

为了让AI实现终身学习,帝国理工、谷歌DeepMind竟动用了三大基础模型!
「大模型+视觉语言模型+扩散模型」三模并用,构建了全新框架——扩散增强智能体(DAAG)。
DAAG的诞生,就是让具身智能体进行迁移学习、高效探索。

最新框架利用了「后见之明经验增强」(Hindsight Experience Augmentation)技术,让扩散模型以时间和几何一致的方式转换视频。
让其与目标指令对齐,从而对智能体过去经验进行重新标记。

论文地址:https://arxiv.org/pdf/2407.20798
大模型在无需人类监督情况下,自主协调这一过程,使其非常适合终身学习场景。
经过一系列实验,结果表明,DAAG改进了奖励检测器的学习、过去经验的迁移以及新任务的获取。
这些都是开发高效终身学习智能体的关键能力。

无需人类监督,AI终身强化学习
一直以来,具身AI的训练数据极其稀缺,特别是在强化学习场景中尤为突出。
因为这类智能体需要与物体环境进行互动,而传感器和执行器成为了主要瓶颈。
然而,克服这一挑战需要开发出,能够从有限经验中高效学习、适应的智能体。
对此,研究人员假设,具身智能体可以通过利用过去经验,有效探索,并在任务之间转移知识,实现更高数据搬运效率。
即便在没有外部奖励的情况下,他们希望让智能体可以自主设置、评分子目标,并能重新利用之前任务经验,加速新任务学习。
因此,最新研究中,团队成员使用预训练的基础模型Gemini 1.0 Pro来解决这些问题。
通过视觉、语言和扩散模型的相互作用,让智能体更有效推理任务,解释环境和过去经验,并操纵自身收集的数据,以重新用于新任务和目标。
更重要的是,DAAGG可以自主运行,无需人类监督,凸显其特别适合终身强化学习的场景。
如下图1,是扩散增强智能体完整框架。
其中,LLM充当主要控制器/大脑,查询和指导VLM和DM,以及智能体的高级行为。
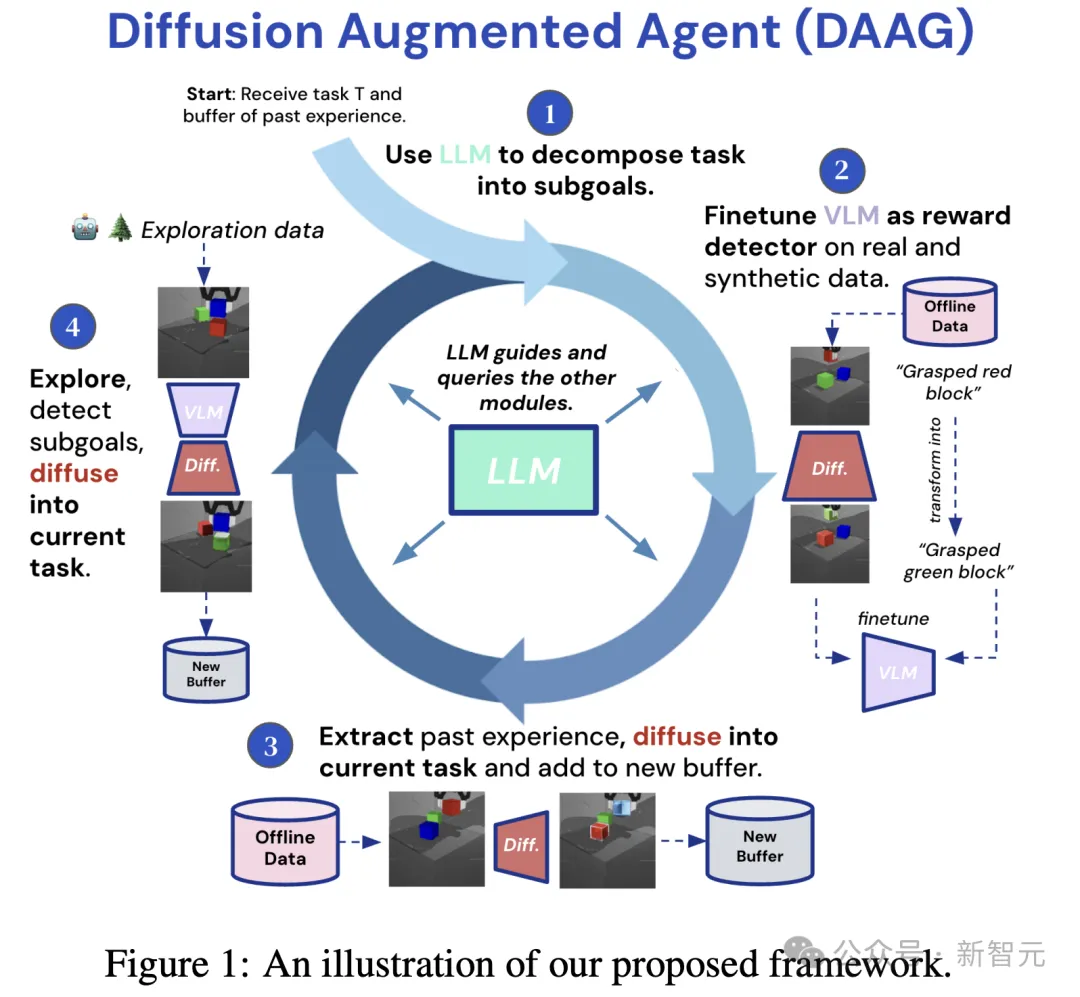
通过一系列在不同环境中的实验,研究人员证明了DAAGG在改进智能体在关键能力上的表现:
