

一、端侧图文检索技术研究
1. 解决了什么问题?
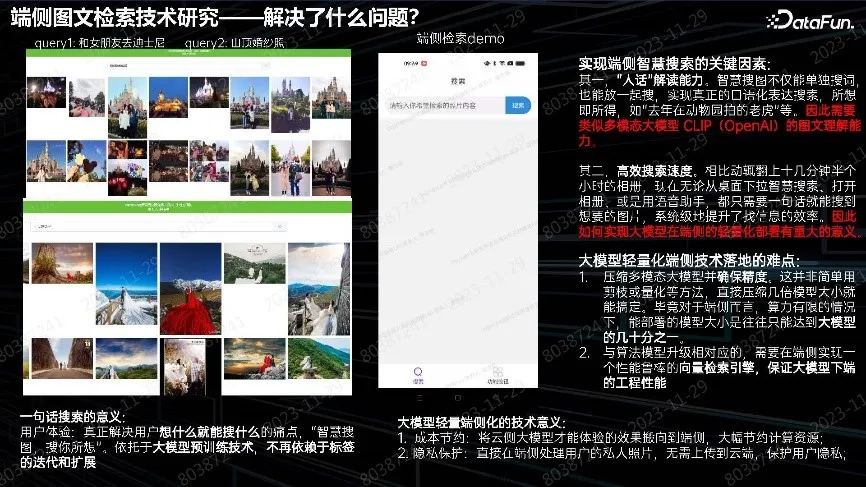
首先来介绍图文检索技术。以前在手机端相册搜索照片,都是基于标签来搜索。从 CLIP 模型出现后开始做自然语言搜索。目前正在解决端侧性能、搜索效果、安全等问题。技术难度并不大,重点在于提高搜索速度。并且要保持与云侧模型相同的精度,供断网时使用。
2. 算法优化
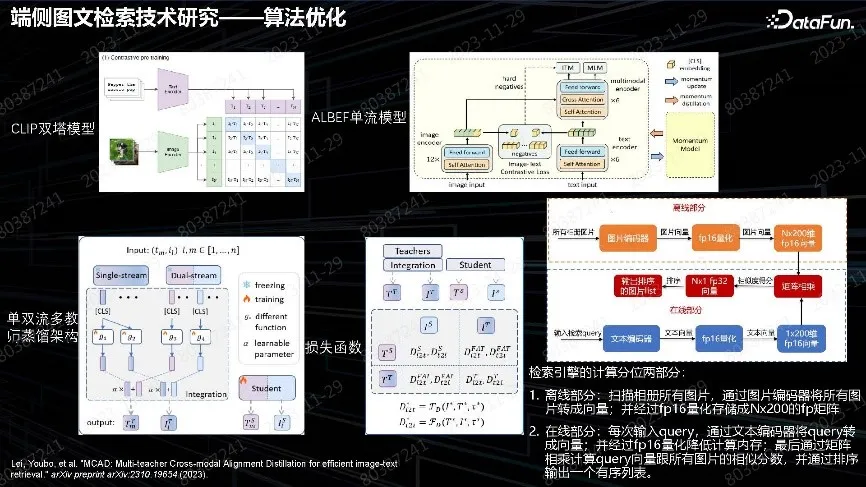
算法优化集中在压缩算法。用 CLIP 模型做图文匹配,算法简单,训练支持大规模并行,但对细粒度理解有问题。采用 ALBEF 单流场景,最后需要把图片和 Query 做融合计算,在端侧无法落地。由于 CLIP 模型的模态信息保留最后的输出层,端侧可以做单双流融合,把两个模型的能力蒸馏到小模型上面。因为图像和文本的模态在ALBEF 中间已经融合,所以设计 Projector 再分离出来,经过组合得到单双流的细粒度特征和全局特征的融合,获得输出,最后蒸馏出 Student。蒸馏的过程采用 contrastive loss 算法。整体算法的目的是为了得到端侧的 CLIP 架构小模型,实现离线编码和在线搜索。
由于图片数量有限,没有采用像 IVF-PQ 向量引擎。实际在 10 万级图片压测下,直接做向量乘法也足够,fp16 最终速度都很快,因此最终采用了简单架构。
3. 学术集效果
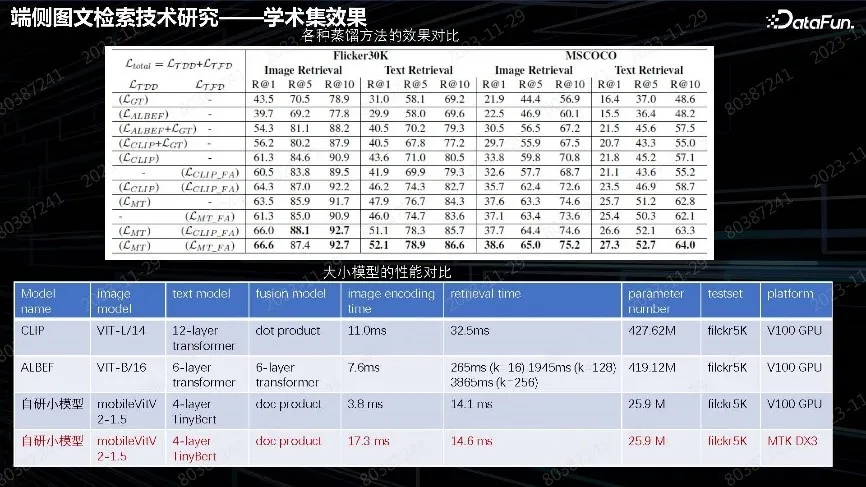
从上图数据中可以看出,单纯CLIP 或者 ALBEF 效果、不如融合之后效果好。由于没有增加推理成本,最终落地效果与云上 V100 GPU 速度相当,搜索时间为 14 毫秒。image 编码时间也很短,基本达到了云端先进 GPU 的能力。
