

日前,在51CTO主办的WOT全球技术创新大会上,快手高级技术专家欧迪佐带来了主题演讲《LLM-based Agent在B端商业化的技术探索与实践》,围绕着B端商业化的业务场景,详细介绍了构建Agent技术平台的实践经验与深入思考,为观众呈现了全新的视角。
本文将摘选其中精彩内容,统一整理,希望为诸君带来启发。 本文将从以下三个部分展开:
1.大模型应用建设背景
2. SalesCopilot技术平台
3. 大模型应用研发的思考
1.大模型应用建设背景

首先是我们的建设背景,快手的商业化业务中台,所服务的对象包括我们公司内部的一线的销售、运营以及我们的代理商和服务商,业务涉及数据分析的一系列的场景。

在大模型出来之后,我们意识到很多场景都有机会去做智能化升级。
我们可选择的技术方向不少,结合自身的场景,最终选择了做RAG和Agent,前者是知识助手,后者就是智能体。

我们舍弃了其他与自身业务场景无关的部分,比如说AIGC、垂直领域等,保证我们能够聚焦于这两个技术方向上。
2.SalesCopilot技术平台
在做智能化升级的过程中,我们慢慢沉淀出SalesCopilot技术平台。
我们做的第一个应用是我们销帮帮的智能客服。在推进的过程中,我们逐渐意识到我们有机会帮助技术部沉淀一个大模型应用研发平台的。因此,我们一边孵化应用,一边去为我们整个技术平台做架构方面的伏笔。
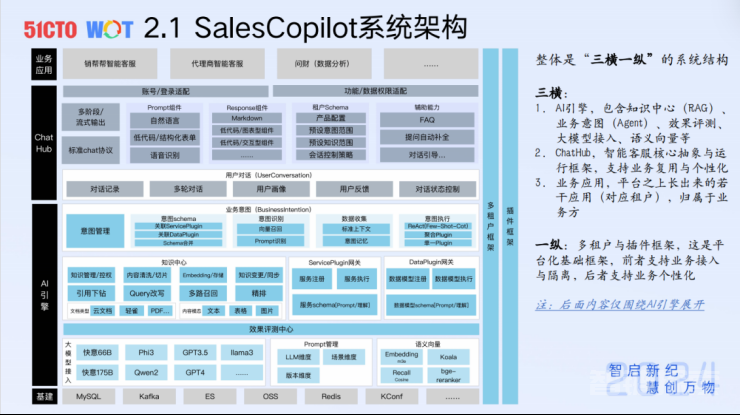
上图为SalesCopilot的系统架构图,在大体上分为四个部分,三横一纵。
三横部分从下面往上看,最核心的部分就是AI引擎的部分。AI引擎包含前面所提到的RAG,这部分会在后面详细展开。还有业务意图(Agent),它起到承上启下的作用——上面连接业务,下面连接各种业务系统。这里还有一个效果评测中心,再加上语义向量相关的一些组件。以上共同组成了AI引擎。
第二层是Chathub,我们目前主要服务的是面向智能客服的场景,所以我们就抽象出ChatHub这层,基于这个框架去接入多个智能客服的能力。
最上面一层是业务应用,所谓的业务应用是以一个租户的身份接入进来,基于租户去做数据隔离、业务个性化等。
一纵,包含两部分:插件框架、多租户框架。这就是我们整个平台化的基础架构。
下面重点讲AI引擎的部分。

