

论文一作陈汐,现为香港大学三年级博士生,在此之前本科硕士毕业于浙江大学,同时获得法国马赛中央理工双硕士学位。主要研究方向为图像视频生成与理解,在领域内顶级期刊会议上发表论文十余篇,并且 GitHub 开源项目获得超过 5K star.
本文中,香港大学与 Adobe 联合提出名为 UniReal 的全新图像编辑与生成范式。该方法将多种图像任务统一到视频生成框架中,通过将不同类别和数量的输入/输出图像建模为视频帧,从大规模真实视频数据中学习属性、姿态、光照等多种变化规律,从而实现高保真的生成效果。
论文标题:UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
项目主页:https://xavierchen34.github.io/UniReal-Page/
论文链接:https://arxiv.org/abs/2412.07774
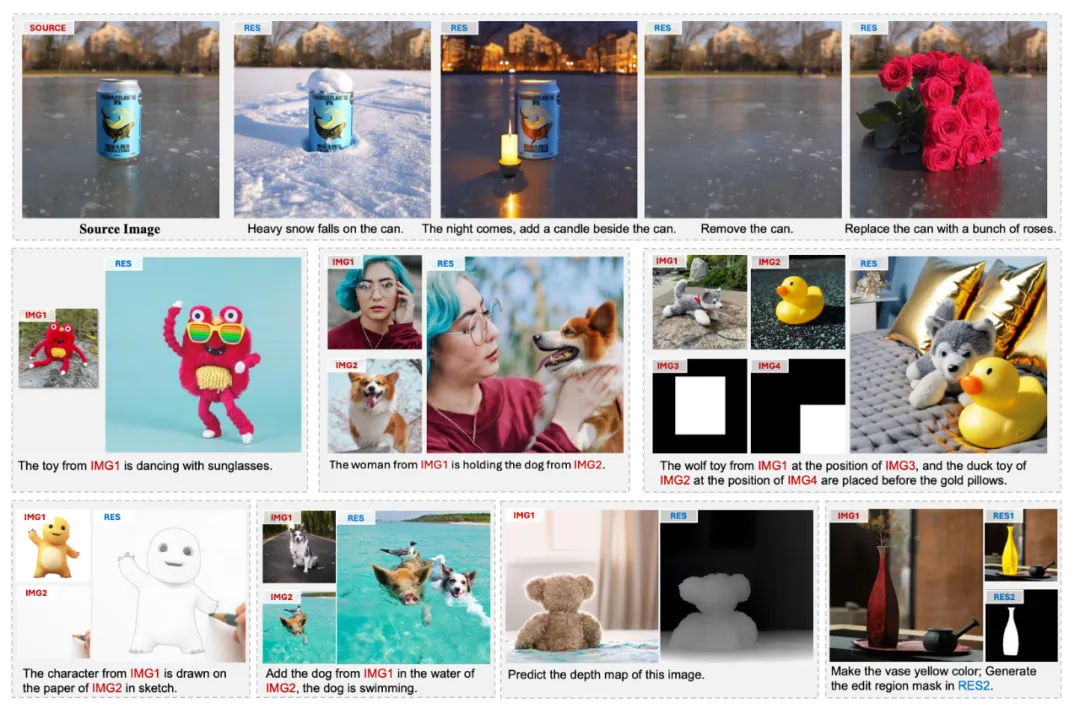
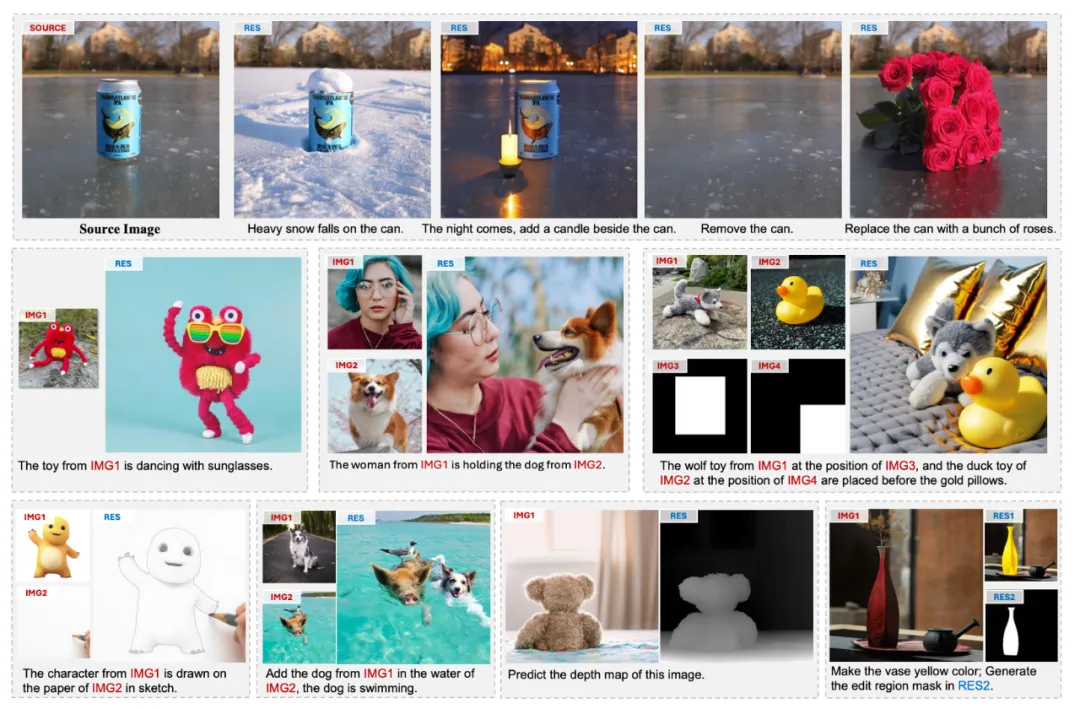
效果展示
我们重点展示了图像生成与编辑中最具挑战性的三个任务的效果:图像定制化生成、指令编辑和物体插入。
此外,UniReal 还支持多种图像生成、编辑及感知任务,例如文本生成图像、可控图像生成、图像修复、深度估计和目标分割等。
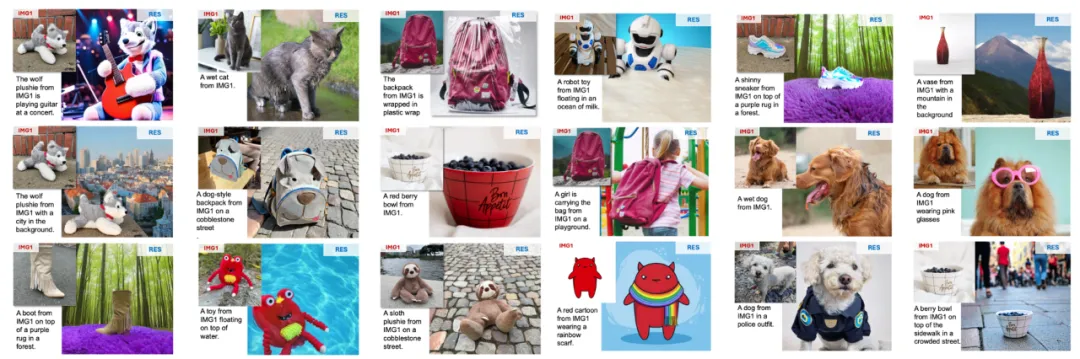
在单目标定制化生成任务中,UniReal 能够在准确保留目标细节(如 logo)的同时,生成具有较大姿态和场景变化的图像,并自然地模拟物体在不同环境下的状态,从而实现高质量的生成效果。

