


译者 | 朱先忠
审校 | 重楼
本文将通过一个实战案例来展示如何借助于PyTorch自动混合精度库对ResNet50模型进行优化,然后借助少许几行代码即可获得超过两倍速度的模型训练效率。
简介
你是否曾希望你的深度学习模型运行得更快?
一方面,GPU很昂贵。另一方面,数据集庞大,训练过程似乎永无止境;你可能有一百万个实验要进行,还有一个截止日期。所有这些需求都是期待特定形式的训练加速的极好理由。
但是,我们该选哪一种模型呢?
PyTorch、HuggingFace和Nvidia已经为模型训练的性能调优提供了很好的参考,包括异步数据加载、缓冲区检查点、分布式数据并行化和自动混合精度等等。
在这篇文章中,我将专注介绍自动混合精度技术。首先,我将简要介绍Nvidia的张量核设计;然后,我们一起探讨发表在ICLR 2018上的开创性工作——“混合精度训练”相关论文;最后,我将介绍一个在FashionMNIST数据集上训练ResNet50模型的简单示例。通过这个示例,我们来展示如何在加载双倍批量数据的同时将训练速度提高两倍,而这一结果却只需要额外编写三行代码。
硬件基础——Nvidia张量核
首先,让我们回顾一下GPU设计的一些基本原理。英伟达GPU最受欢迎的商业产品之一是Volta系列,例如基于GV100 GPU设计的V100 GPU。因此,我们将围绕下面的GV100架构进行讨论。
对于GV100架构来说,流式多处理器(SM)是计算的核心设计。每个GPU包含6个GPU处理集群(GPC)和S84 SM(或V100的80 SM)。其整体设计如下图所示:

Volta GV100 GPU设计(每个GPU包含6个GPC,每个GPC包含14个SM;图像来源:https://arxiv.org/pdf/1803.04014)
对于每个SM,它包含两种类型的核心:CUDA核心和张量核。CUDA核心是Nvidia于2006年推出的原始设计,是CUDA平台的重要组成部分。CUDA核心可分为三种类型:FP64核心/单元、FP32核心/单元和Int32核心/单元。每个GV100 SM包含32个FP64核心、64个FP32核心和64个Int32核心。Volta/Turing(2017)系列GPU中引入了张量核,以便与之前的Pascal(2016)系列分离。GV100上的每个SM包含8个张量核。链接处给出了V100 GPU的完整详细信息列表。下面详细介绍SM设计。
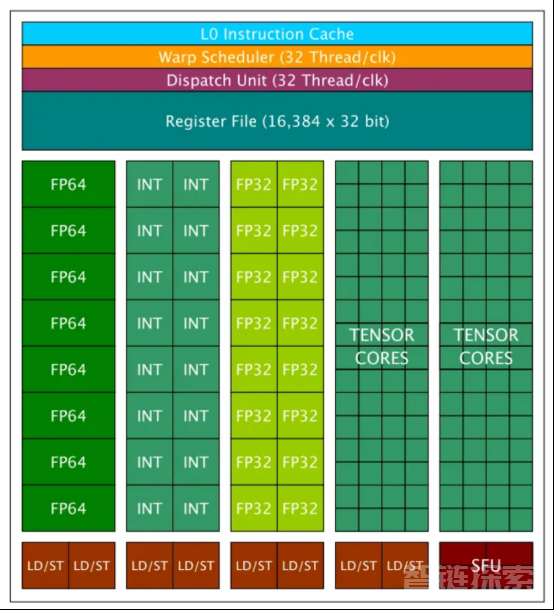
一个英伟达Tesla V100处理组就包含640个张量核(图像来源:https://arxiv.org/pdf/1903.03640)
为什么选择张量核?Nvidia张量核专门用于执行通用矩阵乘法(GEMM)和半精度矩阵乘法和累加(HMMA)操作。简而言之,GEMM以A*B+C的格式执行矩阵运算,HMMA将运算转换为半精度格式。有关这方面的更详细的讨论可以在链接处找到。由于深度学习涉及MMA;所以,张量(Tensor)核心在当今的模型训练和加速计算中至关重要。
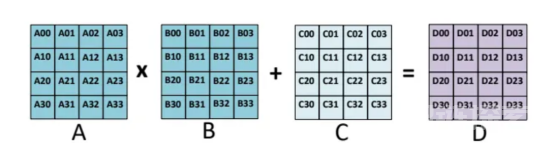
GEMM操作示例(对于HMMA,A和B通常转换为FP16,而C和D可以是FP16或FP32),图像来源:https://arxiv.org/pdf/1811.08309
当然,当切换到混合精度训练时,请务必检查你使用的GPU的规格。只有最新的GPU系列支持张量核,混合精度训练只能在这些机器上使用。
数据格式基础——单精度(FP32)与半精度(FP16)
现在,让我们仔细看看FP32和FP16格式。FP32和FP16是IEEE格式,使用32位二进制存储和16位二进制存储表示浮点数。这两种格式都包括三个部分:a)符号位;b)指数位;c)尾数位。FP32和FP16分配给指数和尾数的比特数不同,这导致了不同的值范围和精度。