第一个部分是RAG。RAG是在大模型应用后,很快被大家识别和接受的技术范式,它在针对大模型的局限性做了有效的补充。这里顺便讲下大模型的几个局限,帮助大家理解。

第一,幻觉问题。在RAG的范式下,我们基于召回,给了LLM一个具有高度确定性的上下文,让它在这个上下文中去组织回答。所以RAG并不能完全消除幻觉,只是极大地缓解幻觉。
第二,大模型的知识时效问题。大模型的训练成本时间成本和经济成本非常高,很容易面临刚训练完就失效了的状态。基于RAG的外挂知识库,它可以做到知识的实时更新。
第三,大模型的记忆容量有局限。这个问题同样可以通过召回加精排解决,把与用户问题最相关的信息提前整理出来,放在一个有限的Prompt里。
第四,数据安全问题。我们在大模型训练时是绝不可能拿到其他企业内部数据的,这也有赖于RAG缓解由此带来的矛盾。
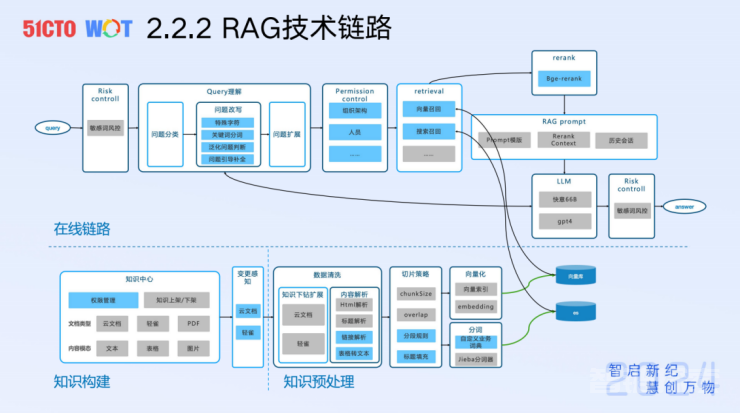
上图为目前整个RAG的技术链路,由四个部分组成。离线链路上知识构建和运营的部分,其是整个RAG运转的重要基础。这里很容易被忽视,在座的各位都是偏技术的同学,我们通常认为把技术链路构建起来,好像就一定能得到一个好的结果,其实不是。如果没有一个专门的团队去做知识的运营、知识质量的保障、知识规模的增长等等,就好比没有油的车一样跑不起来。
第二个部分是知识预处理,这部分比较常规,比如说要做切片、要做Embedding。快手有个比较特殊的情况,我们大部分知识都是以云文档的格式存在的,有对内、对外两种形式。而知识之间经常相互引用,所以我们研发了一个知识下钻的能力,举个实际的例子,200篇知识文档,经过我们的下钻扩展后,最终库里达到700篇。
以上是离线链路。离线链路里会有一个多路召回,这部分呢已经在向量和ES中准备好了。
在线链路的核心由三部分组成。
RAG的R是我们常规的检索。RAG的A是向量召回的部分,也是三部分中的核心。G就是我们最终构建的RAG Prompt,让LLM总结的部分。
我们一直在优化功能。在最开始上线多路召回以后,我们发现这个策略能够在向量上提升70%的效果。随着发展,一定会发现在对Query的理解上需要调整——因为用户对系统的边界、定义是没有感知的,会随意地提出问题。这里就会倒逼我们调整对整个Query的理解,优化应对追问、反问的能力。而这些能力会慢慢成为引导这个系统进一步发展的关键点。
下面来看几个我们自己的案例。