4. 真实场景效果
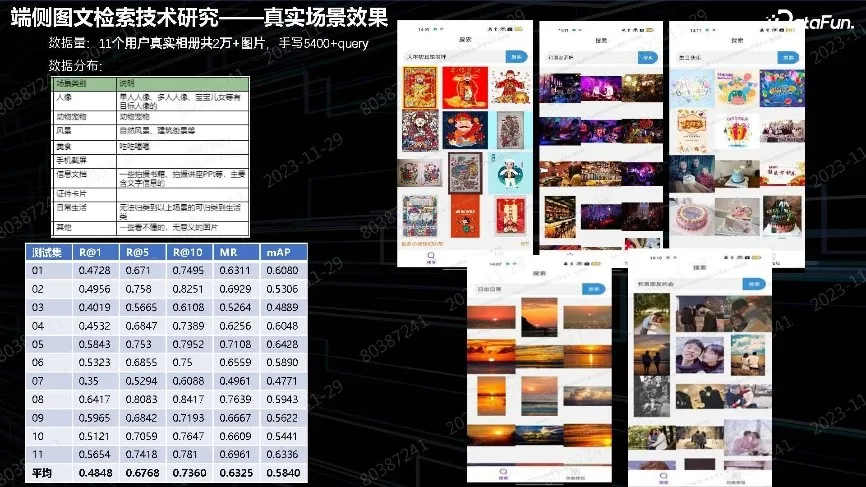
上图中展示了真实场景中构建相册、照片的效果。最终优化为全域优化。
5. 细粒度优化
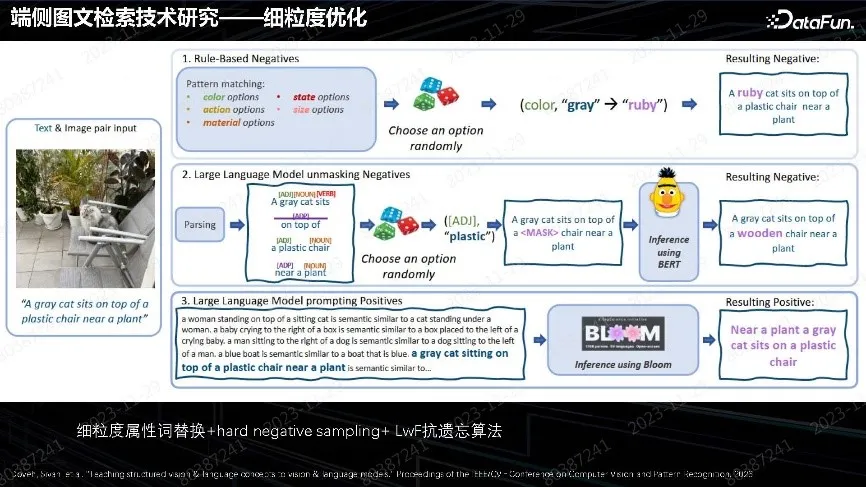
CLIP 算法优化是以海量数据训练。想做到更细致的优化,由于本身没有识别属性能力,对图片款式、颜色状态、细腻度属性识别比较差,对文生图影响很大。我们针对业务场景改进了方法,在 Query 里面做细粒度属性词替换。这种替换方法,无论用人工方式还是文本模型找属性词都可使用。最终把比较细的负样本构造出来,做负样本的采样训练,强制让模型判断出哪些是错误属性,搜索时就能排除错误。这是实践中非常行之有效的方法。注意一定要加上 LWF(Learning Without Forgetting)抗遗忘的方法,以保留之前的数据和训练,才能保持通用能力不下降。这个方法对已有模型优化非常有效。
二、文图生成&理解态模型的应用优化
文图生成&理解态模型的优化主要是对生成进行优化。而理解是在图片生成后加上文本生成,做出图文并茂的效果。
1. 中文文生图大模型继续预训练
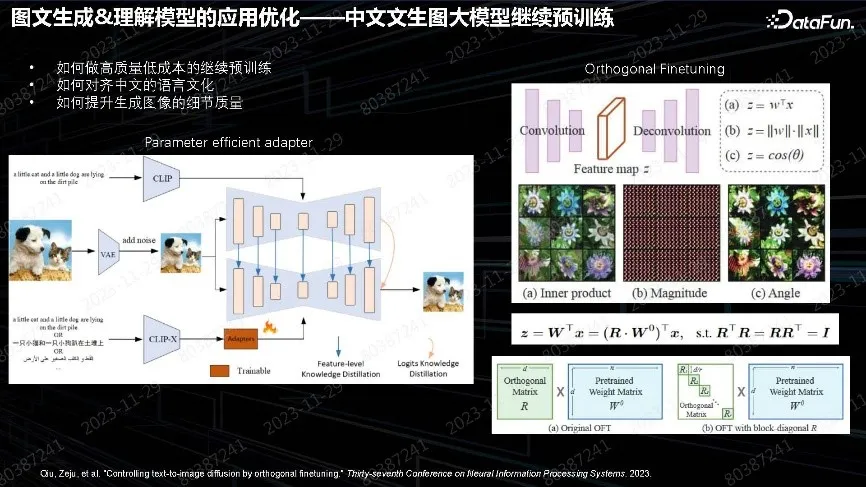
鉴于业界没有特别好的开源中文大模型,很多人直接用英文模型加上翻译来做。这样会带来很多问题,例如继续训练怎么做。从头训练做自己的大模型,毕竟不一定都有资源;如果质量不好,调整也很费时间。我们的方案是用开源的英文优质模型做继续预训练,并涉及如何对齐中文语言文化。