1)用扩散模型生成合成样本增强的数据,微调视觉语言模型,自主计算已见和未见任务的奖励;
2)为给定任务设计和识别有用的子目标,通过扩散模型修改记录的观察,重新利用原失败的轨迹,从而更有效地探索和学习新任务;
3)提取相关数据,使用扩散模型重新利用其他轨迹,有效地将先前收集的数据转移到新任务中。
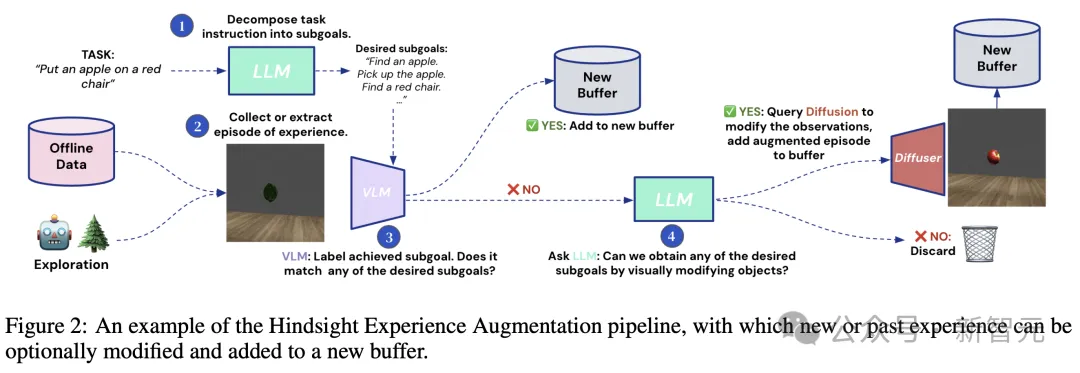
图2所示,DAAGG方法如何通过扩散增强,重新利用智能体的经验。
研究人员提出了一个扩散管道,提高了几何和时间一致性,并修改了智能体收集的部分视频。
方法
DAAGG具体设计方法如下。
研究人员将环境形式化为「马尔可夫决策过程」(MDP):在每个时间步t,环境和智能体处于状态s ∈ S。
从该状态,智能体接收视觉观察o ∈ O,并可以执行动作a ∈ A。
在每个回合中,智能体接收一个指令,这是用自然语言T描述的要执行的任务。
如果任务成功执行,智能体可以在回合结束时,获得奖励r = +1。
这项论文中,除了独立学习新任务外,作者还研究了DAAGG框架以终身方式连续学习任务的能力。
因此,智能体将交互经验存储在两个缓冲区中:当前任务缓冲区,称之为新缓冲区 :这个缓冲区在每个新任务开始时初始化。
:这个缓冲区在每个新任务开始时初始化。
然后是离线终身缓冲区 :智能体将所有任务的所有回合存储在这个缓冲区中,无论它们是否成功。
:智能体将所有任务的所有回合存储在这个缓冲区中,无论它们是否成功。
因此,后者是一个不断增长的经验缓冲区,智能体随后可以用它来引导新任务的学习。
以下是,作者选用的三种模型目的:
- 大模型LLM:编排智能体的行为,以及指导VLM和DM。LLM接受文本指令和数据,并输出文本响应。而且,利用LLM将任务分解为子目标,比较不同任务/指令的相似性,并查询VLM和DM。
- 视觉语言模型VLM:使用的是对比模型CLIP。CLIP由两个分支组成:图像分支和文本分支,它们分别以视觉观察和文本描述作为输入,最终输出相同大小的嵌入向量。
