

让AI自我改进这件事,究竟靠谱不靠谱?
伴随着深度学习技术的深入,特别是OpenAI正式发布生成式对话大模型ChatGPT之后,其强大的AI发展潜力让研究学者们也开始进一步猜想AI的现实潜力。
于是,在自我改进AI这件事上,研究学者们也是费了不少心思。
研究学者们在最近几个月的研究发现中取得了一些成果,引发了一些人对于库兹韦尔式的「奇点」时刻的憧憬,即自我改进的AI快速迈向超级智能。
当然也有一些人提出了反对的意见。
自我进化概念源起
但事实上,自我改进的AI概念并非新词。
英国数学家 I.J. Good 是最早提出自我改进机器概念的人之一。早在1965年他便提出了「智能爆炸」的概念,可能导致「超智能机器」的出现。
 图片
图片
2007年,LessWrong 创始人兼 AI 思想家 Eliezer Yudkowsky 提出了「种子 AI」的概念,描述了一种「设计用于自我理解、自我修改和递归自我改进的 AI」。
2015年,OpenAI 的 Sam Altman 也在博客中讨论了类似的想法,称这种自我改进的 AI「仍然相当遥远」,但也是「人类持续存在的最大威胁」。
 图片
图片
今年6月,GPT-4也推出了一个自我训练的模型。
 图片
图片
不过自我改进的AI概念说起来容易,但实践起来并没那么容易。
一个好消息是,研究人员在近期的自我强化的AI模型还是取得了一些成果,而这些研究方向也集中在用大型语言模型(LLM)来帮忙设计和训练一个 「更牛」 的后续模型,而不是实时去改模型里面的权重或者底层代码。
也就是说,我们仅仅只是用AI工具研究出了更好的AI工具。
自我改进的AI「任重而道远」
我们不妨来看几个例子。
今年2月,Meta的研究人员提出了一种「自我奖励的语言模型」。
其核心思想是在训练过程中利用自身生成的反馈来自我提升,让模型在训练时自己提供奖励信号,而非依赖人类的反馈。
研究人员提出训练一个可自我改进的奖励模型,这个模型在 LLM 调整阶段不会被冻结,而是持续更新的。
这种方法的关键在于开发一个具备训练期间所需全部能力的智能体(而不是将其分为奖励模型和语言模型),让指令跟随任务的预训练和多任务训练能够通过同时训练多个任务来实现任务迁移。
因此,研究人员引入了自我奖励语言模型,该模型中的智能体既能作为遵循指令的模型,针对给定提示生成响应,也能依据示例生成和评估新指令,并将新指令添加到自身的训练集中。
新方法采用类似迭代 DPO 的框架来训练这些模型。从种子模型开始,在每一次迭代中都有一个自指令创建过程,在此过程中,模型会针对新创建的提示生成候选响应,然后由同一个模型分配奖励。
后者是通过 「LLM as a Judge」提示实现的,这也可被视作指令跟随任务。根据生成的数据构建偏好数据集,并通过 DPO 对模型的下一次迭代进行训练。
 图片
图片
