


译者 | 陈峻
审校 | 重楼
作为一种能在先进的 RAG(Retrieval-Augmented Generation,检索增强生成)模型中实现的方法,父文档检索(Parent Document Retrieval,PDR)旨在恢复那些可以从中提取到相关子段落(或片段)的完整父文档。此类文档通过将丰富的上下文,传递给 RAG 模型,以便对复杂或细微的问题,做出更全面且内涵丰富的回答。通常,在 RAG 模型中检索出父文档的主要步骤包括:
数据预处理:将冗长的文档分解为多个可管理的片段。
创建嵌入:将片段转换为数值向量,以实现高效的搜索。
用户查询:让用户提交问题。
块检索:模型检索出那些与查询嵌入最为相似的部分。
查找父文档:检索原始文档或从中获取更大的片段。
父文档检索:检索完整的父文档,为响应提供更为丰富的上下文。
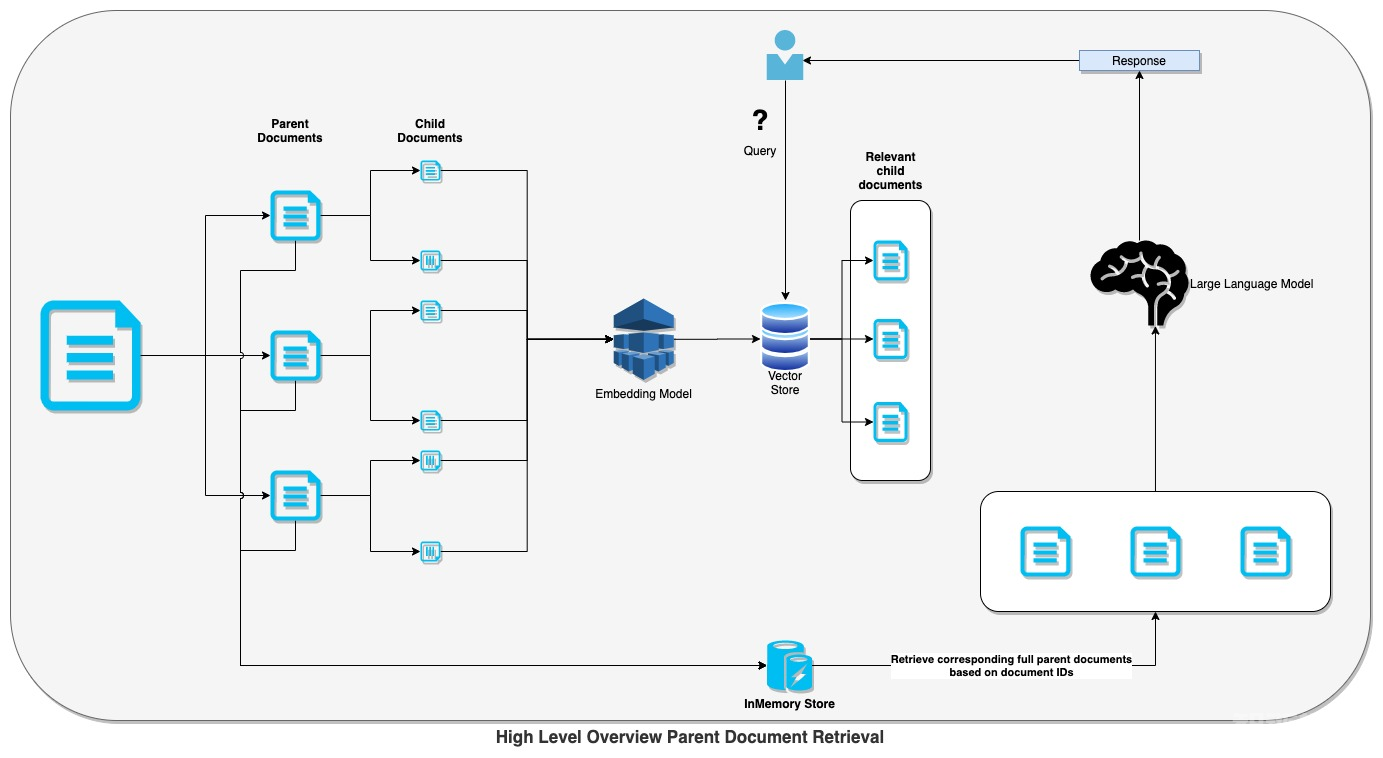
循序渐进的实施
根据上图,我们可以将实现父文档检索的步骤简单分为如下四个不同的阶段:
1. 准备数据
我们首先应为自己的 RAG 系统创建环境并预处理数据,以便对后续的父文档开展文档检索。
(1)导入必要的模块
我们将从已安装的库中导入所需的模块,以设置我们的 PDR 系统:
Python
from langchain.schema import Document from langchain.vectorstores import Chroma from langchain.retrievers import ParentDocumentRetriever from langchain.chains import RetrievalQA from langchain_openai import OpenAI from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.storage import InMemoryStore from langchain.document_loaders import TextLoader from langchain.embeddings.openai import OpenAIEmbeddings1.2.3.4.5.6.7.8.9.