与此同时,UniReal 展现了强大的多目标组合能力,能够精确建模不同物体之间的交互关系,生成高度协调且逼真的图像效果。

值得注意的是,我们并未专门收集人像数据进行训练,UniReal 仍能够生成自然且真实的全身像定制化效果,展现了其出色的泛化能力。
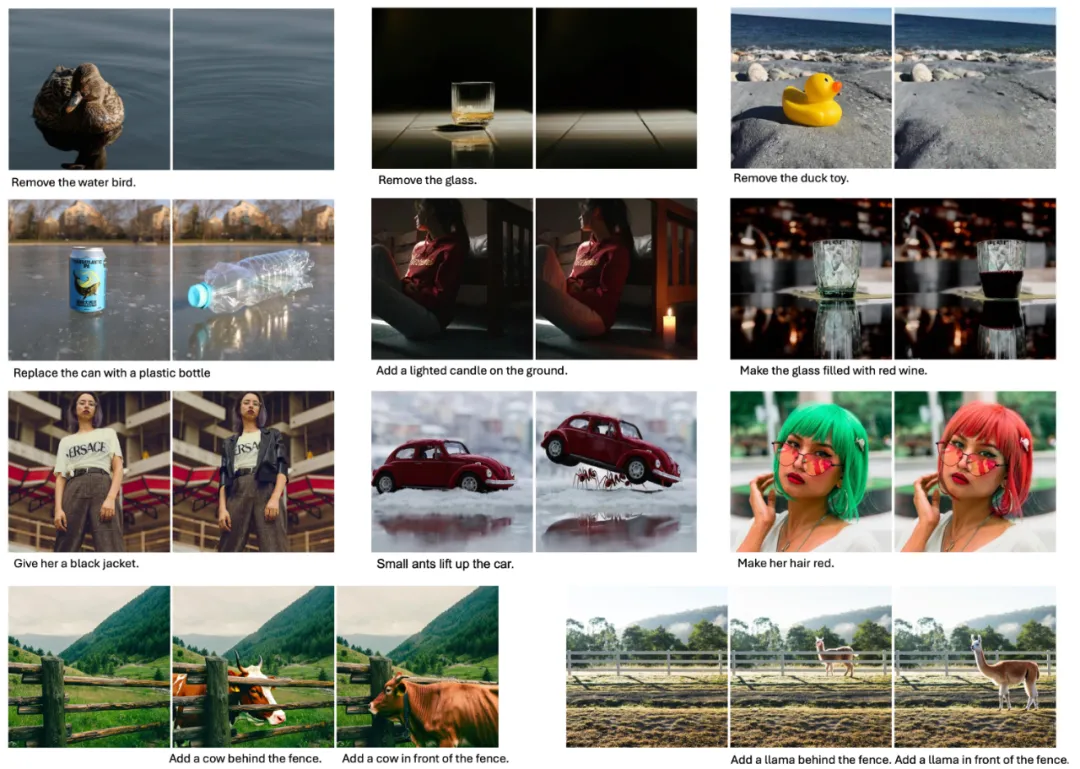
在指令编辑方面,UniReal 支持用户通过自由输入文本对图像进行灵活编辑,例如添加或删除物体、修改属性等。实验结果表明,UniReal 展现出了卓越的场景理解能力,能够真实地模拟物体的阴影、反射以及前后遮挡关系,生成高度逼真的编辑效果。

