

目前用于人类生成相关的「可动画3D感知GAN」方法主要集中在头部或全身的生成,不过仅有头部的视频在真实生活中并不常见,全身生成任务通常不会控制人物的面部表情,并且很难提高生成质量。
为了提高视频化身(video avatar)的可应用性,来自港科大、清华等机构的研究人员提出了一个新模型AniPortraitGAN,可以生成具有可控面部表情、头部姿势和肩部运动的肖像图像;训练过程只依赖非结构化的2D图像,无需3D或视频数据。

论文链接:https://arxiv.org/pdf/2309.02186.pdf
该方法基于生成辐射流形表征,配备了可学习的面部和头肩变形;引入了一种双摄像头渲染和对抗学习方案以提高生成的人脸的质量,对于人像生成来说至关重要;开发了一个姿势变形处理网络,以在困难的区域生成合理的变形,如长发等。

实验结果表明,该方法在非结构化的2D图像上训练,可以生成不同的和高质量的3D肖像与所需的控制不同的属性。
方法概述
研究人员的目标是通过对给定的2D图像集合进行训练,来生成包含人类头部和肩部区域的肖像图。
模型架构与标准GAN类似,对随机潜码进行采样,并将其映射到最终输出图像中,其中生成器的输入包括多个潜码,对应于生成人物的不同属性以及相机视角,输出为带有预期属性的人物肖像。
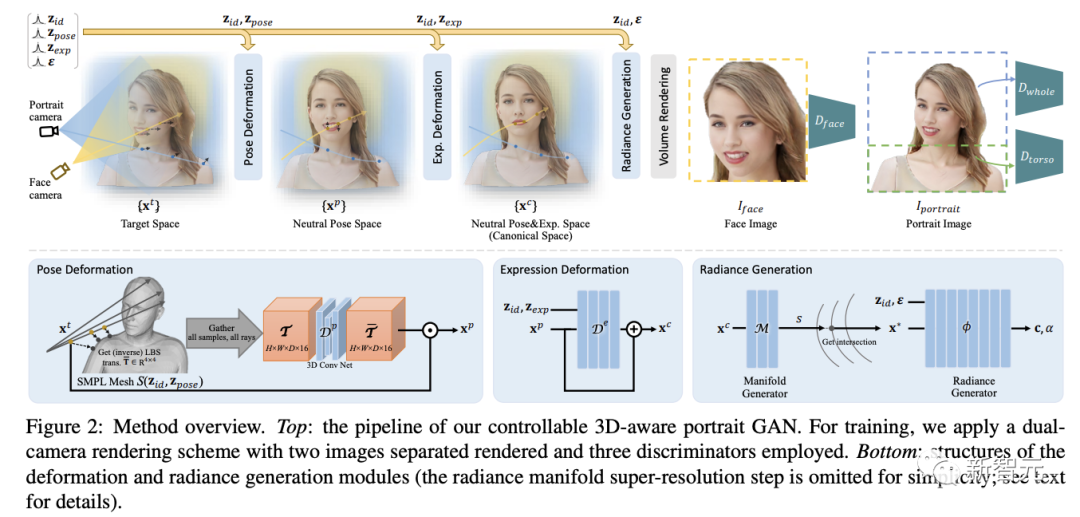
整个过程遵循规范神经辐射(canonical neural radiance)表征与(逆)变形(deformation)相结合的常用范式。
1. 潜码
包括用于人物身材的身份编码(identify code)、用于面部表情的编码、用于身体和肩膀姿态的编码、以及一个额外的噪声用于控制其他诸如外貌(appearance)等属性的编码。
为了实现语义上的可控,研究人员采用之前的3D人体参数模型,并将二者的潜空间对齐。
具体来说,将身份编码设计为3DMM面部身份系数和SMPL身材系数的级联;姿态编码是一个简化的SMPL姿态参数,包括6个关节的联合变换:头部、颈部、左右衣领和左右肩膀;表情编码与3DMM表情系数相同。
2. 经典辐射流形(Canonical Radiance Manifolds)
研究人员使用辐射流形来表示普通的人类特征(canonical humans),该表征可以控制辐射场在一组3D隐式表面上的学习和渲染,能够生成具有严格多视图一致性的高质量人脸。
具体来说,模型使用三个网络来生成辐射:
1)流形预测MLP以正则空间(canonical space)中的点为输入,预测结果为一个实数标量来定义表面。
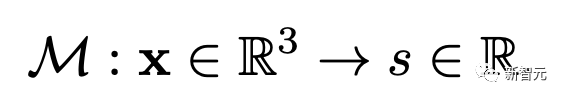
2)辐射生成MLP基于身份编码、噪声和视图方向来生成表面点的颜色和透明度。
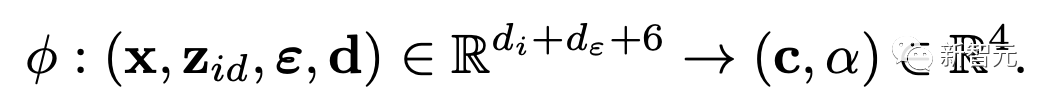
3)流形超分辨率CNN,将平坦、离散的辐射图(128*128)上采样到高分辨率(512*512)辐射图。
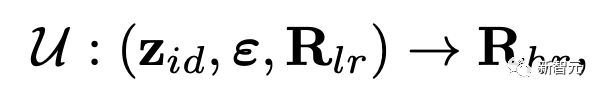
3. 变形域(deformation)
对于目标空间中具有预期头肩姿势和面部表情的每个采样3D点,都应用变形操作将其转换到用于辐射检索的规范空间。
姿态变形生成器(pose deformation generator)
结合SMPL模型,使用其线性混合蒙皮(LBS)方案来引导姿态变形。
给定形状编码和姿态编码,可以使用SMPL构建姿态人体网格,为身体表面上的每个顶点提供预定义的蒙皮权重向量。
一种将身体变形传播到整个3D空间的简单方法是给每个点都分配到最近身体表面顶点的蒙皮权重,再进行变形;不过这种策略虽然广泛用于最先进的可动画人体建模和生成方法,并且可以给出合理的全身合成结果,但在高分辨率人像合成中存在明显的视觉缺陷。
对于长头发的人类角色,该策略会导致肩膀以上的头发区域出现明显的变形不连续性。
