

我们很幸运生活在AI时代。人工智能迅速发展,现在变得更加易于获取。大多数开源模型都经过了充分的训练,拥有来自广泛类别的合理数量的数据,因此我们可以生成许多不同类别的图像。如果模型从未学习过我们想要生成的特定主题怎么办?例如,我想要生成我今天早上刚做的蛋糕的图像。尽管模型可以生成无数种蛋糕图像,但模型不知道如何生成我刚刚制作的蛋糕的图像。

尽管从头开始训练对个人来说几乎是不可能的,但由于不断发展的模型微调技术,将新主题纳入模型可以轻松实现。自2022年以来,Stable Diffusion作为最新趋势的一代模型,为图像生成开启了一个全新的时代。在本文中,我想分享如何使用现代技术LoRA逐步微调Stable Diffusion模型的指南。整个练习在Kaggle笔记本上进行,这样每个人都可以在没有适当设备的情况下完成这个练习。
在我们开始实现之前,让我们快速了解一下Stable Diffusion的概念和微调技术LoRA。如果你已经熟悉背后的知识,请随时跳到实施部分。
Stable Diffusion

图1. Stable Diffusion中的反向扩散
Stable Diffusion是一种可以从文本和图像生成逼真照片的生成性AI模型。扩散模型在潜在空间而不是图像空间中施展魔法,这使得图像生成对公众来说更加可行,因为所需的计算能力更低。人们甚至可以在CPU机器上的小憩期间生成一个不存在的图像。
有许多在线的稳定扩散平台供公众和开发者使用,如HuggingFace¹和Stable Diffusion Online²。我们可以在没有机器学习知识的情况下生成图像。
LoRA(低秩适应)
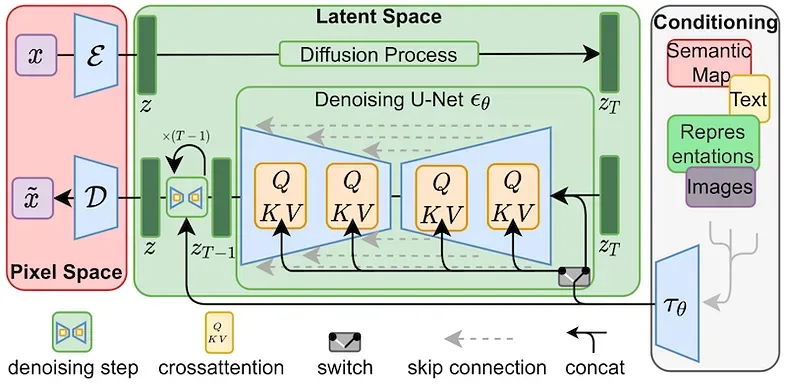
图2. Stable Diffusion网络
LoRA是一种微调方法,它在稳定扩散网络的交叉注意力层中添加了额外的权重。交叉注意力层在图2中由黄色块表示。交叉注意力层融合了图像ZT和文本τθ的中间信息。向交叉注意力层添加权重扩展了文本提示和图像之间的相关性。这就是LoRA如何向稳定扩散模型引入新知识。
修改后的权重被分解为更小的(低秩)矩阵。这些较小的矩阵携带的参数更少,并单独存储。这就是为什么LoRA权重文件的尺寸可控,但必须与底层的Stable Diffusion模型一起使用。
LoRA的权重大小通常在2到200 MB之间。这是共享和管理模型的优势之一。与其以几GB的整个模型共享,更有效的方法是以更小的尺寸共享LoRA权重。
环境
这个练习是在Kaggle笔记本中进行的,环境设置如下:
NVIDIA Tesla P100 (RAM=16G)
diffusers-0.30.0.dev0
Pytorch 2.1.2
Python 3.10
Kaggle笔记本已经安装了Python和PyTorch。我们需要安装的唯一库是来自HuggingFace的Diffusers。我们可以使用以下命令从源安装Diffusers。从源安装确保了库的最新版本。路径/kaggle/working是Kaggle运行时的默认工作空间。人们可以调整路径以适应自己的开发环境。
实验在这个练习中,我想向模型介绍蜡笔小新雕像。让我们在以下各节中经历步骤。
第1步:数据收集

图3. 训练样本
首先,我们需要收集一些主题的图像。在这个练习中,我们收集了25张蜡笔小新雕像的照片作为我们的训练数据。一些样本可以在图3中找到。以下是我遵循的数据收集推荐提示:
统一图像大小:例如,512x512。
高图像质量:图片以12M分辨率拍摄。
保持主题在图像中心。
此外,训练集中尽可能多地覆盖多样性也很重要,以便模型学习一般特征,如角色的眼睛、发型和身材。换句话说,我们希望模型学习什么是蜡笔小新雕像,而不是特定着装风格(例如红衬衫和黄色短裤)和姿势(例如站立)。
我已经在5、15、25的培训规模上进行了实验。尽管每一轮之间只有10张图像的差异,但模型的泛化程度有了显著提高。
第2步:基线评估
在开始训练之前,我们想检查一下预训练模型是否已经知道我们想要微调的特定雕像,使用上述Python脚本。
AutoPipelineForText2Image类用于加载Stable Diffusion预训练模型stable-diffusion-v1–5。
接下来,我们将文本提示设置为“A crayon shin-chan figurine”。我保持文本提示简洁,以便文本信息对模型来说直接了当。
将提示和推理次数传递给AutoPipelineForText2Image的实例并进行生成过程。

