

引言
如果你是一名前端开发,同时又对AI开发很感兴趣,那么恭喜你,机会来了。
如果不是也没关系,同样能帮大家了解AI应用的开发思路。
本文将带大家从面向AI开发的基础知识开始,再到RAG,Agent,流程编排,深入了解如何在企业内部落地AI项目。
基础篇
一、如何面向AI交互
通常,我们使用一段文字输入,AI模型都会基于大模型自身来进行回答,这个相信大家已经都非常了解。但是,如果想让AI能够基于我们所期待的内容回答,或者说是基于我们的私域信息来进行回答,我们有哪些办法?
模型训练
微调Fine-tuning
Prompt提示词工程
RAG检索增强生成
模型训练:
通过从huggingface下载开源模型,在本地完成部署,比如最新推出的Llama 3 8B版,小模型对GPU的要求会相对低些,后通过大量的文档资料完成模型训练。
虽说小型模型降低了GPU的算力资源但成本也不是普通企业能承担的,除了自身的硬件成本、模型优化的人力成本,也存在模型的汰换风险,一旦外部大厂出个大招,那我们训练的模型就会面临淘汰,但企业也应采取防御型战略,先拥抱,毕竟AI已是大势所趋,模型在应用层接口方面在开源社区里已经标准化,开发设计时模型与功能解耦,随时替换。
微调Fine-tuning:
很多商业AI的服务模型都提供了这一能力,允许用户针对特定的应用场景调整预训练好的模型,以获得更符合预期的输出结果。
比如,你的公司有一个内部项目代号为"Project”,您希望使用LLM模型来自动生成关于"Project"的文档或回答员工关于"Project"的查询。但预训练模型没有接触过"Project"这个术语,因此无法生成相关的准确信息。这时候就可以通过一些术语或上下文来调整模型对于这一块的理解。
最后,微调是一种付费服务,如果未来换其他模型,你需要重新进行微调以适应新模型的特性和改进。这将再次产生计算和时间成本。
Prompt提示词工程:
这个应该是刚接触AI开发的同学,最先使用的,让AI能够按照我们的期望完成指令交付的方式。比如,让模型尽量用中文回答。你需要准备一份包含角色、背景、技巧、输出风格、输出范围等的Prompt提示词,然后在每次通讯时携带在上下文里。
如果你使用chat_model(Langchain术语)方式,则会在message数组的0键位一直保持system prompt,如果是LLM(Langchain术语)方式,则是在每次通讯时的message字符串里包装prompt+question,这里我们更应该基于chat_model方案来开发。