这是整个我们自己做的第一个应用及其效果。

可以看到,销帮帮在整个商业化中覆盖了30%以上的销售人员;在维护知识库方面,五个人的专门团队维护了200多篇知识,而我们通过销帮帮扩展到700多篇;此外,机器人的拦截率达到78%左右。
应用核心就是我们上个月做的多路召回+精排,对效果提升非常显著。建议大家在实际工作中优先尝试。
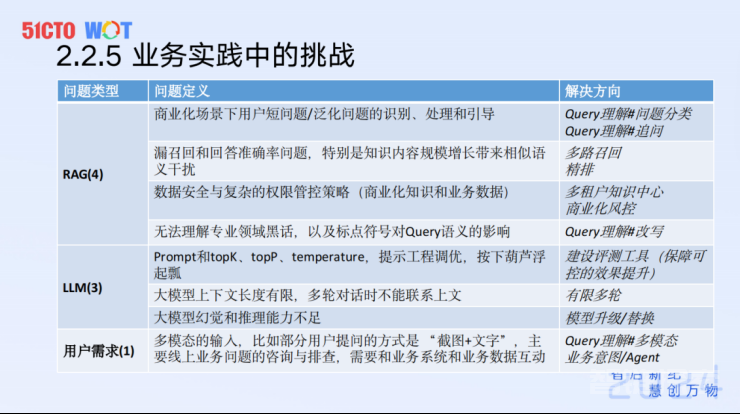
在做业务的过程中,我们会遇到很多挑战,可以分成以下几类。首先是RAG本身的问题,例如用户的提问泛化、不明确。这样的提问很容易被识别为一个Bad Case,但如果我们仔细分析,我们会发现是模型需要一些追问能、问题分类理解的能力。而漏召回、回答准确率的问题,通过多路召回和精排就可以解决。最后是领域黑话带来的问题,需要在垂直领域里去做相关的沉淀。
其次是大模型相关的问题。我们有时候会发现大模型的总结能力特别不靠谱,需要去做相关的Temperature和 Prompt的调整。在调整时,一定要有相对应的评测工具来保障调整后的效果是单调增长的,否则有可能解决了一个问题后,反而使原来好多的Good Case变成了Bad Case。像大模型的上下文长度问题,需要尝试去做一些有限多轮的调整。
最后是用户需求和当前功能的不匹配。例如,我们观测用户使用过程中发现,很多用户与客服的交互是先甩一张图,然后再进行提问。这说明用户在实际使用时,对多模态的需求是非常强烈的。

再讲一下我们Agent的实践。
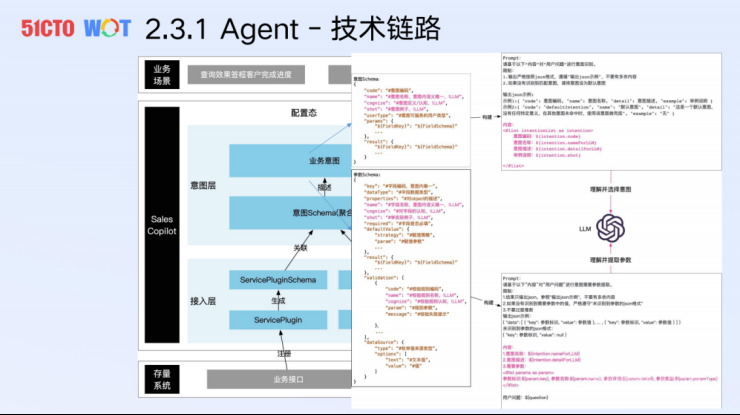
我们现在当前阶段对Agent的理解可能是,比tool use再高级一点。但这不是对Agent的全面的理解,首先,Agent最基本的能力确实有一个tool use的东西,再往上它要连接业务,从本质来看是在回应用户的需求、解决用户任务。所以Agent要下连系统,系统里面有业务接口、数据模型相关的能力。
在运行态的时候,这些信息是如何被关联起来的?主要是设计了一套关于接口和意图的schema的东西。这套schema里包含了很多帮助大模型去理解这些API以及业务意图的信息。

大家可以看红字部分,我们在表达一个业务意图的时候,会有三个概念:名称、描述和举例说明。当你把这些信息组织到Prompt中之后,你会发现,大模型对指令的服从性会提升。
其实,我们最开始实践时,并没有把那个shot(举例)放在一个特别高的位置上,但是这时发现大模型做意图识别时准确度较低。当我们加入了不止一个shot时,意图识别准确率马上就提上来了。
整个意图的执行有三种模式。
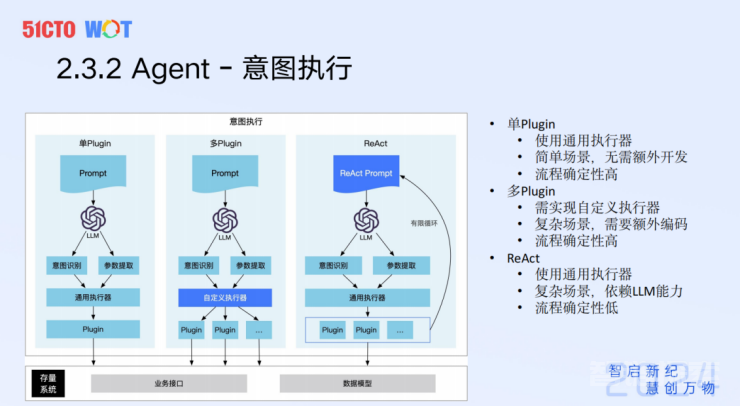
其中,最简单的是所谓的单Plugin,单Plugin就是一个意图直接对应一个API,比如说帮用户搜一个网页、查一下天气,直接把参数拿去执行就可以。
但是实际做业务的时候,不可能这么简单,比如销售说帮我查一下某个客户签合同的进度,这里面可能涉及到这个客户是不是合法的、签的是哪个合同、签了多少钱,再把进度的比例算出来。
所以,我们需要一个多Plugin意图执行能力。目前有两种方式,一种是知道这个意图是什么,提前编排好了大模型的执行逻辑;另一种是大家谈得比较多的ReAct,AI来做推理+执行。不过,我们在实践中发现,虽然推理+执行这个概念特别性感,但稳定性不佳,比如说AutoGPT最好的表现只有50%左右,把这套东西推到线上系统是不可接受的。