另外一个难题是生成图像质量的细节提升。上图中展示了我们的解决方案,经过实验,如果有很好的英文模型适配中文,不需改动所有的模块,包括 unet、text encoder,只要加一个 adapter,通过训练 adapter 就能实现多语言输入,并得到同样质量的输出。最初是通过做 text encoder 再对齐,但 text encoder 对齐非常复杂。实践中把后面的Unet 加上去蒸馏,就会很容易对齐。Adapter 只需做简单的mapping,最后发现前面的特征空间没有对齐、也不需要对齐。只需在 Unet 空间做出正确的生成。
在有了一个中文的模型后,后面需要进行中文语言文化的继续训练。我们也尝试了一些方案,其中包括微调的方案。业界常用 LoRA 做垂域优化,LoRA 最大的问题是遗忘性。上图右下侧展示的是 2023 年的一篇 NIPS 文章,采用的方法很简单,LoRA 在原参数上乘 R 正交矩阵,目的是希望训练参数不去动幅度,只动角度。很早有实验证明,把特征相位抽出来,就能完全呈现图像,幅度 W 没有太多作用。所以在生成时考虑调整参数旋转角度,以适应新的数据。这在实践中证实是一种非常好用的方法,只要加少量以前的数据,去做抗遗忘的 replay,就能很好地实现数据迁移,保持语言模型的通用能力,并持续增加新场景的能力。我们还会用这个方法持续做各种各样新效果对齐,并且训练速度非常快。

上图右侧表中可以看到,2,000 万 Sample 就达到了收敛效果。如果资源不多,用单台机器两天内可完成训练,硬件资源消耗也少。原模型缺乏中文能力,不理解中文诗句和场景,而我们用非常少量的数据就让其适应了模型,并且没有出现通用质量下降。

Adapter 适用于任何开源场景的社区的模型,将其接到后面相同架构的无论是XL 模型还是 SD 模型都可以适用。在每一个场景中,无论 Finetune 模型还是 LoRA,unet模型的参数都可能发生变化,把中间的 adapter 加过去,就可适应做出各种中文的效果。其他方法包括 Controlnet、最新的加速方法、小模型、inpainting 都可以用。
