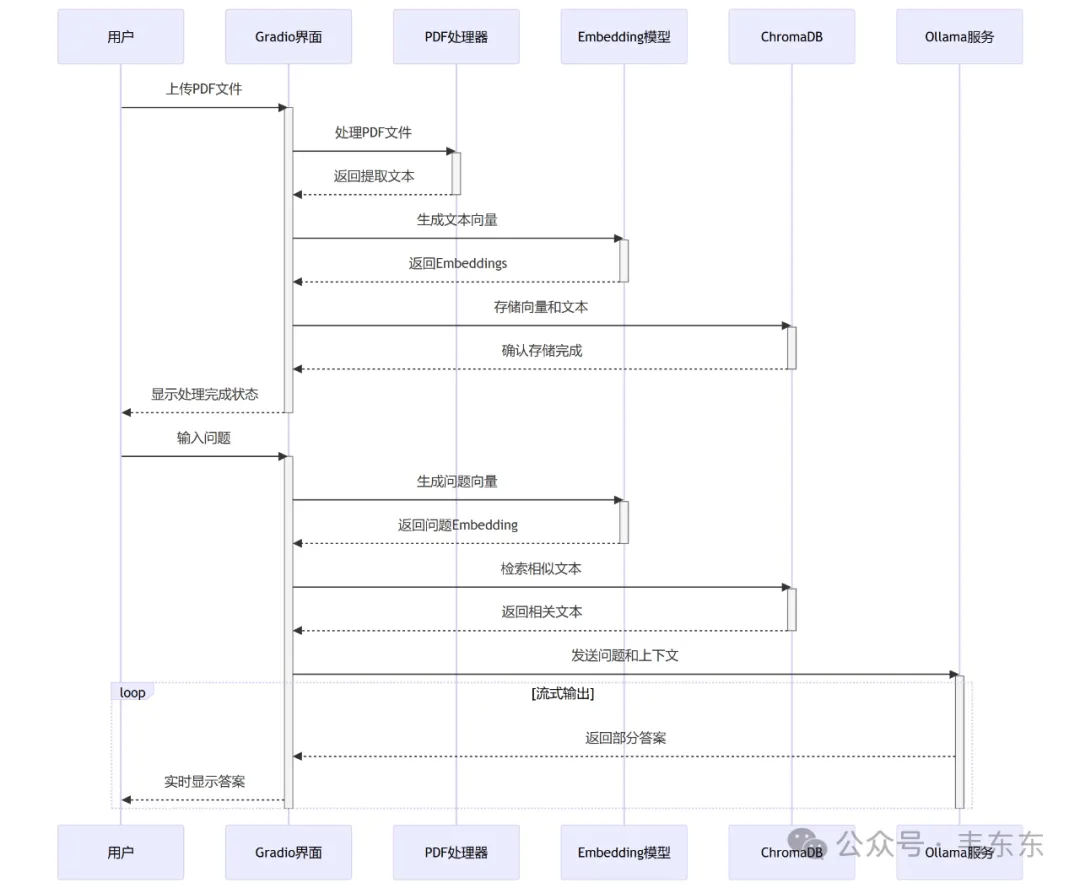
3、系统架构
使用 Ollama 部署的 DeepSeek-r1:7b 作为推理模型,通过 Sentence Transformer (all-MiniLM-L6-v2) 将文本向量化后存储到 ChromaDB 向量数据库,使用 LangChain 的文本分割器处理 PDF 文档,最后用 Gradio 构建了一个支持文件上传和流式问答的 Web 交互界面,整个过程都在本地完成,无需连接外部服务。
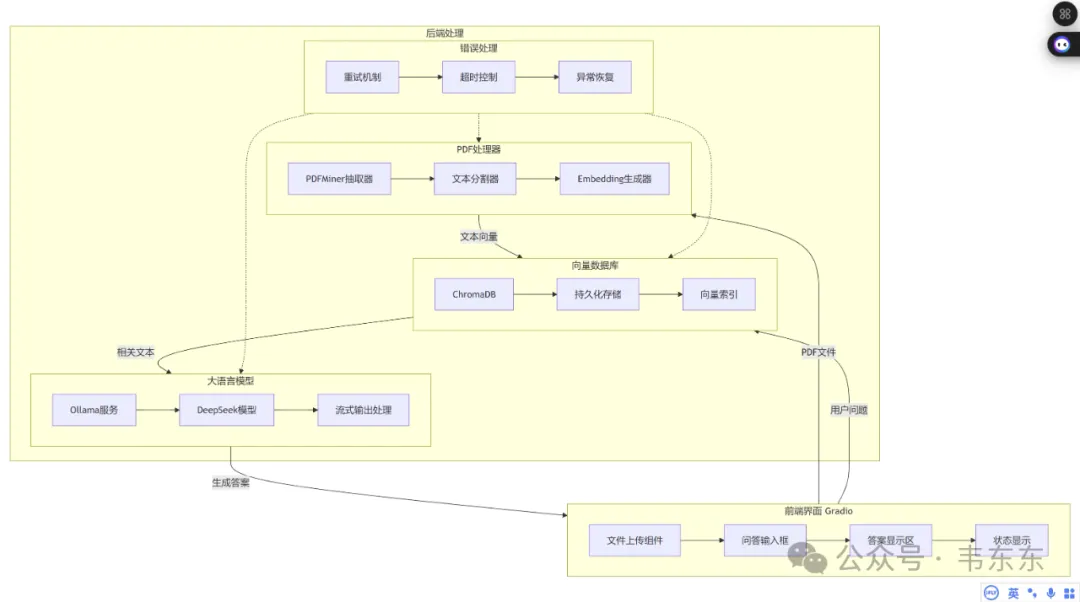
📄 PDF 文档解析与向量化存储
🧠 基于 DeepSeek-7B 本地大模型
⚡ 流式回答生成
🔍 语义检索与上下文理解
🖥️ 友好的 Web 交互界面
4、使用方法
4.1 环境要求
Python 3.9+;内存:至少 8GB;显存:至少 4GB(推荐 8GB)
4.2 安装步骤
克隆仓库
git clone https://github.com/weiwill88/Local_Pdf_Chat_RAG
cd Local_Pdf_Chat_RAG
创建虚拟环境
python -m venv rag_env (windows 命令)
安装依赖
.\rag_env\Scripts\activate
pip install -r requirements.txt
安装并启动 Ollama 服务
ollama pull deepseek-r1:7b
ollama serve &
启动服务
python rag_demo.py
访问浏览器打开的本地地址