- 扩散Pipeline:研究的核心是通过语言指导的扩散模型,修改视觉观察。扩散Pipeline是为了提取智能体记录的观察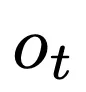 或一系列时间观察
或一系列时间观察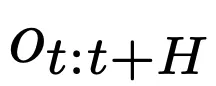 ,并保持几何和时间一致性的同时,修改观察中的一个或多个对象。
,并保持几何和时间一致性的同时,修改观察中的一个或多个对象。
如下是,扩散Pipeline的示意图。
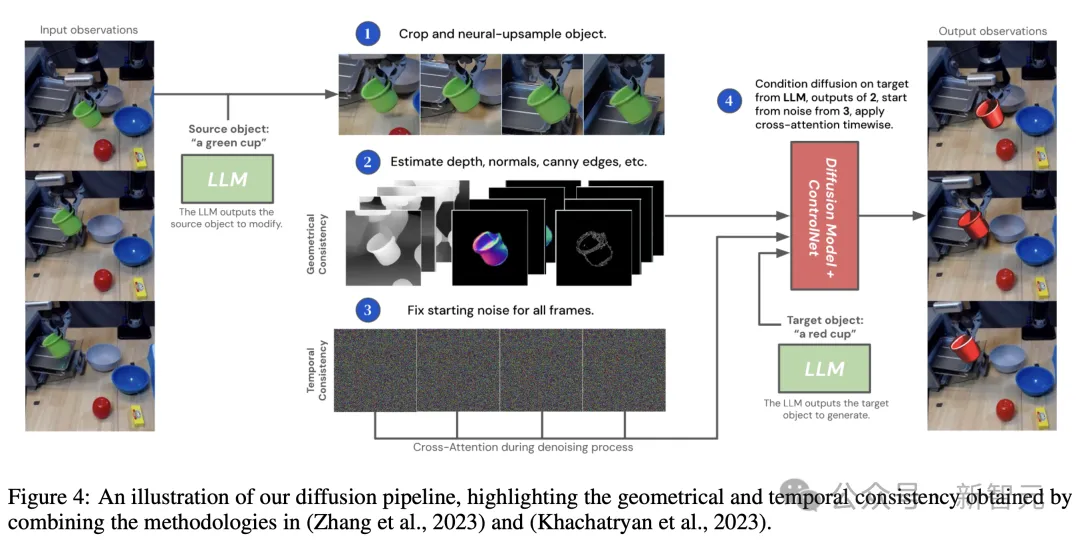
在图5中,作者比较了ROISE和自己提出的Pipeline输出。前者不能保持对象姿势和外观,在帧之间的一致性。

扩散增强智能体框架
在扩散增强数据上,微调VLM作为奖励检测器
VLM可以有效地用作奖励检测器,条件是基于语言定义的目标和视觉观察。
最近的研究显示,为了提升准确性,VLM通常需要在目标环境中收集的token数据上进行微调,适应所需的任务。
这是一个耗时的任务,而且每个新任务需要人类手动完成,严重阻碍了智能体以终身方式自主连续学习的多任务能力。
通过DAAGG框架,作者在先前收集的观察上微调VLM来解决这一挑战。
这个过程如上图2所示,通过这个过程,微调VLM作为LLM分解当前任务的所有子目标 的成功检测器。
的成功检测器。
通过后见之明经验增强,实现高效学习和迁移
在任何任务中收集的每个回合后,智能体收集一系列观察和动作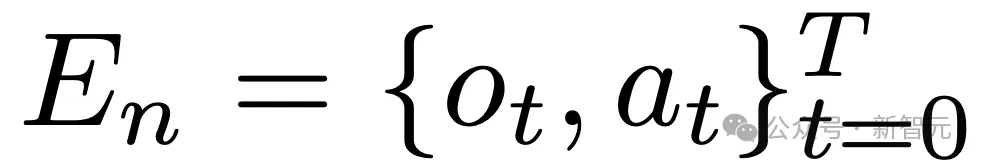 。
。
在DAAGG中,研究人员旨在最大化智能体可以学习处理新任务的回合数量,即使它没有达到任何所需的子目标。
最后,他们通过一个称为后见之明经验增强(HEA)的过程来实现这一点。
实验结果
DAAGG框架提出了LLM+VLM+DM之间的相互作用,以解决终身学习智能体面临的3个主要的挑战:
1)微调新的奖励/子目标检测模型,
2)提取和转移过去经验用于新任务,
3)高效探索新任务。
DAAGG能否将VLM微调为新任务的奖励检测器?