上述这些库和模块正是构成整个过程步骤的主要部分。
(2)设置 OpenAI API 密钥
接着,我们使用 OpenAI LLM来生成响应,为此我们需要一个 OpenAI 的API 密钥。该密钥可被用来设置环境变量:OPENAI_API_KEY。
Python
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"] = "" # Add your OpenAI API key if OPENAI_API_KEY == "": raise ValueError("Please set the OPENAI_API_KEY environment variable")1.2.3.(3)定义文本嵌入函数
通过如下方式,我们利用 OpenAI 的嵌入来表示文本数据:
Python
embeddings = OpenAIEmbeddings()1.
(4)加载文本数据
为了读取想要检索的文本文档,你可以利用类TextLoader来读取文本文件:
Python
loaders = [ TextLoader('/path/to/your/document1.txt'), TextLoader('/path/to/your/document2.txt'), ] docs = [] for l in loaders: docs.extend(l.load())1.2.3.4.5.6.7.2. 检索完整的文档
下面,我们将通过设置系统,来检索与子段落相关的完整父文档。
(1)完整文档的拆分
我们使用RecursiveCharacterTextSplitter将加载的文档分割成比所需大小更小的文本块。这些子文档将使我们能够有效地搜索相关段落:
Python
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)1.
(2)矢量存储和存储设置
下面,我们将使用Chroma向量存储来嵌入各个子文档,并利用InMemoryStore来跟踪与子文档关联的完整父文档:
Python
vectorstore = Chroma( collection_name="full_documents", embedding_function=OpenAIEmbeddings() ) store = InMemoryStore()1.2.3.4.5.
(3)父文档检索器
接着,让我们从类ParentDocumentRetriever中实例化一个对象。该类主要负责完整父文档与基于子文档相似性检索相关的核心逻辑。
Python
full_doc_retriever = ParentDocumentRetriever( vectorstore=vectorstore, docstore=store, child_splitter=child_splitter )1.2.3.4.5.
(4)添加文档
然后,这些加载的文档将使用add_documents方法被馈入ParentDocumentRetriever中,如下代码所示:
Python
full_doc_retriever.add_documents(docs) print(list(store.yield_keys())) # List document IDs in the store1.2.
(5)相似性搜索和检索
至此,检索器已基本实现,你可以在给定查询的情况下,去检索相关的子文档,并获取相关的完整父文档:
Python
sub_docs = vectorstore.similarity_search("What is LangSmith?", k=2) print(len(sub_docs)) print(sub_docs[0].page_content) retrieved_docs = full_doc_retriever.invoke("What is LangSmith?") print(len(retrieved_docs[0].page_content)) print(retrieved_docs[0].page_content)1.2.3.4.5.6.3. 检索更大的数据块
有时,在文档非常大的情况下,我们可能无法获取完整的父文档。对此,可参考如下从父文档获取较大片段的方法:
块和父级文本分割:
使用RecursiveCharacterTextSplitter的两个实例,其中一个用于创建特定大小的较大父文档。另一个具有较小的块大小,可用于创建文本片段,即父文档中的子文档。
矢量存储和存储设置(类似完整的文档检索):
创建一个向量存储Chroma,用于索引子文档的嵌入。
使用InMemoryStore保存父文档的块。
(1)父文档检索器
该检索器可解决 RAG 中的一个基本问题:由于被检索的整个文档过大,而无法包含足够的上下文。为此,RAG需将文档切成小块进行检索,进而对这些小块进行索引。不过,在查询之后,它不会去检索这些文档片段,而是检索整个父文档,从而为后续的生成提供更为丰富的上下文。
Python
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000) child_splitter = RecursiveCharacterTextSplitter(chunk_size=400) vectorstore = Chroma( collection_name="split_parents", embedding_function=OpenAIEmbeddings() ) store = InMemoryStore() big_chunks_retriever = ParentDocumentRetriever( vectorstore=vectorstore, docstore=store, child_splitter=child_splitter, parent_splitter=parent_splitter ) # Adding documents big_chunks_retriever.add_documents(docs) print(len(list(store.yield_keys()))) # List document IDs in the store1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.
(2)相似性搜索和检索
该过程仍然与完整的文档检索类似,我们需要查找相关的子文档,然后从父文档中获取相应的更大文档块。
Python
sub_docs = vectorstore.similarity_search("What is LangSmith?", k=2) print(len(sub_docs)) print(sub_docs[0].page_content) retrieved_docs = big_chunks_retriever.invoke("What is LangSmith?") print(len(retrieved_docs)) print(len(retrieved_docs[0].page_content)) print(retrieved_docs[0].page_content)1.2.3.4.5.6.7.4. 与 RetrievalQA 集成
至此,我们已经实现了一个父文档检索器,你可以将其与RetrievalQA链集成,以使用检索到的父文档进行各种问答:
Python
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=big_chunks_retriever) query = "What is LangSmith?" response = qa.invoke(query) print(response)1.2.3.4.5.6.
小结
综上所述,PDR 大幅提高了 RAG 模型输出响应的准确性,而且这些响应都带有丰富的上下文。而通过对父文档的全文检索,我们可以深入准确地回答各种复杂问题,这也是复杂人工智能的基本要求。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:Parent Document Retrieval (PDR): Useful Technique in RAG,作者:Intiaz Shaik
链接:https://dzone.com/articles/parent-document-retrieval-useful-technique-in-rag。




还没有评论,来说两句吧...