我们用非常低的成本实现了场景的中文迁移,尤其语境上的继续预训练能力得到了提升。如果缺乏资源训练理想的基础模型,推荐这种方案。
2. 通用优化应用
要提升基础能力做通用模型,再逐渐优化后续能力,是个漫长的迭代过程。我们在春节档上线了 AI 壁纸专栏,说明 AIGC 的落地没有太多质量上的障碍,用户可以接受,但需要谨慎考虑安全和版权问题。
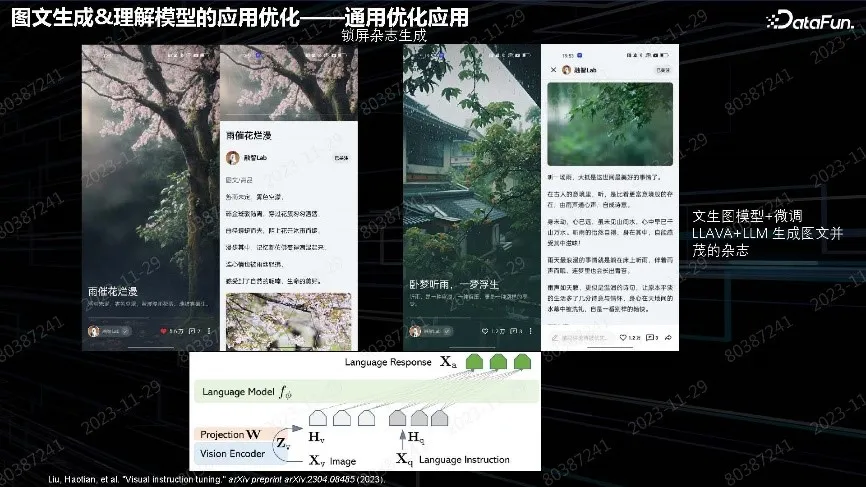
另一个典型案例是锁屏场景。手机图文是手机厂商的主要流量,可以用 AI 生成图文对,并插入广告等内容。图中是 2023 年上半年 Top 排行图文组内容,质量非常好。文本用多模态大语言模型,用 LLAVA 进行微调,其中大语言模型来自其他团队,基于微调 Projector 和大语言模型,实现有诗意的文字生成。
以上是实现 AIGC 在 ToC 端落地的场景。
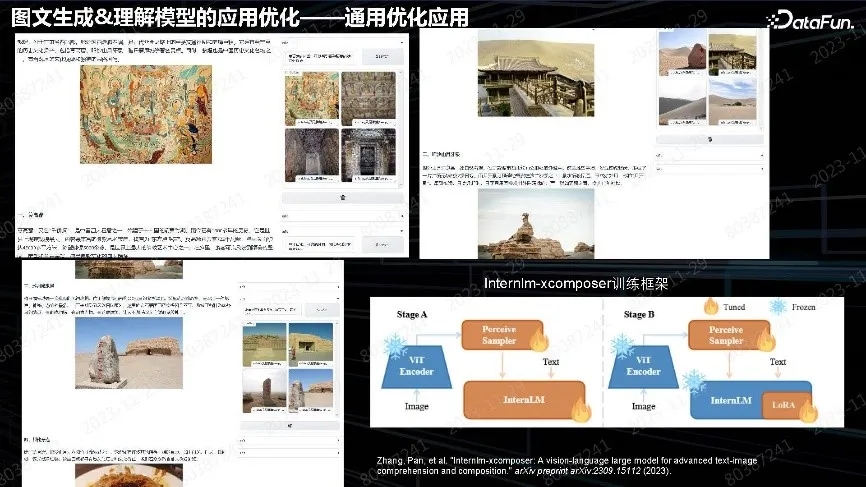
上图中的场景是图文生成相关的一个畅想,即针对用户照片进行配套生成。例如在用户旅游时上传照片,帮助用户写一篇完整游记,发布小红书、知乎。更具优势的是生成文章插图,用户自由选择,或选择其他图片。如果觉得自己拍的照片不好,可以用生成模型生成图片。这是完整的 Pipeline 链路,可以用自己的照片、网上搜索的图片、生成的图片,模型解决文章的结构和插图位置的问题。下一步是考虑整个文章和图片的内容匹配度以及文章图片本身的质量问题。
3. 垂域优化-人像垂域

垂域优化的典型场景是手机厂商浏览器中的广告场景。小型 ToB 的厂商投广告,特别重视人像垂域中几个生成的问题:
(1)人脸和人手的崩溃问题。大部分开源模型都比较差。
(2)太过精致、质感太好的问题。尤其是社交工具的用户,觉得不真实;真实的资源都是普通人,这种反向需求就需要考虑如何去做垂域的优化。