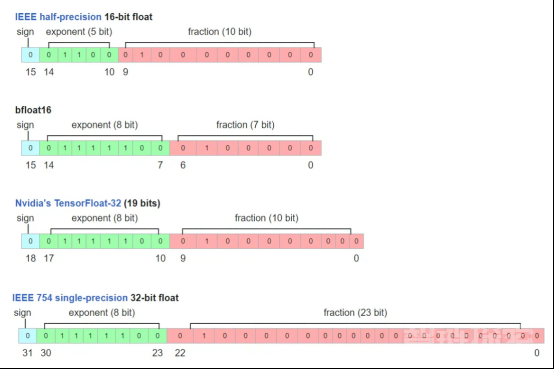
FP16(IEEE标准)、BF16(Google Brain标准)、FP32(IEEE标准)和TF32(Nvidia标准)之间的区别(图像来源:https://en.wikipedia.org/wiki/Bfloat16_floating-point_format)
如何将FP16和FP32转换为真实的值呢?根据IEEE-754标准,FP32的十进制值=(-1)^(符号)×2^(十进制指数-127)×(隐式前导1+十进制尾数),其中127是有偏差的指数值。对于FP16,公式变为(-1)^(符号)×2^(十进制指数-15)×(隐式前导1+十进制尾数),其中15是相应的有偏指数值。你可以在链接处查看有偏指数值的更多详细信息。
从这个意义上讲,FP32的取值范围约为[-2¹²S,2¹²83;]~[-1.7*1e38,1.7*1e38],FP16的取值范围大约为[-2⁵,2'8309]=[-32768,32768]。请注意,FP32的十进制指数在0到255之间,我们排除了最大值0xFF,因为它表示NAN。这就解释了为什么最大的十进制指数是254–127=127。当然,类似的规则也适用于FP16。
对于精度方面,请注意指数和尾数都有助于精度限制(也称为非规范化,请参阅链接处的详细讨论)。因此,FP32可以表示高达2^(-23)*2^(-126)=2^(-149)的精度,FP16可以表示高至2^(10)*2^。
FP32和FP16表示之间的差异带来了混合精度训练的关键问题,因为深度学习模型的不同层/操作对值范围和精度或者不敏感或者敏感,所以需要单独解决。
混合精度训练
前面,我们已经学习了MMA的硬件基础知识、张量核的概念以及FP32和FP16之间的关键区别。接下来,我们可以进一步讨论混合精度训练的细节。
混合精度训练的想法最早是在2018年ICLR论文《混合精度训练》(Mixed Precision Training)中提出的。该论文在训练过程中将深度学习模型转换为半精度浮点,而不会损失模型精度或修改超参数。如上所述,由于FP32和FP16之间的关键区别在于值范围和精度,该论文详细讨论了FP16为什么会导致梯度消失,以及如何通过损失缩放来解决这个问题。此外,该论文还提出了使用FP32主权重拷贝和使用FP32进行归约和向量点积累加等特定操作的技巧。
损失缩放(Loss scaling)。本文给出了一个使用FP32精度训练Multibox SSD探测器网络的示例,如下所示。如果不进行任何缩放,FP16梯度的指数范围≥2^(-24),以下所有值都将变为零,这与FP32相比是不够的。然而,通过实验,将梯度简单地缩放2³=8倍,可以使半精度训练精度恢复到与FP32相匹配的水平。从这个意义上讲,作者认为[2^(-27),2^(-24)]之间的额外百分之几的梯度在训练过程中仍然很重要,而低于2^(-27)的值并不重要。
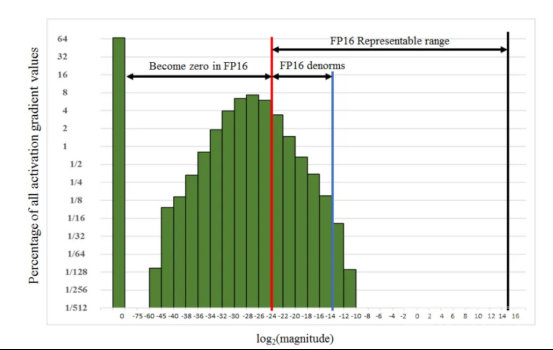
在Multibox SSD训练示例中使用FP32精度的梯度值范围。请注意,[2^(-27),2^(-24)]之间的值超出了FP16非规范化范围,仅占总梯度的百分之几,但在整体训练中仍然很重要。图像来源:https://arxiv.org/pdf/1710.03740
解决这种规模差异的方法是借助损失缩放的办法。根据链式法则,缩放损失将确保相同的量将缩放所有梯度。但是请注意,在最终权重更新之前,需要取消缩放梯度。
自动混合精度训练
Nvidia公司首先开发了名为APEX的PyTorch扩展自动混合精度训练,然后被PyTorch、TensorFlow、MXNet等主流框架广泛采用。请参阅链接处的Nvidia文档。为了简单起见,我们只介绍PyTorch框架中的自动混合精度库:https://pytorch.org/docs/stable/amp.html.