但是当你想要正式的投入到自己的项目中时,你可能会发觉Prompt非常难优化,AI并不能完全按照你的要求去执行。总结,Prompt会有以下几个痛点:
1. 设计难度大,如果模型的输出依赖于我们的提示词反馈,这可能会形成一个循环,我们需要不断地调整提示词以获得更好的输出。2. 长度限制,每次通讯的message通常会包含:Prompt + n轮上下文history + 本次的question,这些内容的总文字数也是计算我们单次会话的token总成本,过长的prompt很容易使AI产生幻觉,影响回复结果。3. Prompt依然无法解决让模型面向私域,我们公司内部的知识库进行回答。
RAG检索增强生成:
RAG对刚接触的同学可能会比较抽象,借用Langchain的图来介绍一下:
1. 首先是embedding向量存储
我们把内部文档在提取内容后进行切片,将内容转为段落数组(chunk),然后传入大模型的embed接口,模型会返回浮点数字,这个过程就是embedding,最后我们会把浮点数存入向量库,常见的向量库有es、faiss。
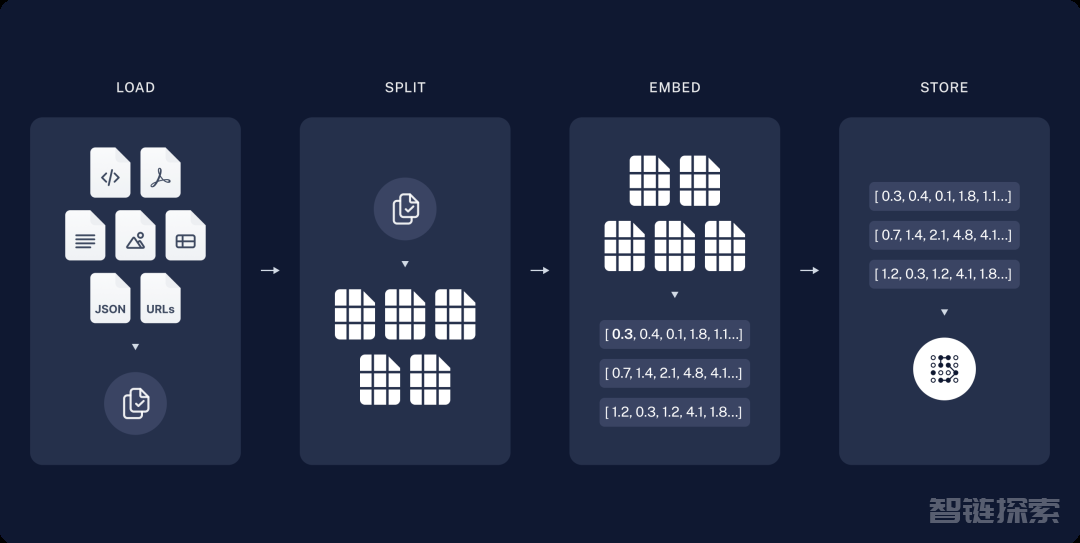 图片
图片
2. 接着是内容召回
输入一个问题,先通过模型embedding把问题转为向量数据,然后在我们的文档库里进行相似度搜索,召回相似度接近的数据后再交由大模型进行总结,最后返回给用户。
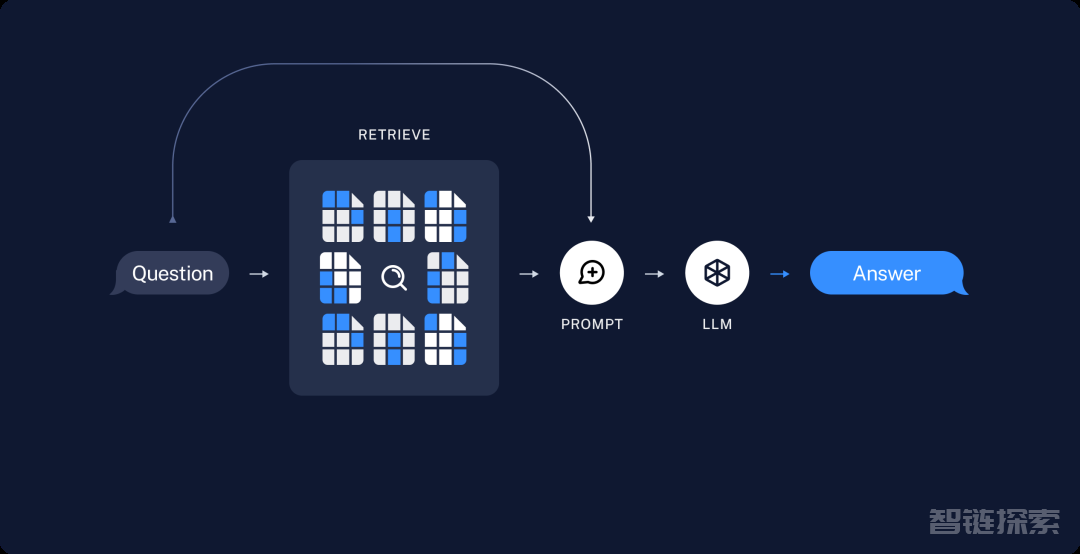
以上就是RAG的整个过程,RAG是个非常考验技术的工作,以上的流程是无法描述出RAG复杂性的,包括我们的产品在上线后,至今还在不断尝试如何更好的提升RAG的质量,做到能用很简单,但要做好非常难。
后面讲到内部知识库时再来讨论目前我们的方案,和线上实际效果。
引用在其他文章里看到的一句话,感同身受。
RAG涉及的内容其实广泛,包括Embedding、分词分块、检索召回(相似度匹配)、chat系统、ReAct和Prompt优化等,最后还有与LLM的交互,整个过程技术复杂度很高。如果你用的LLM非常好,反而大模型这一块是你最不需要关心的。而这些环节里面我们每个都没达到1(比如0.9、0.7...),那么最终的结果可能是这些小数点的乘积。
https://mp.weixin.qq.com/s/WjiOrJHt8nSW5OGe2x4BAg
二、Agent
前面主要是AI在文字内容上的交付,那如何让AI完成工作的交付呢?
