

deepseek原理+应用+实践,和大家分享:
小众的,deepseek核心技术原理;
大众的,提示词要怎么写;
今天和大家聊聊,deepseek的核心技术之一的动态注意力机制。

要搞懂这个,先得知道什么是注意力机制?
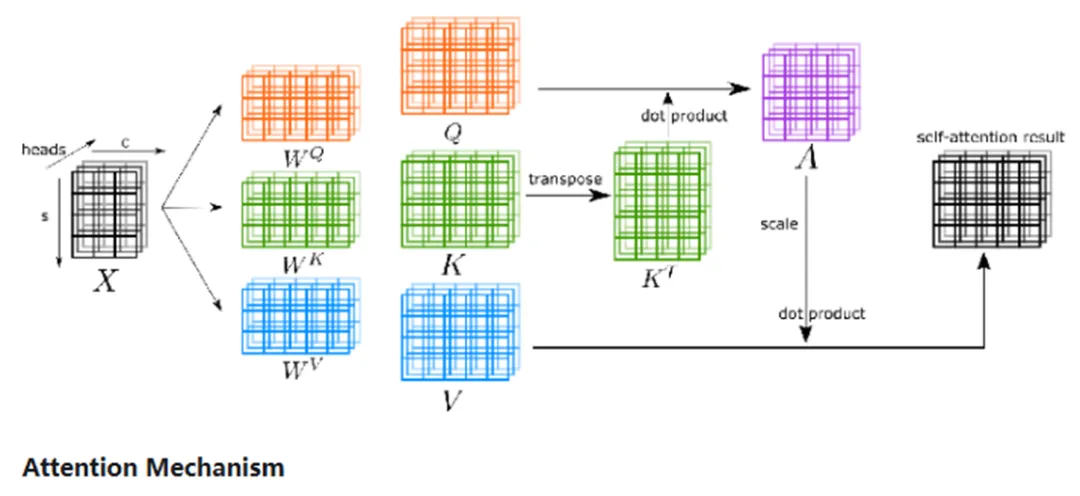
这是一种通过计算…查询向量(Query)…键向量(Key)…值向量(Value)…,最终得到...的技术。
画外音:额,不折磨大家了。
注意力机制,Attention Mechanism,是如今AI最核心的技术(之一)。通俗地说,它允许模型在处理信息时,专注于最关键的部分,弱化甚至忽略不相关的信息,从而提高处理效率与回复的质量。它通过注意力分数,来量化描述某一部分信息被关注的程度,以反映相关信息在全局中的重要性。
举个例子,用户输入提示词:
哎哟妈呀,我跟你说,那啥,我今天早上出门,这天儿可够冷的,那风嗖嗖的,吹得我脸都僵了,我寻思着,咋这么冷呢,是不是把厚棉袄穿少了,你说这天儿咋就那么邪乎呢,反正我这心里寻思着,哪儿能去买个暖宝宝贴贴。
这个提示词中包含大量日常交流习惯中的铺垫与情感表达,属于无效信息。注意力机制会让模型将注意力专注在:今天早上很冷,我穿少了,哪儿能买暖宝宝?
注意力机制是什么来的?
注意力机制最符合人的真实思维。
再举个例子:

第一眼看到一张图片,你的注意力在哪儿,每个像素的权重是一样的吗?是不是一眼就会看到框中的耳环,根本不会注意到其他部位。
这!就是神奇的注意力机制。
那什么是动态注意力机制?
Dynamic Attention,要比注意力机制更进一步,它不仅能够学习到不同部分的相关性,还能在处理过程中自适应的调整注意力的分配,把资源聚焦于当下最重要的部分,使得模型更加智能(例如:文本,代码,图表在计算过程中权重会动态变化)。
技术人应该很容易理解这个所谓的“动态”:
负载均衡 -> 根据历史数据学习训练好参数,3台机器的流量分配权重配置好1:2:3。
动态负载均衡 -> 在系统运行过程中,根据3台机器处理能力,动态变化流量分配权重。
动态注意力机制,对我们写提示词,获取更佳的回答质量有什么启示呢?
我们可以在提示词中:
1. 显性的标注关键信息,例如:
角色
技能
限制
步骤
2. 显示设置约束条件,例如:
优先考虑方案的分区容忍性与高可用
先不考虑内网延时对方案的影响
3. 采用分层分步描述,让deepseek清楚每一步的注意力重点,例如:
第一步… 第二步… 第三步…
先设计框架,再填充细节
给出3组方案量化分析与优缺点后,经过我确认选择哪一组方案再继续
优化了提示词,deepseek动态注意力机制能更有效发挥:
有限深度思考时间,专注主要矛盾,增加分析维度,回复质量极大提升;
相同质量的回复,动态分配权重,极大降低计算消耗;
总结
动态注意力机制是deepseek的核心技术(之一);
注意力机制最符合人的真实思维;
所谓“动态”,是指在运行过程中的注意力变化;
通过显性标注关键信息,显性设置约束条件,显性分层分步描述,能够最大化发挥deepseek动态注意力机制的潜力;
一切的一切,提示词只有适配了AI的认知模式,才能最高效的发挥最大的作用。
知其然,知其所以然。
思路比结论更重要。
补充阅读材料:
《Attention Is All You Need》:https://arxiv.org/pdf/1706.03762
PDF,可下载。
《动态注意力机制》:https://github.com/davidangularme/DynamicAttention

含源码,Python。




还没有评论,来说两句吧...