(3)细粒度属性和文字不匹配的问题。
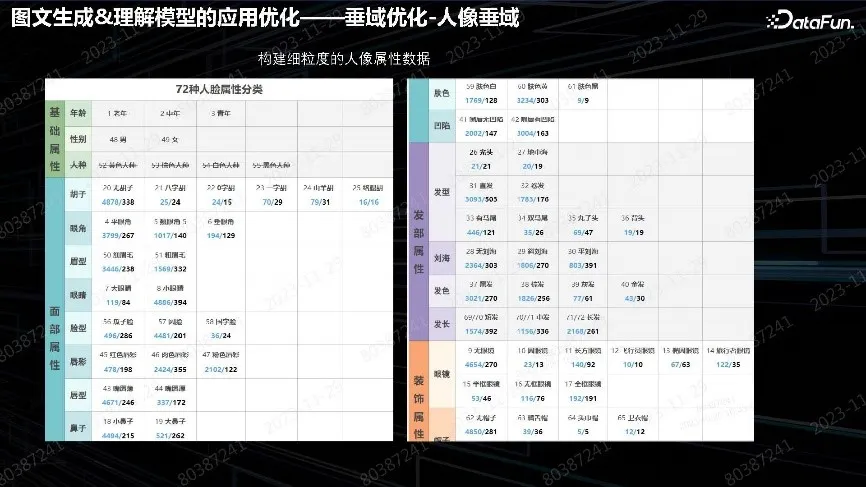
用 CLIP 做主观意愿落地的 Fusion 都有这种问题,对语言理解力不够,特别是美容、整容广告都非常看重这种问题,例如做大眼睛美女却生成了小眼睛。需要做文本描述和生成实体的对齐。这个问题从数据角度上可以解决。针对实际业务场景,构建了丰富的数万张美容、整容关注的人脸属性数据集,进行数据收集和非常精确的标签打标。数万张图片对于模型微调来说已经非常多了。通常用几十张对微调就会具有非常好的效果。因此构造细粒度数据,人工逐个打上标签,人脸或者人像的标签区就会非常细致、丰富。
(4)优化位置的问题。
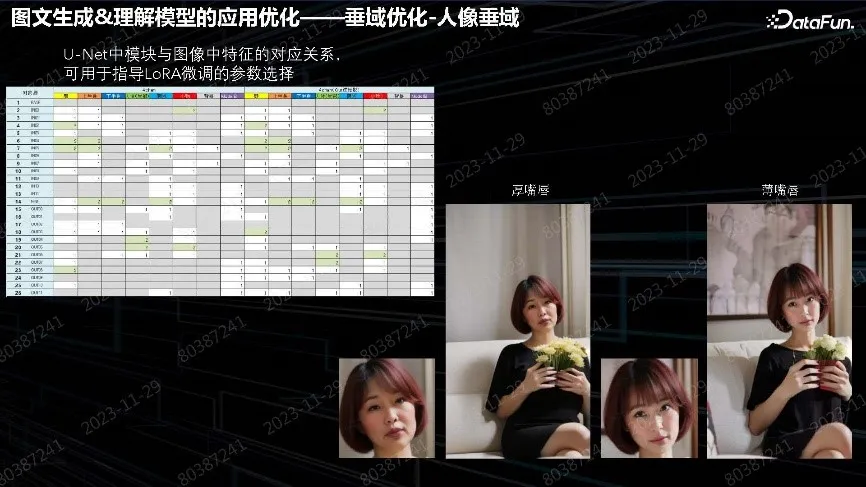
上图中的总结表来自于 Github,非常详细地描述了 LoRA 微调某层对人像五官产生的最大影响;包括了对人体的上半身、下半身、背景需要微调 unet 具体层。2 代表变化很大,1 代表稍微小一点,其他位置几乎无变化。想调整什么地方,对照表去调相应层参数就会非常有效。比如:丰唇广告,之前生成薄唇效果,现在改为厚唇,找到效果好的微调位置,调整数据就能得到满意效果。


以上两图中展示了更多其他的例子。比如:鼻子类,控制同一个人、同种鼻子效果;纹眉可以实现粗眉细眉。这套 Pipeline 出来之后,可以做任何五官,总体感受是一条比较有效的 Pipeline。注意:并非每个微调都会有好效果,某些太细微的特征需要用其它算法调整和解决。
通过以上实践,我们总结出了一些经验:
微调时,需要大量数据提升模型对新概念的泛化能力,数据质量不一定高。比如:人像,需要较多的人像数据,用于认识和识别、尤其是亚洲人。
需要稍高质量的数据精调,特别是在第一个模型之后,需要几十张高质量的精调数据,可以把效果做出来。