图7显示了,在数据集中没有示例的最左侧任务中,DAAGG如何通过综合其他任务中的示例实现大幅改进,同时在所见的任务中保持相同的性能。
在RGB Stacking和Language Table环境中,物体姿势之间的精确几何关系非常重要,而DAAGG与基线的差异则更为显著,这说明需要进行扩散增强才能获得有效的奖励检测器。
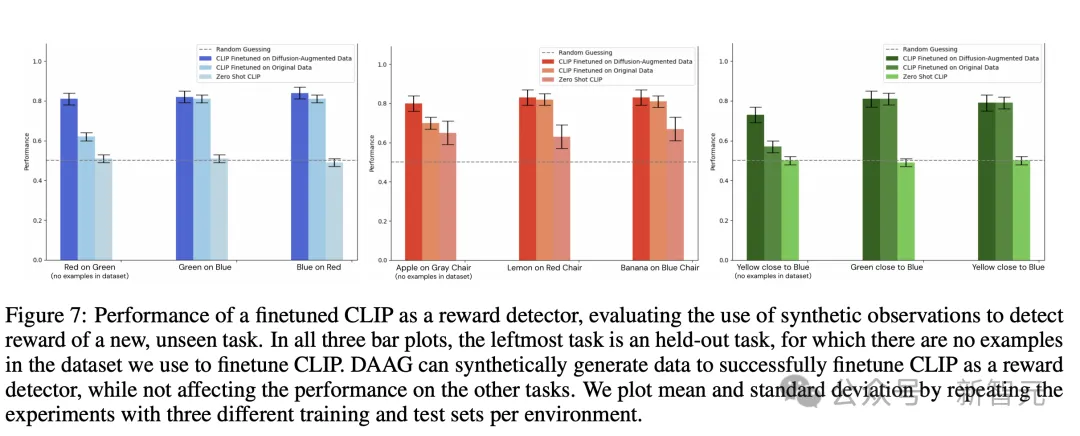
在「房间」环境中,CLIP接收到的观察结果虽然来自低保真模拟器和渲染器,但更接近它在网络规模数据集(水果和家具图片),上进行训练时接收到的观察结果分布。
因此,CLIP「零样本」性能要强得多,而在其他任务中,CLIP零样本性能则接近于随机猜测,这表明有必要进行微调。
DAAGG能否更高效地探索和学习新任务?