通常是 http://localhost:17995 上传 PDF 文档(等待处理完成)、在提问区输入问题、查看实时生成的回答
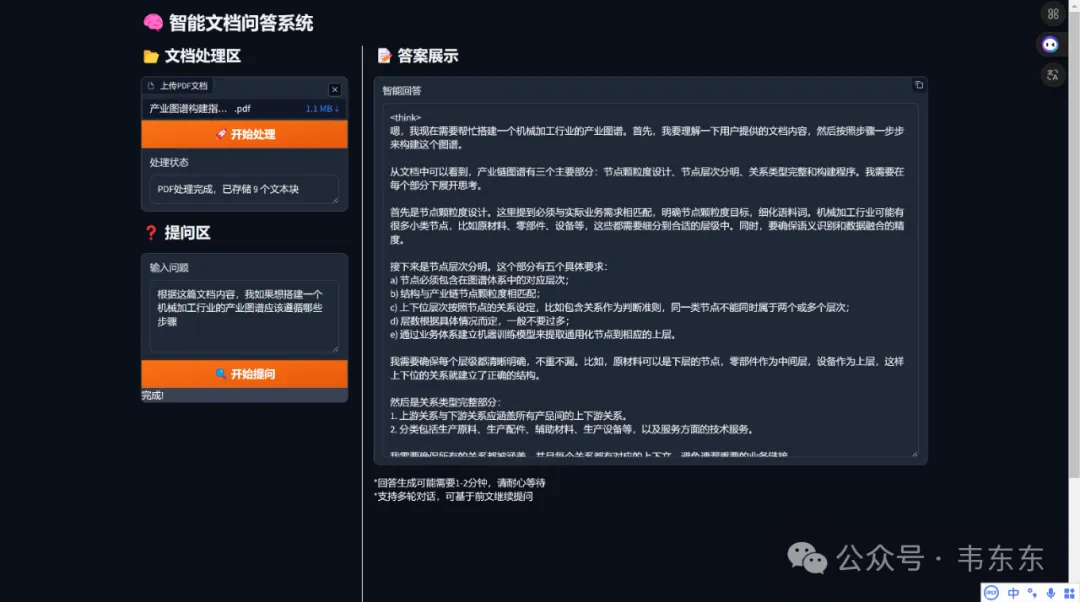
配置说明
修改 rag_demo.py 中第 147 行的模型名称可替换为其他支持的模型
4.3 RAG 优化技巧
🛠️ 分块策略优化:
根据文档类型调整 chunk_size(技术文档建议 800-1200,对话文本建议 400-600)使用滑动窗口重叠策略保持上下文连贯性
🔍 检索增强:
结合 BM25+语义检索的混合搜索添加文档元数据过滤(如章节标题)实现结果重排序(Rerank)提升相关性
💬 查询优化:
问题重写(Query Rewriting)查询扩展(Query Expansion)多轮对话上下文管理
⚡ 性能优化:
使用量化版嵌入模型(如 all-MiniLM-L6-v2)实现向量索引缓存机制采用批处理加速文档处理
📊 评估体系:
构建测试用例评估召回率监控回答准确率记录用户反馈持续优化
5、四种应用场景示例
5.1 律师诉状智能生成
痛点
案件证据材料分散在纸质卷宗/邮件/聊天记录中
人工检索匹配相似判例需遍历多个法律数据库,耗时较长
解决方案
构建律所或者律师个人的私有案例库:自动解析裁判文书PDF中的争议焦点、法条引用、赔偿金额等要素
诉状要素智能填充:输入"劳动仲裁+工伤赔偿"等标签,自动关联《工伤保险条例》第37条及近三年同类型判决赔偿金中位数
证据链完整性校验:根据案由自动生成必备证据清单(如劳动合同、医疗鉴定书等)
5.2 制造业技术文档问答
痛点
设备手册包含 2000+页PDF/图纸,故障代码查询耗时>30分钟