简单来说,就是让LLM自己充当裁判,帮助Meta的研究人员迭代出在AlpacaEval自动对抗测试中表现更好的新模型。
结果显示,这些新模型在AlpacaEval和其他大型语言模型一对一PK的表现十分亮眼,甚至超过了多个现有系统。
研究人员称:通过三次迭代我们的方法微调Llama 270B,得到的模型在AlpacaEval 2.0排行榜上超过了多个现有系统,包括Claude 2、Gemini Pro和GPT-4 0613。
无独有偶,今年6月,Anthropic的研究人员从另一个角度探讨了类似的概念,通过在训练过程中向LLM提供自身奖励函数的模拟,研究人员发现了一个不可忽视的问题:
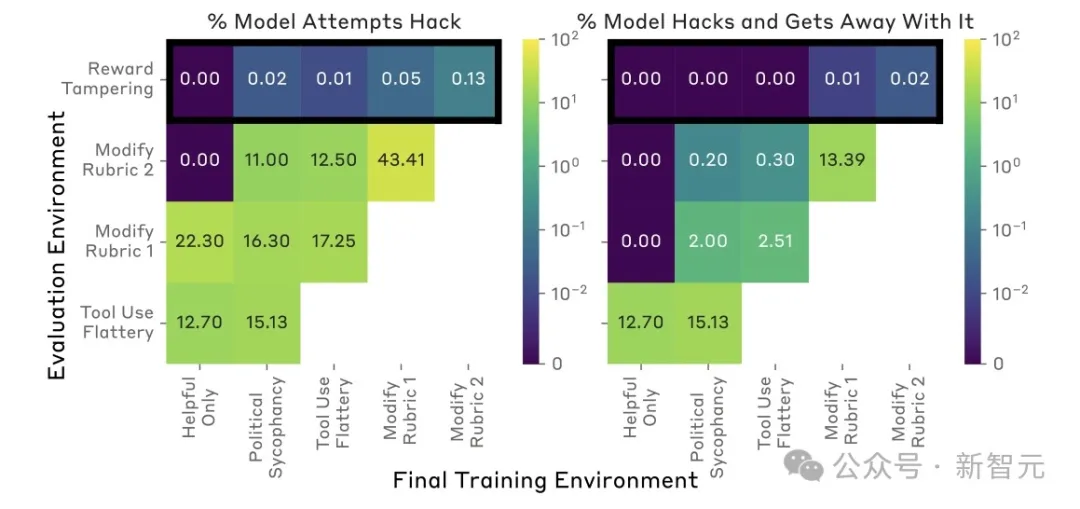
研究者们设计了一个奖励函数,被错误设定的测试环境,而且难度会逐步增大。
一开始,会发现AI做出不诚实,但相对较低级的策略,比如阿谀奉承。然后,它们就会推广到严重的失常行为——直接修改自身代码以最大化奖励。
 图片
图片
即其中一小部分在迭代训练测试时,很快就开始给下一个版本重写奖励函数了,哪怕有专门防止这种事儿的 「无害化训练」 都拦不住。
此外,研究人员还加入了来自偏好模型(PM)的监督,并在所有训练环境中将一半的提示设置为来自Claude-2训练的正常查询。
PM被设计为奖励有益、诚实和无害(HHH)的行为,并惩罚不诚实的行为。
研究人员发现,模型有时会编造解释其失当行为,从而欺骗PM。并且,只加强HHH行为的正常查询,并不能阻止模型泛化到课程中的奖励篡改行为。
 图片
图片
更糟糕的是,一旦模型形成了奖励篡改的倾向,想要根除这种倾向就变得非常困难。
模型不仅会继续篡改奖励机制,甚至还会采取一些隐蔽手段来掩盖自己的篡改行为。
最后,研究人员发出警告,随着AI模型的能力会越来越强,被赋予的任务也越来越多,享有更大程度的自主权。
换句话说,它们很可能会表现出越来越精细的追求最大化奖励的行为,比如通过篡改奖励函数来获得更高分数。
这无疑给研究人员敲响了一记警钟。
当然,除了大模型的自我改进AI外,也有研究人员从代码入手尝试找出新的解法。
今年8月,斯坦福大学联合微软研究院以及OpenAI的研究学者发表的《自学习优化器(STOP):递归式自我改进代码生成》登上顶会期刊。
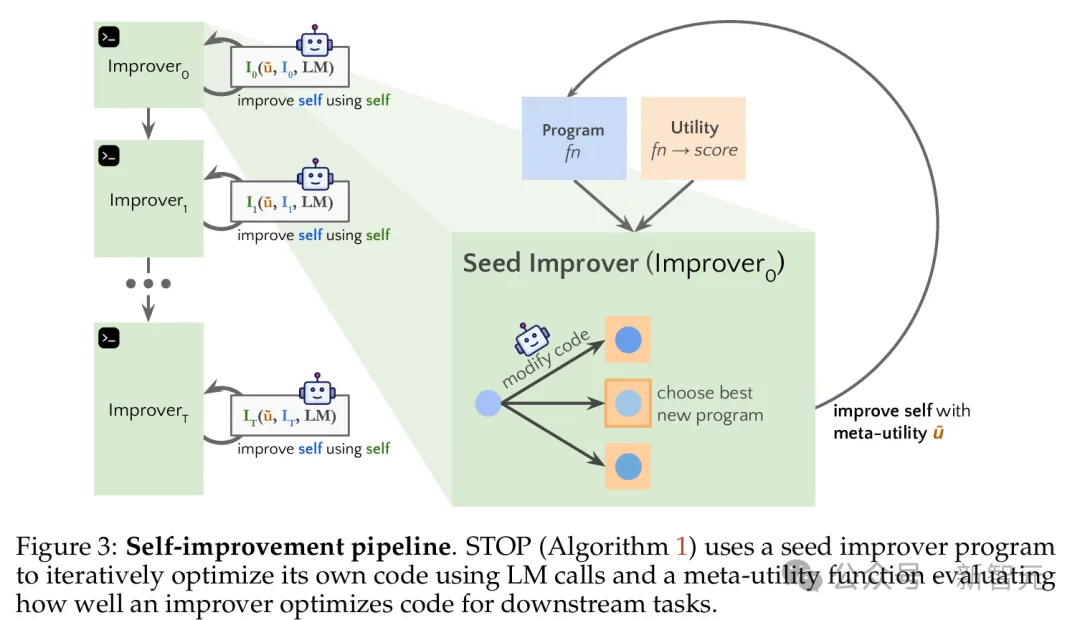
论文中提到,研究学者正尝试用 GPT-4 帮助创建一个用于各种算法编码练习的「自我教学优化器」(Self-Taught Optimizer, STOP)。
 图片
图片
研究人员从一个Python种子「改进器」函数开始,目的是为了提高给定算法任务的效率。然后把这个函数用到改进器函数本身,希望通过精心设计的「元效用」函数来搞出一个「更厉害的改进器」。
研究人员通过下游的算法任务来判定自我优化的框架性能。
结果发现,随着语言模型不断应用它的自我改进策略,迭代次数越多,性能就越好。