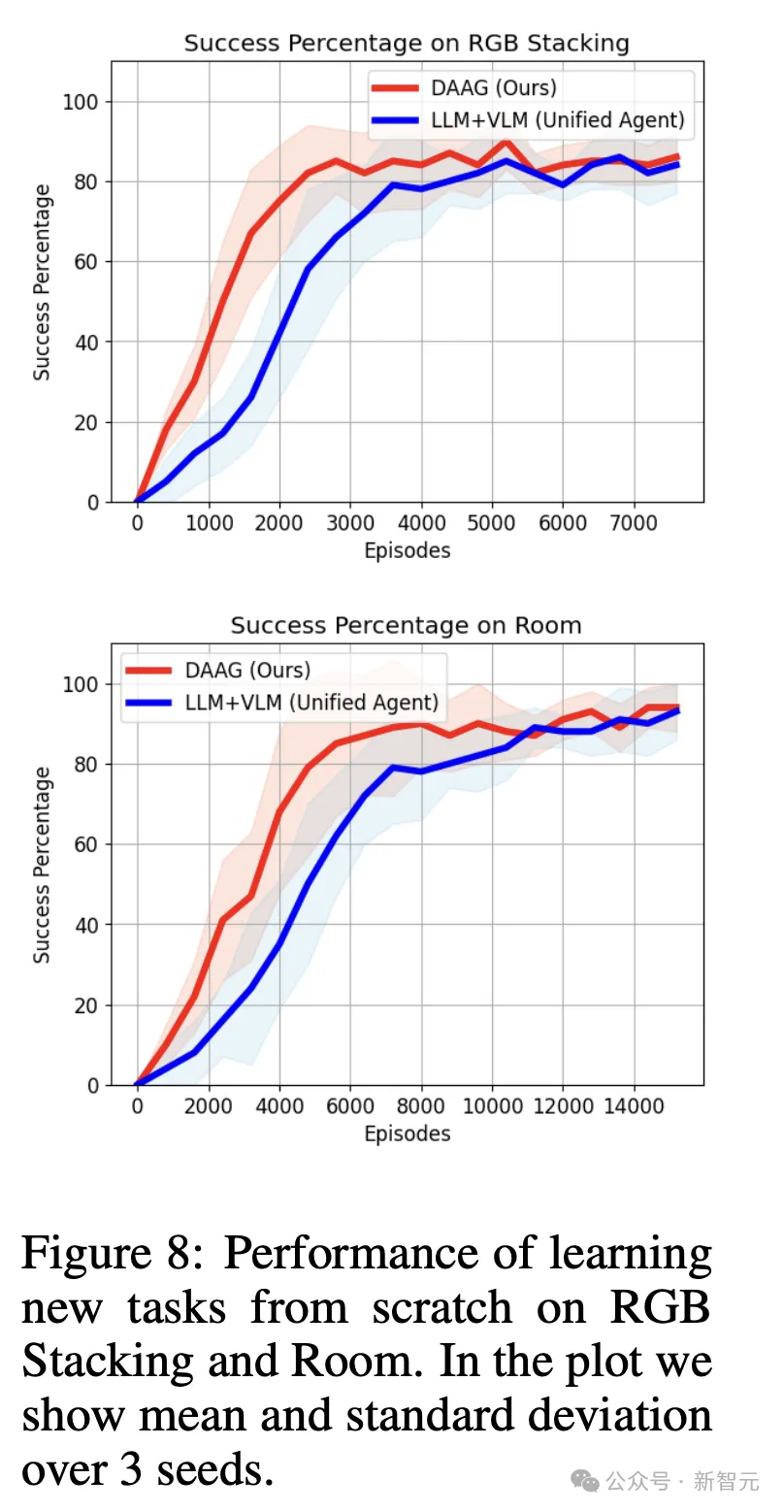
下图8中,作者绘制了100个测试事件中,成功解决任务实例的数量与训练事件数量的函数关系图。
在测试过程中,不执行任何探索策略或指导,而是让策略网络来引导智能体。