amp库可以自动处理大多数混合精度训练技术,如FP32主权重复制。开发人员只需要进行操作数自动转换和梯度/损失缩放。
操作数自动转换:尽管我们提到张量核可以大大提高GEMM操作的性能,但某些操作不适合半精度表示。
amp库给出了一个符合半精度条件的CUDA操作列表。amp.autocast完全涵盖了大多数矩阵乘法、卷积和线性激活运算;但是,对于归约/求和、softmax和损失计算等,这些计算仍然在FP32中执行,因为它们对数据范围和精度更敏感。
梯度/损失缩放:amp库提供了自动梯度缩放技术;因此,用户在训练过程中不必手动调整缩放。链接处可以找到缩放因子的更详细的算法。
一旦缩放了梯度,就需要在进行梯度剪裁和正则化之前将其缩小。更多细节可以在链接处找到。
FashionMNIST训练示例
torch.amp库相对易于使用,只需要三行代码即可将训练速度提高2倍。
首先,我们从一个非常简单的任务开始,使用FP32在FashionMNIST数据集(MIT许可证)上训练ResNet50模型;我们可以看到10个世代的训练时间为333秒:
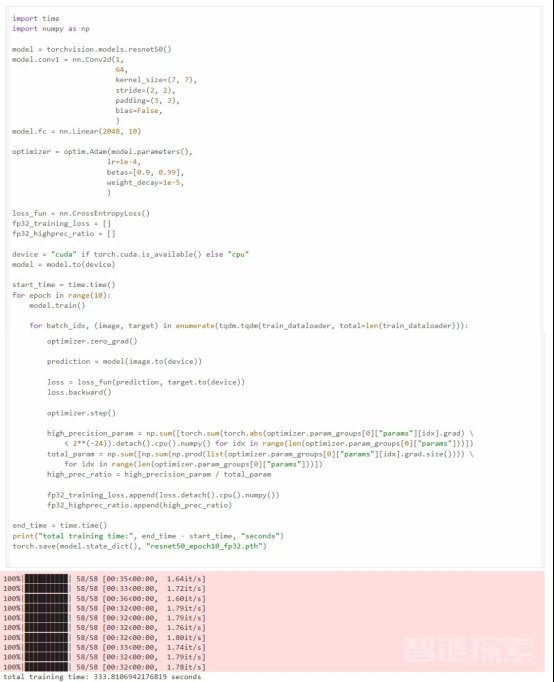
ResNet50模型在数据集FashionMNIST上的训练
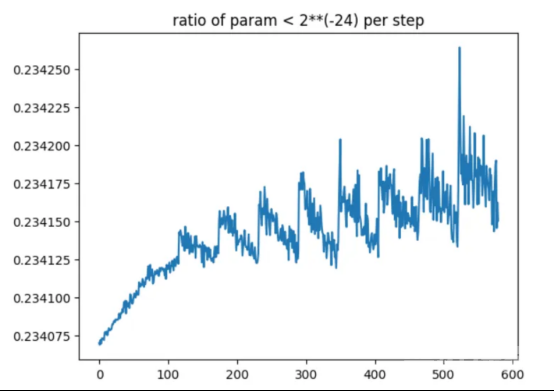
小于2**(-24)的梯度与总梯度之比。我们可以看到,FP16将使总梯度的近1/4变为零
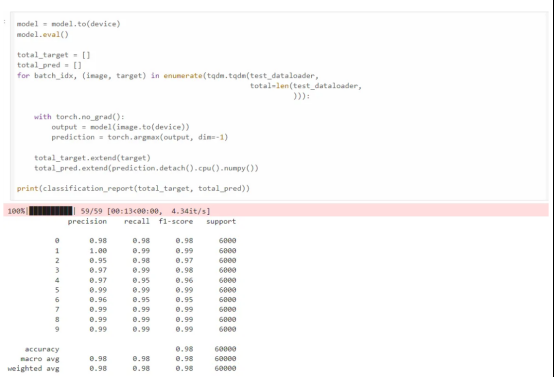
评估结果
现在,我们使用amp库。amp库只需要三行额外的代码进行混合精度训练。我们可以看到训练在141秒内完成,比FP32训练快2.36倍,同时达到了相同的精确度、召回率和F1分数。
scaler = torch.cuda.amp.GradScaler() #开始训练的代码 # ... with torch.autocast(device_type="cuda"): #训练代码 #封装损失与优化器 scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()1.2.3.4.5.6.7.8.9.10.11.