UniReal 支持从图像中提取特定目标作为前景,插入到背景图像中,天然适用于虚拟试衣、Logo 迁移、物体传送等任务。实验表明,UniReal 插入的目标能够非常自然地融入背景图像,呈现出与背景一致的和谐角度、倒影效果及环境匹配度,显著提升了任务的生成质量。
除了上述任务外,UniReal 还支持文本生成图像、可控图像生成、参考式图像补全、目标分割、深度估计等多种任务,并能够同时生成多张图像。此外,UniReal 支持各类任务的相互组合,从而展现出许多未经过专门训练的强大能力,进一步证明其通用性和扩展性。
方法介绍
UniReal 的目标是为图像生成与编辑任务构建一个统一框架。我们观察到,不同任务通常存在多样化的输入输出图像种类与数量,以及各自独特的具体要求。然而,这些任务之间共享一个核心需求:在保持输入输出图像一致性的同时,根据控制信号建模图像的变化。
这一需求与视频生成任务有天然的契合性。视频生成需要同时满足帧间内容的一致性与运动变化,并能够支持不同的帧数输出。受到近期类似 Sora 的视频生成模型所取得优异效果的启发,我们提出将不同的图像生成与编辑任务统一到视频生成架构中。
此外,考虑到视频中自然包含真实世界中多样化的动态变化,我们直接从原始视频出发,构建大规模训练数据,使模型能够学习和模拟真实世界的变化规律,从而实现高保真的生成与编辑效果。
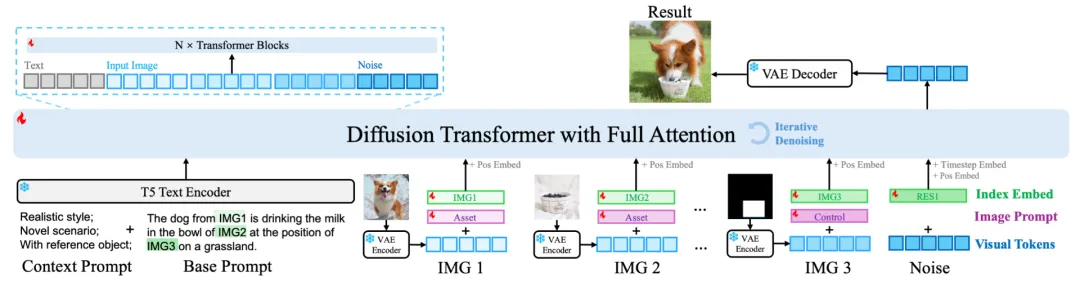
模型结构:我们借鉴了与 Sora 类似的视频生成架构,将不同的输入输出图像统一视作视频帧处理。具体来说,图像通过 VAE 编码后被转换为视觉 token,接着输入 Transformer 进行处理。与此同时,我们引入了 T5 text encoder 对输入指令进行编码,将生成的文本 token 与视觉 token 一同输入 Transformer。通过使用 full attention 机制,模型能够充分建模视觉和文本之间的关系,实现跨模态信息的高效融合和综合理解。这种设计确保了模型在处理多样化任务时的灵活性和生成效果的一致性。
层级化提示:为了解决不同任务和数据之间的冲突问题,同时支持多样化的任务与数据,我们提出了一种 Hierarchical Prompt(层级化提示)设计。在传统提示词(Prompt)的基础上,引入了 Context Prompt 和 Image Prompt 两个新组件。
Context Prompt:用于补充描述不同任务和数据集的特性,包括任务目标、数据分特点等背景信息,从而为模型提供更丰富的上下文理解。
Image Prompt:对输入图像进行层次化划分,将其分为三类:
Asset(前景):需要重点操作或变更的目标区域;
Canvas(画布):作为生成或编辑的背景场景;
Control(控制):提供约束或引导的输入信号,如参考图像或控制参数。