新人无法理解"主轴轴向窜动≤0.01mm"等专业术语的实操标准
解决方案
多模态知识库:设备文档结构化(按故障代码/维护周期/精度标准打标签)
实操视频片段索引(关联"E02报警"对应的齿轮箱拆装演示)
智能检索:输入"加工中心定位精度超差",返回导轨磨损检测流程及塞尺使用规范图示
5.3 贷款客户经理风控初筛
痛点
客户经理需要处理大量企业客户数据,例如发票数据、流水数据、上下游合同等信息,人工分析耗时长且易遗漏关键风险点。
企业财务与经营状况信息分散且非结构化,难以快速形成清晰的风控结论。
解决方案
信息结构化:通过大模型对发票数据、流水数据、合同条款等进行关键信息抽取(如合同金额、付款周期、供应链关联方等),并自动分类和标注(如信用风险、履约风险)。
多模态检索:基于RAG技术,支持客户经理输入如“企业流动资金占比异常”或“上下游履约风险”问题,系统快速检索合同条款、流水异常记录,并返回具体的风险点分析和建议。
本地部署保障数据安全:所有数据分析均在本地完成,满足企业客户对敏感信息保护的合规要求。
5.4 零售业私有知识推荐
痛点
产品知识分散在 100+份 Excel 参数表/PPT培训材料中
客户咨询"敏感肌精华成分"时,新人需手动比对10+竞品手册
解决方案
商品知识中枢:
自动提取产品文档中的成分表/适用肤质/禁忌搭配数据
构建成分冲突库(含酒精成分产品不可与 A 醇类产品叠加使用)
场景化推荐引擎:
输入"30 岁油皮夏季护肤",推送控油套装+搭配使用顺序+关联满减方案
实时竞品对比(展示本方产品 B5 泛醇含量高于竞品 3.2%)




还没有评论,来说两句吧...