典型案例还有人像修复 Pipeline。比如:古风游戏或者是古风小说,需要做古风场景生成。模型肯定没见过,可以先塞一些剧照,后面再用 80 张图片做古风的生成。直接生成图片交由用户去挑选。

最终生成效果非常好,适用于各种中文的语境场景,比如小说广告。当然,生成图片里面的人脸、人手问题仍未解决,对基础模型的要求会更高,微调无法解决这个问题。
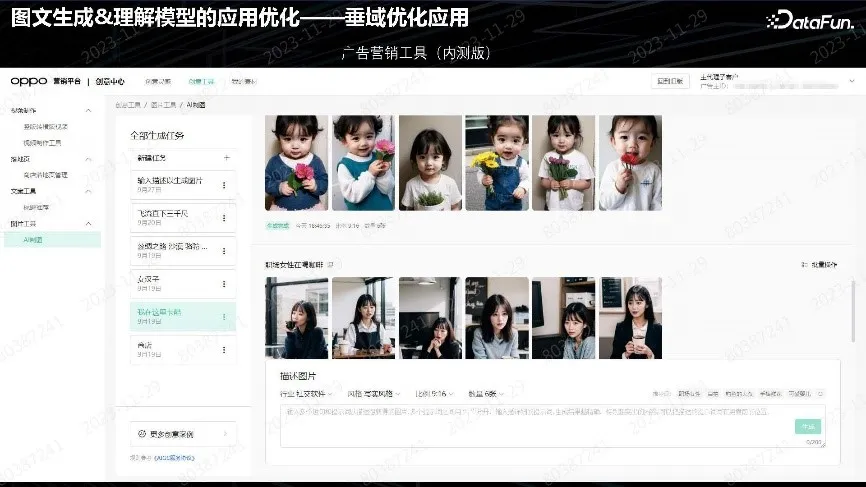
上图是一个广告营销工具,主要面向小型 ToB 用户。首先确定行业和风格,写实、动漫、或者古风。在完成生成后,加上自己的产品或者小说、APP 等去投放。这套 Pipeline 工具业务定位就是人像垂域。
4. 文字渲染

壁纸生成主要是做高质量高分辨率场景。例如:年初有做新春快乐、兔年大吉壁纸的需求。大家都知道,文生图对图中文本的渲染生成有很大问题。随着对算法的深入了解、实践和越来越多的文章可借鉴,算法也逐渐精细。当时只考虑输入 prompt,然后输出图片的场景,由业务人员去挑选调用。
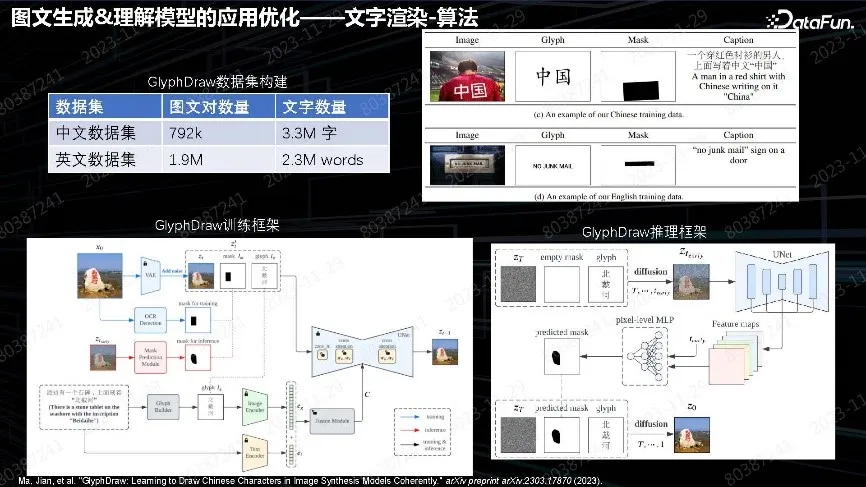
文字渲染从算法角度,是构造文本和图像对应的数据。把图像中的文本抠出来,然后对应位置,描述里面也要包含文本。这种需求做了长数据处理,没有过多考虑质量和长度问题。可以采用百万级数据量,收集也比较快。这种条件生成的算法框架就是提取需要关注的信息,把信息当作条件,注入到后面 Unet 或者输出层、Text encoder,中间的细节做一些调整。最终目的是强化整个需要生成的细节内容对最后Unet 的影响。推理的时候也是一样的用法,把文字当作特征直接输入,不仅仅是 prompt,而是要把 prompt 里面的引号中文字内容取出来,做字体都可以用,这个Font 最终自己会泛化出来。