可以看到,DAAGG的学习速度比基线更快,将某些不成功的事件作为学习信号的能力,有助于提高在所有测试环境中的学习效率。
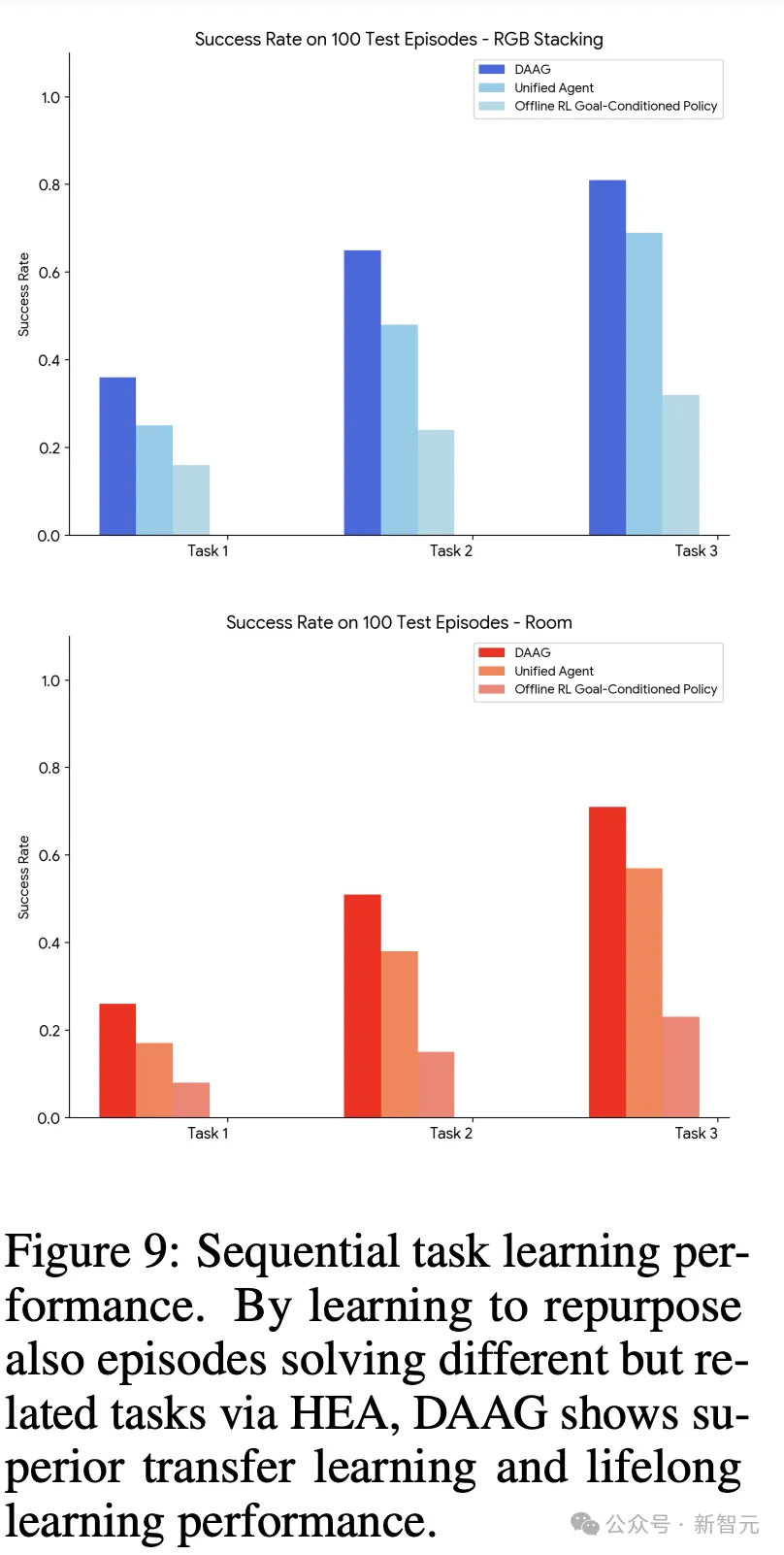
DAAGG能否更有效地连续学习任务,从过去的任务中转移经验?