当在工作汇报时,如果能用下面这张图来演示你的AI Agent功能,会不会很有吸引力?
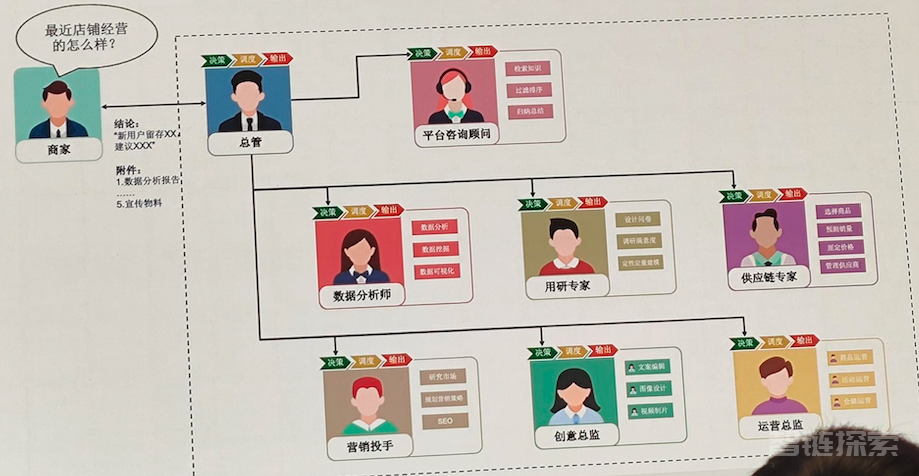
目前想实现Agent,主要有以下2种方式:
ReAct自我推理
Few-shot Prompt + Thought + Action + Observation 。
通过构造一个内含工具、推理和规划的prompt结构,模型在内部通过与提示的互动进行自我迭代和调整,以选择适当的工具或生成更好的输出。
例如:
我们通过Prompt告诉模型,它善于使用工具来解决问题,告诉它每一个工具的介绍,和需要填入什么参数,最后要求模型每次回复时必须遵循使用markdown code格式返回,然后我们会在Agent进程里消费返回的json-schema,是调用工具还是Final Answer。
Tool-call 代理交互
很明显ReAct会导致我们的上下文过长,很容易造成模型在经过几轮迭代之后不已markdown code的格式来返回内容,最终导致Agent走不下去。
tool-call的出现解决了这一问题,我们会把Prompt里这些非结构化的工具描述转化为结构化的api字段,这样既节省了Prompt的上下文长度,也变的容易控制。
例如:
此时,模型也会以结构化的方式告诉你他使用的工具:
三、开发框架
再来介绍下我们选择的技术框架,之后也会介绍其优点和不足之处。
Langchain
在许多讨论AI的文章里都会提到Langchain,或者很多的开源框架都在和Langchain作比较。Langchain是一个集成了商业和开源模型,并提供了一整套工具和功能,简化了开发、集成和部署基于语言模型的应用。
- 组件化:为使用语言模型提供抽象层,以及每个抽象层的一组实现。组件是模块化且易于使用的,无论是否使用LangChain框架的其余部分。- 现成的链:结构化的组件集合,用于完成特定的高级任务。
通俗的讲,它为不同的模型,不同的组件提供了统一的输入和输出规范。