这里几个案例中,我们意图执行的方式有两种:一种是通过自然语言的方式去提取用户的意图,然后执行;另一种方式是,识别到用户意图后,通过弹出卡片的方式确认,并快速执行最终任务。

再讲一下,我们关于大模型的关键设计,主要是以下三点。
可插拔,能根据需求快速替换或更新模型,支持多模型协作,让不同任务调用最适合的模型;
LSP,LLM Specific Prompt/模型专用提示LLM各有调性,皆有适合自己的Prompt风格;
量化LLM,量化大模型通过减少参数精度来降低资源需求,仅少量智能损失可跑高性能跑在CPU上。
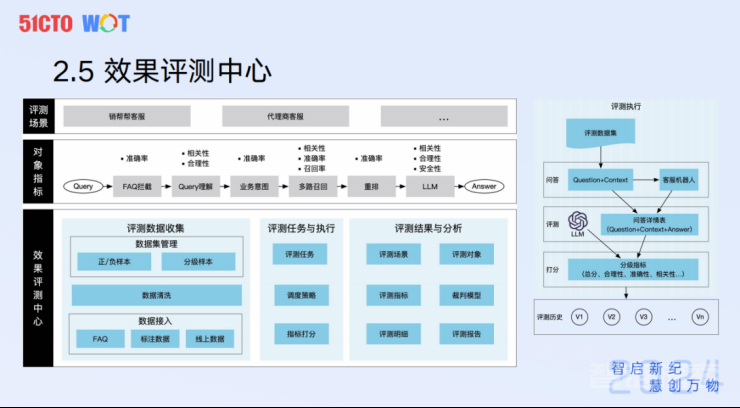
这个就是我们的效果评测中心。需要分享的是,我们在做大模型驱动的应用研发时候,必然面临着不确定,效果永远不会达到100%。必须要匹配相应的评测中心,以保证你的系统是可控的、单调的达到效果的提升。
3.大模型应用研发的思考
最后讲四点思考。
第一,生产力:智能化技术平权。大模型技术实现了智能化技术的普及,使得即使是十个人的小团队也能通过获取大模型服务,快速实现高质量的基础效果,做一个大的项目。除非走到非常深水区的地方,才需要算法的介入。
第二,效果提升:乘积效应(RAG)。RAG通过系统性优化,如Query理解、知识维护和多路召回等关键环节,显著提升了知识问答的效果。但当效果达到70%后,再往上突破就会有一定难度,需要深入的工作。
第三,路径选择:从垂直细分领域开始。我们选择从垂直细分领域开始应用大模型,阶段性地选择优先做标杆应用,同时做架构布局,逐步向成熟的Agent平台发展。相反,如果起步时去做通用化大Agent,则面临研发周期长、用户反馈慢的问题。
第四,需求趋势:多模态。多模态交互将成为Agent发展的趋势,因其符合人类自然交互体验且信息密集,预计随着技术进步,多模态能力将不断提升。




还没有评论,来说两句吧...