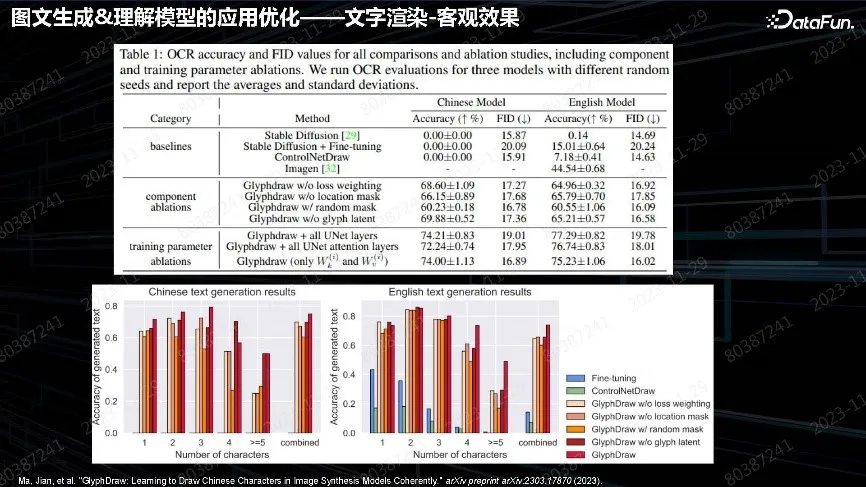
上图是文字数据集的效果。加了上述算法后,能力得到了大幅提升。

上图是一些反应主观效果的例子。壁纸应用相对来说比较简单,业界、学术界后续做了很多精细工作,除了能生成这种 PS 的文字,也能生成真实场景下雕刻版文字或长文字、书籍,甚至编辑自己指定字体。
5. 个性化生成

后续又扩展到主体个性化生成,应用更加广泛,如:DreamBooth、Textual Inversion。大家都希望输入图片,并在各种各样场景中做生成,也是典型的广告场景需求。比如:之前的广告都是文生图;现在的广告可以根据用户的产品,帮助其生成各种场景下的广告再去做投放。这种需求也是前面工作的延续。为什么之前没有用DreamBooth,是因为 DreamBooth 要做 test-time 微调,每张图片要微调较长时间,算力消耗也很大。理想情况是上传产品后,几秒钟之内就给出结果。当时考虑采用开放域、无需微调的生成方法、实现各种各样的功能。
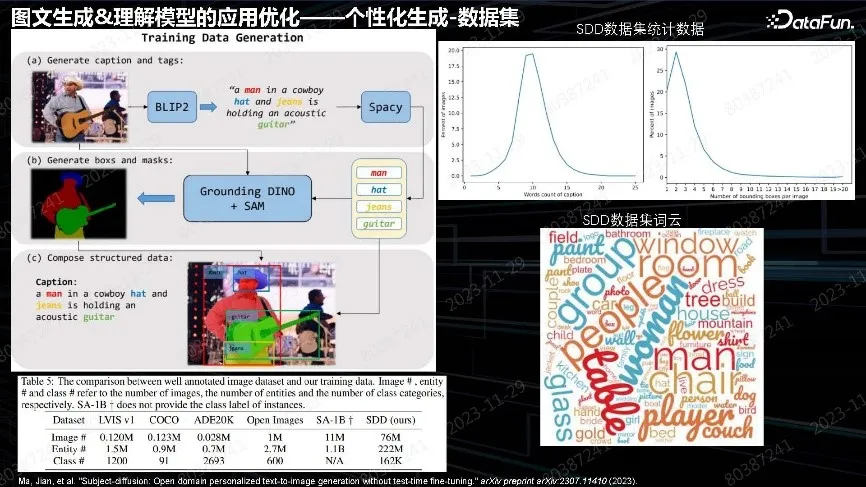
跟前面的工作一样,都是先做数据。数据集与文本不同,要做细粒度分割。分割完之后在每个实体得到实体信息。这在早期不容易实现,直到 SAM 出来后对方法做了推动,SAM 可以做自动化的分割,分割完之后再用 Grounding DINO 方式做开放域的识别,就能实现非常详细的细粒度分割,包含图片的 tag 标签和整体 Caption 的数据集。这个数据集构造的数据量比 SAM 还要大很多,达到 7,600 万个。用这批数据做预训练,得到了 test-time free 的主体个性化的生成模型。
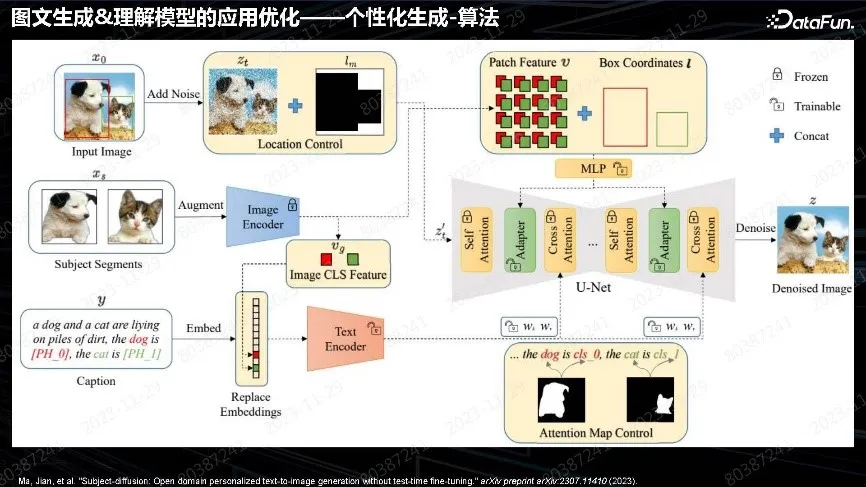