研究人员提出了一个可变形体积处理(deformation volume processing)模块来解决这个问题,对于目标空间中,从最近SMPL身体顶点取回的,蒙皮权重向量为w的一个点x^t,变形后的点可以通过逆LBS计算得到:
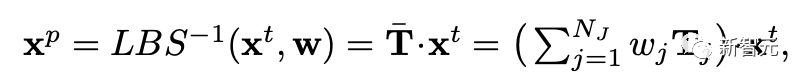
经过处理后,对变换进行reshape,并将其应用于采样点以完成姿态变形。
表情变形生成器(Expression Deformation Generator)
研究人员引入了一个由3DMM模型引导的变形场,具体来说,利用MLP对位姿空间(pose-aligned space)中的点进行变形,训练目标是根据3DMM生成带表情的人脸。
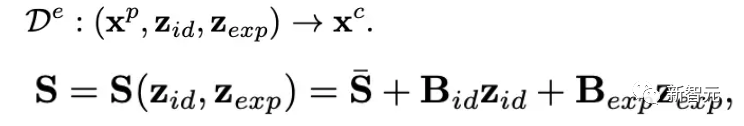
4. 双相机判别器(Dual-Camera Discriminator)
之前的3D感知头部GANs已经通过仔细地将生成的和真实的人脸图像居中对齐以进行训练,已经展现出了非常高的人脸生成质量。
但头部区域是肖像图的一部分,其空间位置和方向变化很大,简单地应用全图像鉴别器不能为高质量的人脸生成提供足够的监督信号,而高质量的人脸生成对于肖像图是至关重要的。
一个直接的补救措施是裁剪和对齐渲染图像中的人脸,并应用局部人脸鉴别器,但图像重采样算子本质上是低通的(low-pass),图像空间裁剪策略会让裁剪的人脸更模糊,对GAN的训练是有害的。
研究人员设计了一个双摄像头渲染方案用于GAN训练,除了用于完整人像图像渲染的主摄像机之外,还添加了另一个用于面部渲染的摄像机,放置在头部周围,并指向头部中心。
模型在设计上和以前3D感知头部GANs具有相同的局部坐标系,并且位置可以使用变形的SMPL头部计算。
另一个可能的想法类似2D人体生成方法,混合两个独立的面部和身体生成器的输出,但将这种策略应用到3D动画案例中并不容易。
添加用于训练的专用人脸相机不仅避免了图像重采样,并为规范辐射流形提供了更直接的监督,而且还实现了用于对抗性学习的更高分辨率的人脸渲染,因此,辐射生成器可以接收到对面部区域更强的监督信号。
5. 训练损失
对抗学习(Adversarial Learning)
将具有R1正则化的非饱和GAN损失应用于3D感知图像生成器和所有三个判别器中,根据经验将平衡权重分别设置为whole=0.1、face=1.0和torso=0.5
变形学习(Deformation Learning)
使用3D landmark损失和模仿损失来获得具有3DMM引导的表情控制,损失强制所生成的人脸图像具有与用所述输入身份和表情代码构造的3DMM人脸相似的3D人脸landmark:
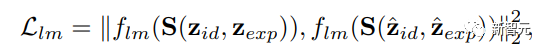
其中zid、zexp是使用人脸重建网络从生成的图像估计的3DMM系数,f_lm表示简单的人脸landmark提取函数。
在变形模仿上,强制输入点x^p的位移在3DMM网格跟随其最近的点x_ref:
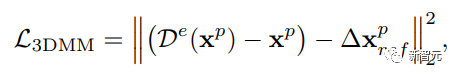
再引入几个变形正则化项:
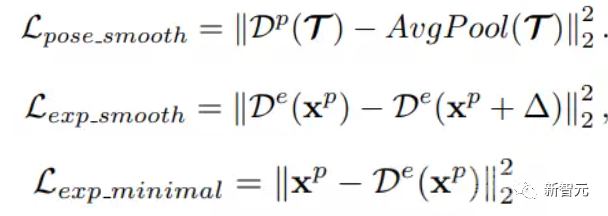
6. 训练策略
研究人员采用两阶段训练策略来训练模型:
先训练一个低分辨率图像生成器和相应的判别器,面部和肖像分支都生成128×128的图像,除了流形超分辨率CNN网络之外,训练所有的子网络。
在第二阶段,生成512×512的肖像图和256×256的人脸,随机初始化和训练高分辨率鉴别器,冻结其他子网络。
实验部分
训练数据
研究人员通过处理SHHQ数据集中的人类图像来构建训练集,原始数据集包含4万张1024×512分辨率的全身图像。
为了获得高质量的头肩肖像,首先在SHHQ图像上拟合SMPL模型,然后裁剪图像,并使用投影的头部和颈部关节对齐,裁剪后的人像图像分辨率约为256×256,再使用超分辨率方法将其上采样到1024×1024后下采样到512 × 512;最后通过分割蒙版来移除背景。
生成结果
模型的生成结果非常多样且高质量,相机视角、面部表情,头部旋转和肩部姿势被明确控制。

