

YOLO(You Only Look Once,你只看一眼)因其快速的对象检测算法而闻名。它的速度和效率使其成为计算机视觉(CV)领域中对象检测的标准方法。YOLO 可以实时处理图像,使其非常适合自动驾驶、安全监控和零售分析等应用。
YOLO 是如何工作的?

考虑图像分类的场景,目标是确定图像是否包含狗或人。当涉及到图像分类,我们应该确定它是否是狗还是人 - 如果是狗,就是1,如果是人,就是0,就像上面的图像 - 只有狗存在!但在对象检测算法中 - 我们考虑一种叫做对象定位的东西。除了上述解释的图像分类数据,我们还传递了边界框。
边界框
Pc — 类别的概率,如果两种类别都不出现,它将是0,否则是1。
Bx 和 By — 注释框的中心坐标 - 它将覆盖正好只有类别 - 在这个例子中是狗。
Bw 和 Bh — 注释框的宽度和高度。
C1 — 狗类别 - 因为狗存在 - 它是1。
C2 — 人类别 - 因为人不存在 - 它是0。
显然,如果没有对象 - Pc 将是0,其余的将没有值!
如果我们在图像中有多个对象怎么办?当图像中存在多个对象时,YOLO 将图像划分为网格,然后预测每个网格单元的边界框和类别概率。允许模型同时检测和定位多个对象。例如,如果网格大小是 4x4,每个单元将产生一个预测向量。假设每个预测向量由 7 个单元组成(Pc, Bx, By, Bw, Bh, C1, C2),整体预测张量的大小将是 4x4x7。
如果图像包含重叠对象,如一个人抱着一只狗,也会使用相同的方法。
训练神经网络由于图像及其相应的向量都已获得 - 我们可以将图像样本视为输入数据 - 其相应的向量样本作为输出数据传递给神经网络。现在这些数据样本及其相应的输入和输出矩阵可以输入到神经网络中 - 当涉及到隐藏状态中的节点数量、激活函数等时,可以调整和调整神经网络!获得最佳组合以获得最佳准确率。
输出将是模型所做的网格单元分隔的大小。如果是 4x4,输出将是 16 个向量。
它之所以被称为 YOLO - You Only Look Once - 是因为模型在单次前向传播中完成所有预测。这有效地允许模型快速检测模式和对象,无论网格单元的数量如何。
对象检测模型的问题尽管 YOLO 可以被认为是用于对象检测的最佳模型之一 - 但所有模型都不完美。当涉及到 YOLO 时,可能会有重叠边界框的问题。
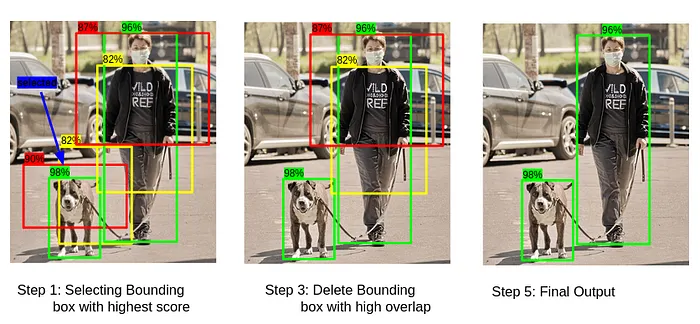
考虑上面有两个人的图像:一个人和一只狗。YOLO 最初可能会为这些对象检测到多个边界框,在上述背景下 - 结果是五个边界框,而理想情况下应该只有两个(每个对象一个)。
边界框重叠
当多个预测覆盖同一个对象时,就会发生重叠的边界框。这种冗余需要解决,以确保模型输出最准确和最小的边界框集。
交集比并集(IoU)
为了解决重叠的边界框问题,YOLO 使用了一种称为交集比并集(IoU)的技术。IoU 是一种度量两个边界框之间重叠的指标。
交集面积:两个边界框重叠的区域。
并集面积:两个边界框合并覆盖的总面积。
如果两个边界框完全重叠,IoU 值是 1。如果它们根本不重叠,IoU 值是 0。
非最大抑制(NMS)
为了消除冗余的边界框,YOLO 应用了非最大抑制(NMS):
计算置信度分数:每个边界框都被分配一个置信度分数,代表对象存在的可能性。
选择最高置信度框:选择置信度分数最高的边界框。
抑制重叠框:任何与选定框的 IoU 超过某个阈值(例如,0.5)的边界框都被抑制(即,移除)。
重复:这个过程对剩余的框重复进行,直到只剩下最自信、不重叠的框为止。
但 YOLO v10 消除了 NMS 的需求 - 简化了预测过程,提高了效率,而不影响模型的准确性!
YOLO v10:性能和比较
最新版本的 YOLO,YOLO v10,由于几个引人注目的原因,被认为是最佳和最改进的版本 - 这里是为什么:
更高的准确性 - 考虑到开篇的第一张图表 - 我们可以注意到,与以前的版本甚至其他模型相比,该模型产生了更高的 COCO AP 水平!清楚地表明 - YOLOX 模型(特别是 YOLOX-L) - 总体上表现最佳。
改进的延迟 - (延迟是模型对输入的响应时间)即使准确性更高 - YOLO v10 保持低延迟 - 使其灵活且有益于实时应用!
更好的对象定位 - 对象检测的主要挑战是处理重叠的边界框。幸运的是,YOLO v10 模型结合了高级技术,如 IoU 和 NMS,有效地处理重叠框,以获得更准确的边界框预测。导致更准确的对象检测模型!
更低的参数计数 - 在开篇的第二张图表中 - 我们可以得出结论,YOLO v10 模型可以用更少的参数准确预测。使其适合在资源受限的环境中部署。尽管我们可以指定一个 YOLO v10 模型是最好的 - 这都取决于用例。
以下是 YOLO v10 模型的所有变体列表 - 每个都有其自己的优势:

结论
虽然 YOLO v10 在准确性、延迟和效率方面都有所提高 - 但一切都取决于你正在处理的用例,因为对于每个用例,可能都有一个最适合的模型!尽管如此,根据提供的证据 - YOLO v10 作为领先的对象检测模型脱颖而出!
官方 GitHub :https://github.com/THU-MIG/yolov10?tab=readme-ov-file
论文:https://arxiv.org/abs/2405.14458




还没有评论,来说两句吧...