图4. 基线评估结果
脚本多次运行,图4中展示了三个生成的图像。结果显示,预训练模型知道可能是一个人角色的雕像,但不知道前缀‘crayon shin-chan’具体指的是哪个角色。生成图像中的限制验证了我们微调工作的努力,因为我们的倡议是用一个未见过的主体来微调模型。
第3步:微调

图5. 蜡笔
定义一个新的标识符
除了收集一些训练图像外,我们还需要为这个主题选择一个新的名称。每当新名称出现在文本提示中时,修改后的模型就会理解它指的是新的主题,并相应地生成内容。
我们为什么需要一个新的名称?原始名称Crayon Shin-Chan不是更具代表性吗?我们这样做的想法是,我们需要一个独特的名称,不要与已经训练的其他现有名称混在一起。在我们的例子中,内部的蜡笔暗示了与我们用于绘画的蜡笔的潜在联系。如果关联的文本提示包含Crayon Shin-Chan,生成的图像可能包括与蜡笔相关的内容。
建议使用随机名称作为新标识符。我为这个练习选择了aawxbc这个名字,它几乎不会与任何现有名称重叠。其他人也可以为新主题使用任何其他独特的名称。
训练

图6. 模型生成的类别图像
在Kaggle笔记本中,除了工作区:/kaggle/working/,另一个常用的目录是/kaggle/input/,我们在这里存储工作的输入,如检查点和训练图像。以下是基于脚本train_dreambooth_lora.py的完整训练命令。
让我们经历一些关键配置:
mixed_precision [可选]:选择平台支持的精度。选项有fp32、fp16和bf16。
class_prompt [可选]:存储类别数据的提示和文件夹。在这个实验中,类别名称是figurine,因为我们希望扩散模型学习一种新的雕像类型。
class_data_dir [可选]:存储模型生成的类别图像的目录。在我们的例子中,模型生成了一般的雕像图像并将其保存在这个目录下。
instance_prompt [必须]:我们为新主题定义了一个文本提示。格式是{新名称} {类别名称},例如aawxbc figurine、uvhhhl cat等。
instance_data_dir [必须]:存储训练样本的目录。在这个练习中,我们将前面提到的25个样本上传到这个目录。
num_train_epochs [可选]:训练的轮数。
通过遵循上述步骤,包括数据收集、安装库和完成训练,我们现在可以在由output_dir定义的目录中找到LoRA权重pytorch_lora_weights.safetensors。权重文件的大小为3.2 MB,相当容易管理。
第4步:推理—生成新图像
在成功导出LoRA权重后,我们可以进入最后也是最令人兴奋的部分:生成新图像。请注意,LoRA权重不能独立工作,因此我们需要同时加载原始的稳定扩散和LoRA权重文件。
在Python脚本中,除了我们在基线评估中使用的步骤外,我们还有一个额外的步骤,使用.load_lora_weights()函数加载LoRA模型,传入目录和LoRA权重文件的名称。

图7. 使用提示生成的图像:“沙滩上的aawxbc雕像,戴着帽子”
对于文本提示,我们在脚本中包含了标识符aawxbc和类别名称figurine。两组相应文本提示生成的图像分别在图7和图8中展示。我们可以看到,经过微调的模型可以生成蜡笔小新雕像。

图8. 使用提示生成的图像:“森林里的aawxbc雕像,拿着杯子。”
我们可以通过注释掉加载LoRA权重的行并保持文本提示不变来进一步交叉验证新模型。我们可以看到原始的稳定扩散模型无法正确解释标识符aawxbc,这与基线评估一致,并突出了LoRA模型的贡献。
总结
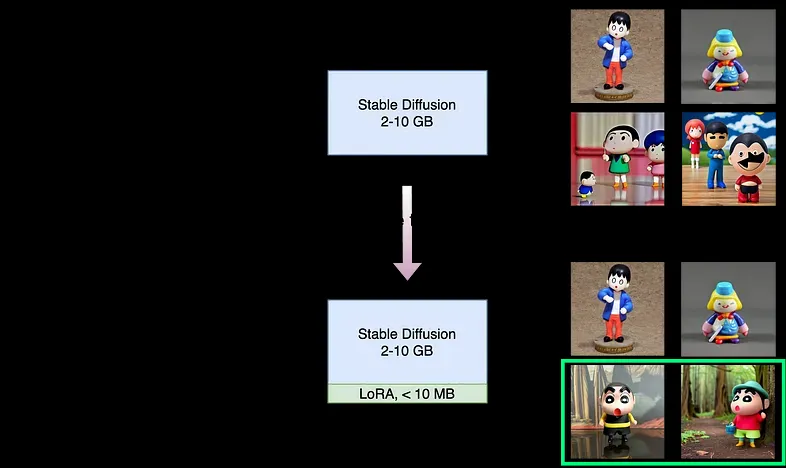
图9. 微调概述
工作的概述在图9中展示。新模型结合了LoRA权重,并且可以生成带有新实例名称aawxbc的蜡笔小新雕像的图像,如绿色矩形突出所示。我们所要做的就是收集足够的图像,并用不存在的标识符命名新主题。就这些。所有的艰苦工作都在代码中完成了。
参考文献:
[1] https://huggingface.co/spaces/stabilityai/stable-diffusion
[2] https://stablediffusionweb.com/




还没有评论,来说两句吧...