在控制属性时,该方法实现了对不同身份的所有四个属性的一致控制。

实验对比
研究人员将该方法与三种最先进的三维感知GANs进行了比较:EG3D、GRAM-HD和AniFaceGAN,因为目前还没有可动画头肩肖像生成任务的模型,所以对比结果也仅供参考。
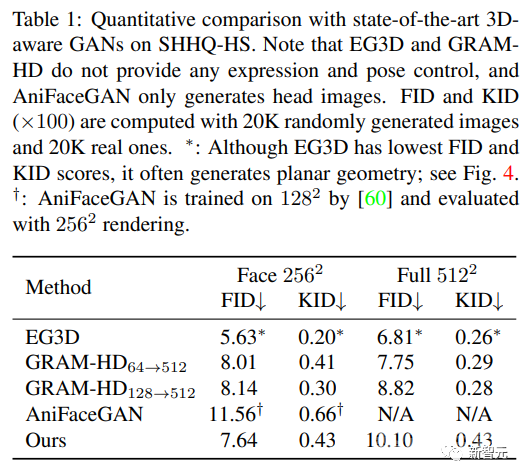
可以看到,在完整肖像图像和面部区域上评估的FID和KID指标中,该方法在人脸方面的得分与EG3D和GRAMHD相当,在全图像方面的得分略低。
值得注意的是,虽然EG3D的得分最低,但研究人员发现该模型经常生成较差的几何形状:人像表面有时几乎是平面的,当改变视角时,视觉视差是错误的。

从视觉上看,文中方法的图像质量与EG3D和GRAM-HD相当,并且肖像具有正确的几何形状,但该方法可以生成和控制更大的区域。




还没有评论,来说两句吧...