在Chain里可以传入[Prompt、Model、Tool、Memory(历史会话)、OutputParser],也能将多个model进行嵌套,让上一个model的输出作为下一个PromptTemplate的输入。
目前官方提供了2种语言的版本,一个是Python,另一个是Nodejs。
Flowise
基于Langchain的AI流程编排系统,主语言Nodejs,为Langchain的每个模型类和组件类提供了可视化的低代码组件,通过在画布上的拖拽组件,即可完成AI的整套交付流程,组件包括Chain(进程)、Prompt、Agent Tool、Chat Module等。
同类的还有Dify,它提供了多模型对接、RAG、任务编排、等整套的产品化方案。
Flowise更像是一个毛坯房,提供了解决方案,但所有的产品化还是需要自己开发,读懂它,能让你在开发Langchain时事半功倍。Dify更像豪华大别墅,大多数的功能都已经做好了产品化,内部独立维护了与模型的api封装,主语言Python。
Flowise中的packages介绍:
- Server:express,CRUD、完成组件库内的实例运行- Component:JavaScript,实现Langchain类的可视化和低代码- UI:React,AI流程编排的画布,和一些维护页面。
以下是一个通过Agent由AI判断选择使用哪些工具的编排展示,我们重新开发了Agent组件,已更适应我们的tool-call功能,在Bili Agent主进程中,组件会负责消费这些关联了的工具。
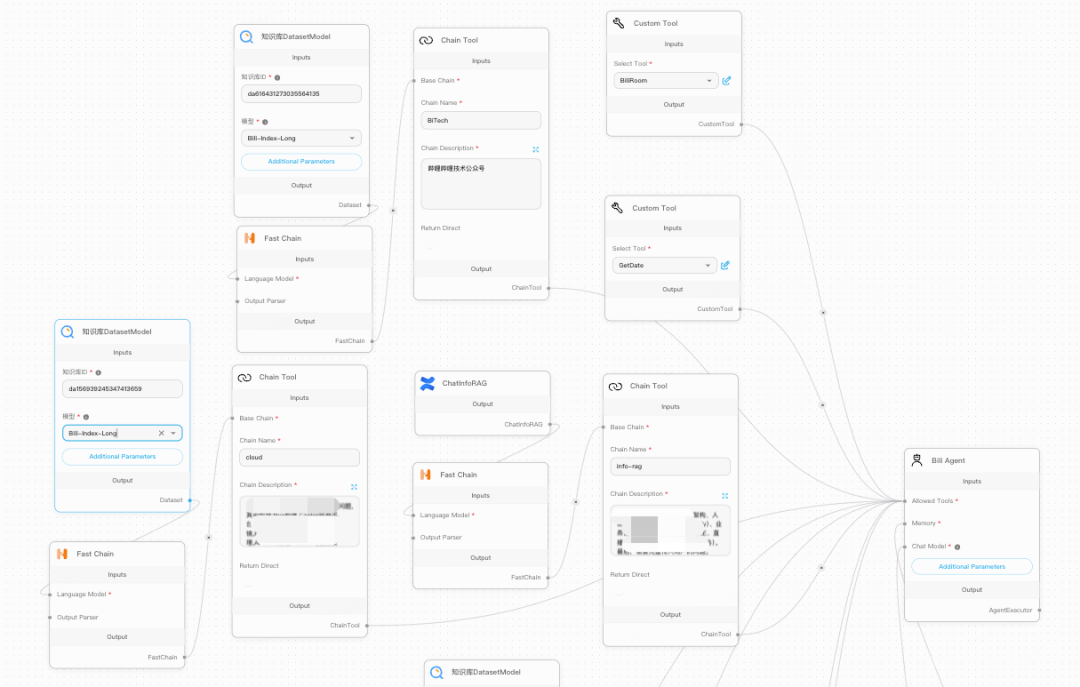 图片
图片
部分代码示例:
最后通过Agent的配置,就可以让模型在通用域和私域或是工具插件里自由的选择进行聊天。
 图片
图片
以上就是基础篇的全部内容,至此可以发现,为什么本篇开头会提到恭喜前端。是的,以上技术栈全部来自前端领域。




还没有评论,来说两句吧...