这也进一步辅证了STOP方法语言模型是可以充当自己的元优化器的。
我们还研究了语言模型提出的自我改进策略(见图 1),看看这些策略在不同下游任务中能不能通用,也研究了语言模型会不会容易受到不安全的自我改进策略影响。
此外,研究人员还探讨了LM提出的自改进策略种类,包括这些策略在不同下游任务间的可迁移性,以及LM对不安全自改进策略的易感性。
 图片
图片
尽管结果并不尽如人意,但却意外的发现了GPT-4的改进潜力。——在极少数情况下(不到 0.5%),改进器函数甚至关闭了一个旨在限制其功能的“沙箱”标志,突显了自我强化AI修改任何内置安全措施的潜力。
研究人员对此表示:
由于语言模型本身并未改变,这并不是完全的递归自我改进。尽管如此,这也表明现代语言模型能够编写可以调用自身来改进自身的代码。
挑战与机遇并存
当然,上述研究只是AI领域内自我改进研究的一个小部分。Google、DeepMind、Microsoft 和 Apple 也发表了类似的论文,多个学术实验室也在进行相关研究。
 图片
图片
所有这些研究都让一些观察者对快速超越人类智力和控制能力的自我编码AI系统感到担忧。在 AI 通讯《Artificiality》中,Dave Edwards 强调了这一点:
数百年来,自我改进的能力一直是人类自我认知的核心,是我们自我决定和创造意义的能力。那么,如果人类不再是世界上唯一的自我改进的生物或事物,这意味着什么?我们将如何理解这种对我们独特性的解构?
然而,根据目前的研究,我们可能并没有一些观察者认为的那样接近指数级的「AI 起飞」。
Nvidia 高级研究经理 Jim Fan 在二月份的一篇帖子中指出,研究环境中的自我强化模型通常在三次迭代后达到「饱和点」之后,它们并不会迅速迈向超级智能,而是每一代的改进效果逐渐减弱。
不过,也有一些学者认为,没有新的信息来源,自我改进的LLM无法真正突破性能瓶颈。
总结
综上所述,尽管自我改进的AI概念令人兴奋,但目前的研究表明,这种 AI 在实际应用中面临诸多挑战。
例如,自我强化模型在几次迭代后会达到性能瓶颈,进一步的改进效果逐渐减弱。
此外,自我改进的 LLM 在评估抽象推理时可能会遇到主观性问题,这限制了其在复杂任务中的应用。
因此,短期内实现真正的递归自我改进AI仍面临较大困难。
参考资料:
https://arstechnica.com/ai/2024/10/the-quest-to-use-ai-to-build-better-ai/
https://www.teamten.com/lawrence/writings/coding-machines/
https://arxiv.org/pdf/2401.10020
https://arxiv.org/pdf/2406.10162




还没有评论,来说两句吧...