图9中,研究人员比较了每种方法在使用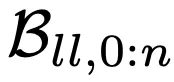 时,在任务
时,在任务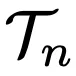 上的性能,性能指标是成功率。
上的性能,性能指标是成功率。
可以看到,DAAGG超越了两个基准方法,主要归功于它能够从存储在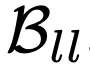 中大部分经验中学习,通过修改和重新利用解决
中大部分经验中学习,通过修改和重新利用解决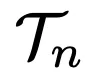 或其子目标
或其子目标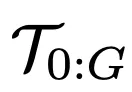 之外的任务轨迹。
之外的任务轨迹。
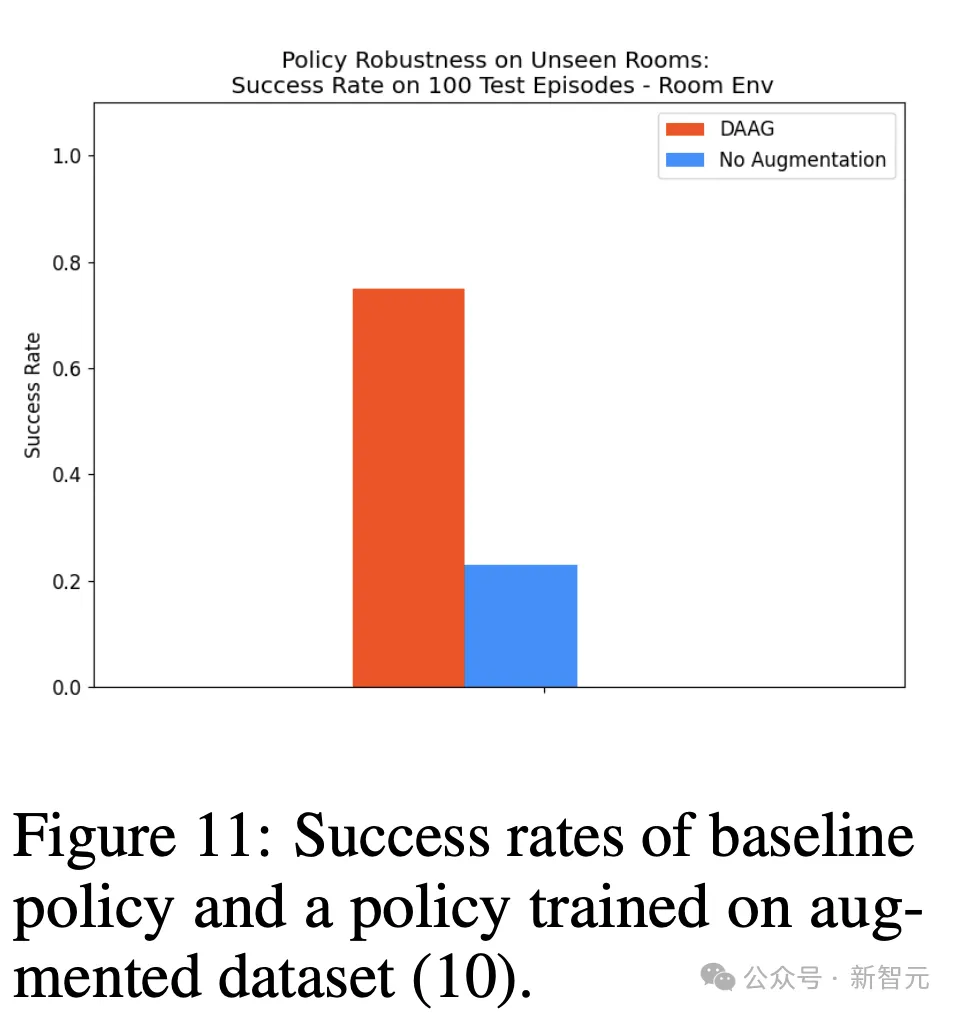
通过场景视觉增强提高鲁棒性
然后,研究人员使用pipeline对每个观察进行5次增强,查询LLM来提出增强的描述(比如,一个有红色地板和白色墙壁的房间)。
作者将所有这些增强的观察添加到缓冲区,并在其上训练策略。
在原始和增强数据集上,训练的策略都在5个视觉上修改的房间中进行测试,随机改变墙壁和地板的颜色以及干扰物体,在每个房间进行20次测试回合。

图11展示了,视觉增强如何带来一个更加鲁棒的策略,能够在视觉上与单一训练Room中,与训练环境很不同的Room中也达到相同目标。
总而言之,这项研究中,作者提出了扩散增强智能体(DAAGG)。
这是一个结合了大型语言模型、视觉语言模型和扩散模型的框架,旨在解决具身AI智能体终身强化学习中的关键挑战。
关键研究结果表明,DAAGG能够在新的、未见过的任务中准确检测奖励,而传统方法在这些任务上难以泛化。
通过重用先前任务的经验,DAAGG能够逐步更高效地学习每个后续任务,得益于迁移学习而需要更少的回合。
最后,通过将不成功的回合,扩散为相关子目标的成功轨迹,DAAGG显著提高了探索效率。




还没有评论,来说两句吧...