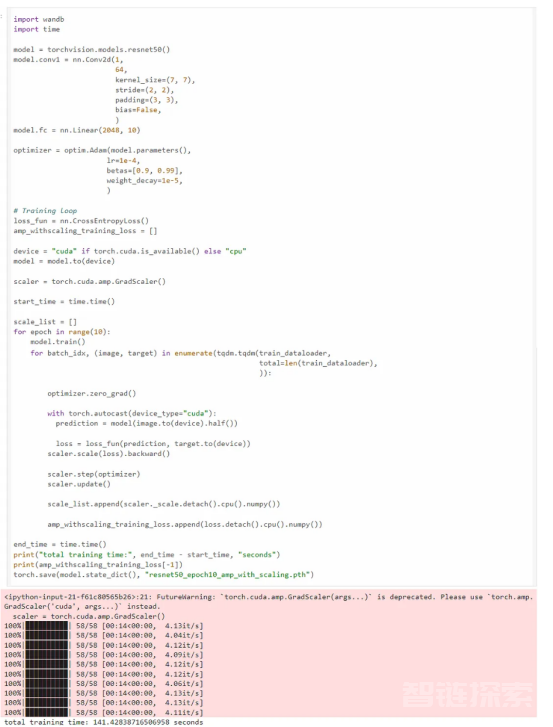
使用amp库进行训练
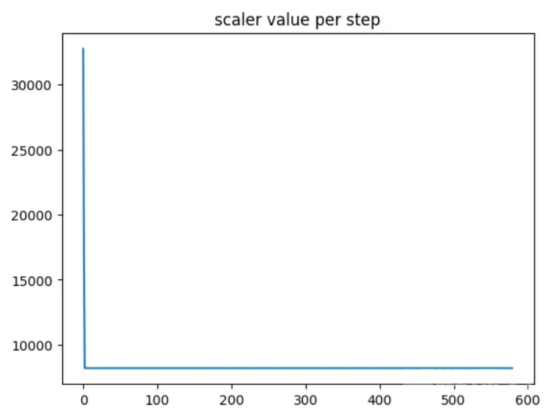
训练期间的缩放因子(缩放因子仅在第一步发生变化,保持不变。)
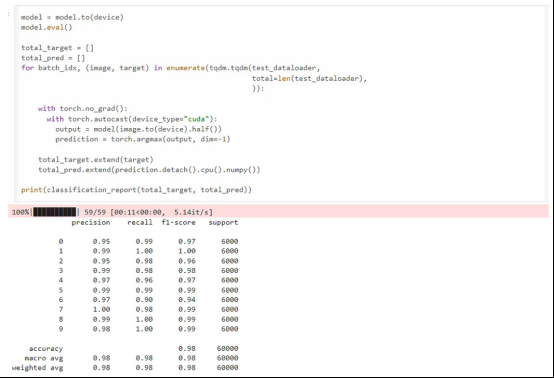
最终结果与FP32训练结果比较
上面代码的Github链接:https://github.com/adoskk/MachineLearningBasics/blob/main/mixed_precision_training/mixed_precision_training.ipynb。
总结
混合精度训练是加速深度学习模型训练的一种非常有价值的技术。它不仅加快了浮点运算的速度,还节省了GPU内存,因为训练批次可以转换为FP16,从而节省了一半的GPU内存。另外,借助于PyTorch框架中的amp库,额外的代码可以减少到仅仅三行,因为权重复制、损失缩放、操作类型转换等计算都是由该库内部处理的。
需要注意的是,如果模型权重大小远大于数据批次的话,混合精度训练并不能真正解决GPU内存问题。首先,只有模型的某些层被转换成FP16,而其余层仍在FP32中计算;其次,权重更新需要FP32复制,这仍然需要占用大量的GPU内存;第三,Adam等优化器的参数在训练过程中占用了大量GPU内存,而混合精度训练使优化器参数保持不变。从这个意义上说,需要更先进的技术,如DeepSpeed的ZERO算法。




还没有评论,来说两句吧...