为每种类别的输入图像单独训练不同的 embedding,从而帮助模型在联合训练中区分输入图像的作用和语义,避免不同任务和数据引发的冲突与歧义。
通过这种层级化提示设计,模型能够更高效地整合多样化的任务和数据,显著提升联合训练的效果,进一步增强其生成和编辑能力。
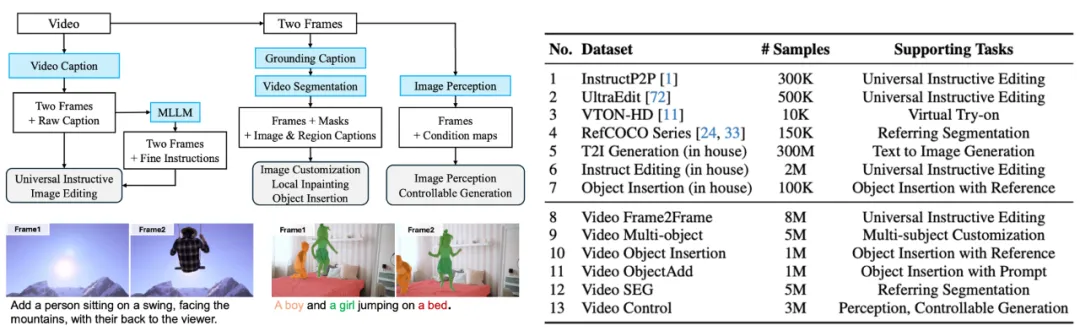
数据构造:我们基于原始视频数据构建了大规模训练数据集,以支持多样化的任务需求。具体步骤如下:
1. 编辑数据生成
从视频中随机抽取前后两帧,分别作为编辑前和编辑后的图像结果,并借助视觉语言模型(VLM)生成对应的编辑指令,以模拟多样化的图像编辑任务。
2. 多目标定制化生成
我们结合 VLM 与 SAM2,在视频首帧中分割出不同的目标区域,并利用这些目标区域重建后续帧,构造多目标定制化生成的数据。这种方式能够模拟目标在复杂场景中的动态变化,并为多目标生成任务提供高质量的数据支持。
3. 可控生成与图像理解标注
利用一系列图像理解模型(如深度估计模型)对视频和图像进行自动打标。这些标签不仅为可控生成任务(如深度控制生成)提供了丰富的条件信息,还为图像理解任务(如深度估计、目标分割)提供了标准参考。
通过这种基于原始视频的多层次数据构造策略,我们的模型能够学习真实世界中的动态变化规律,同时支持多种复杂的图像生成与理解任务,显著提升了数据集的多样性和模型的泛化能力。
效果对比
在指令编辑任务中,UniReal 能够更好地保持背景像素的一致性,同时完成更具挑战性的编辑任务。例如,它可以根据用户指令生成 “蚂蚁抬起轿车” 的画面,并在轿车被抬起后动态调整冰面上的反射,使其与场景的物理变化相一致。这种能力充分展现了 UniReal 在场景理解和细节生成上的强大性能。

在定制化生成任务中,无论是细节的精确保留还是对指令的准确执行,UniReal 都展现出了显著的优势。其生成结果不仅能够忠实还原目标细节,还能灵活响应多样化的指令需求,体现出卓越的生成能力和任务适应性。

在物体插入任务中,我们与此前的代表性方法 AnyDoor 进行了对比,UniReal 展现出了更强的环境理解能力。例如,它能够正确模拟狗在水中的姿态,自动调整易拉罐在桌子上的视角,以及精确建模衣服在模特身上的状态,同时保留模特的头发细节。这种对场景和物体关系的高度理解,使 UniReal 在生成真实感和一致性上远超现有方法。

未来展望
UniReal 在多个任务中展现了强大的潜力。然而,随着输入和输出图像数量的进一步扩大,训练与推理效率问题成为需要解决的关键挑战。为此,我们计划探索设计更高效的注意力结构,以降低计算成本并提高处理速度。同时,我们还将这一方案进一步扩展到视频生成与编辑任务中,利用高效的结构应对更复杂的数据规模和动态场景需求,推动模型性能与实用性的全面提升。




还没有评论,来说两句吧...