模型架构跟前面一样,是一脉相承的想法,差别是特征提取自图片中物体的特征,再把物体特征送到 Unet 里面当作 Condition。也可以在 Text 里进行操作,比如提取特征、特征力度、送到 Unet 的位置。
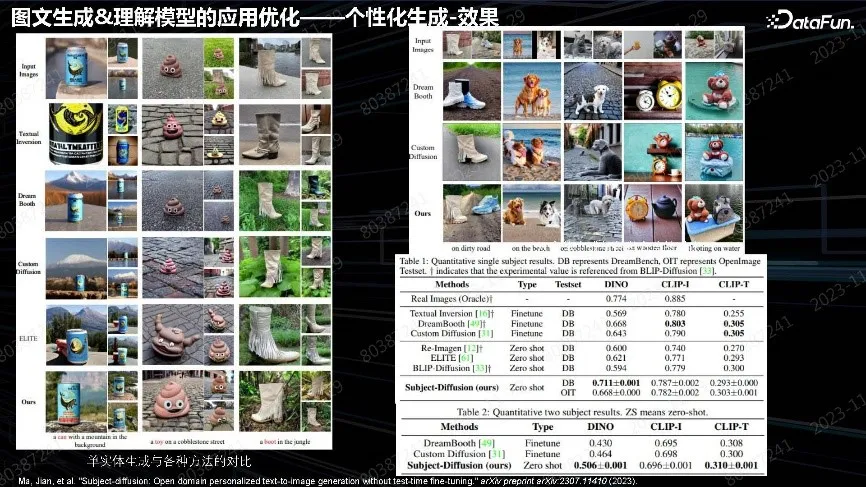
最终做到了和 DreamBooth 微调方法差不多的效果。其中保真最重要,商品要真实。会牺牲部分可编辑性,不能像 DreamBooth 那样生成非常丰富的背景,这是后面需要改进的算法问题。

举例:投放的广告是一个包,可以设置各种用户想要的背景。但可编辑性没那么强,不能做到像猫狗一样的姿态变化,这是现存的问题。但已满足当前场景的需求。

多个实体同样可以做生成。
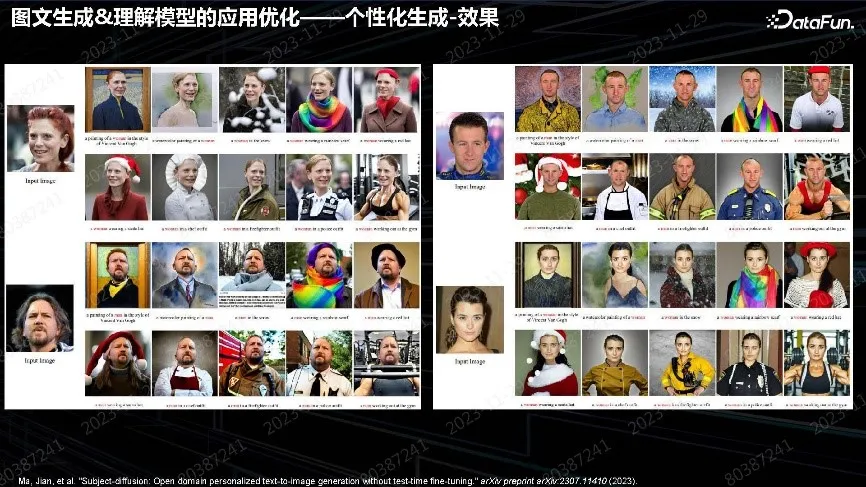
人像也可以做,但问题是对于正面照无法生成侧面照,因为单张图片的泛化能力仅限于此。这些方向发展非常迅速。最近的文章在保真性和可编辑性上都做得比较好。我们会及时跟踪算法、方案并更新产品。
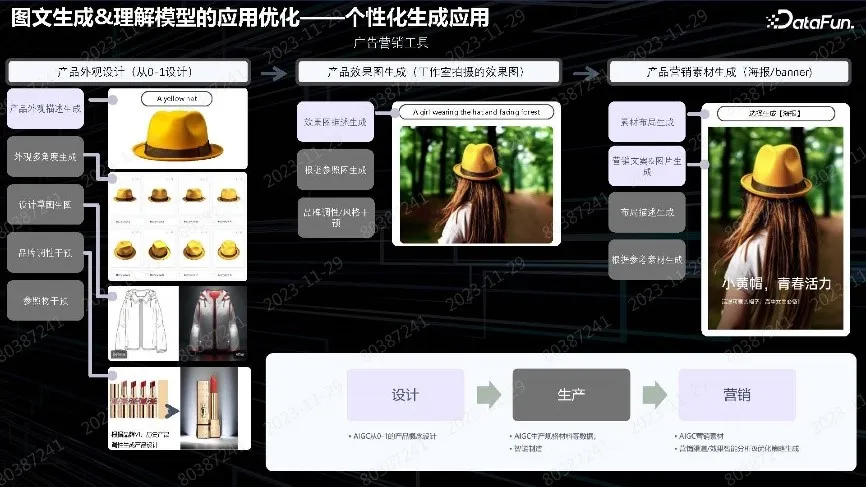
上图中产品做了比较完整的广告营销方案。有些商品需要做概念图,就直接用文生图生成;有些已有商品可以直接用产品图。个性化生成会根据商品生成比较适合推广的广告图,然后在上面加文案,或者文案自己加。这种 Pipeline 从设计到营销,中间没有商品生产这一环节。用户可以不做生产,直接用 Pipeline 先把广告打出去,然后再去生产实际商品。
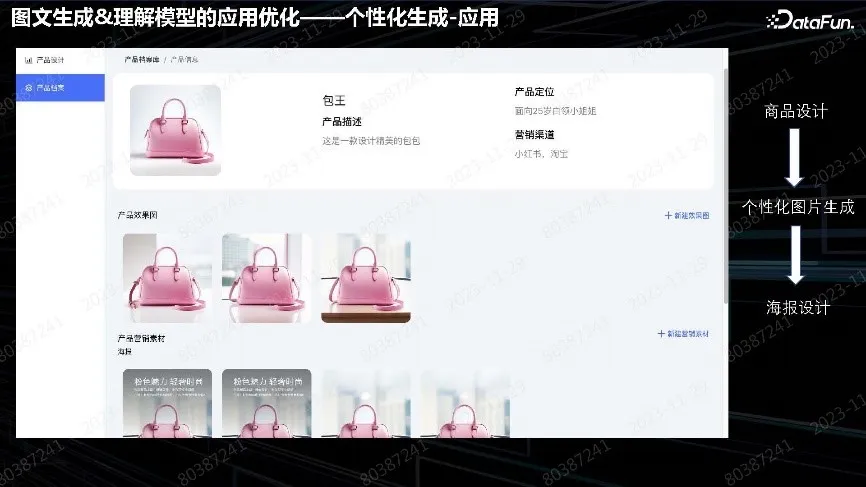
上图是一些提包的实际案例,用户用一个商品,生成各种背景,然后再加上文案。
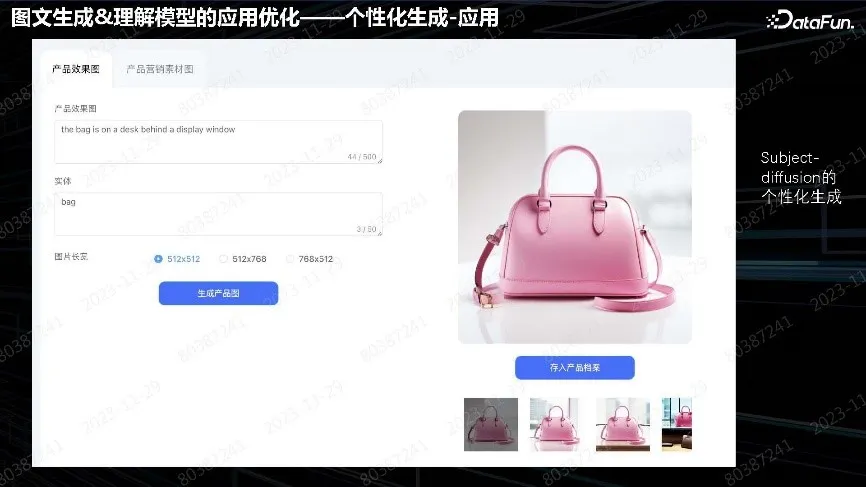
这种都是用英文模型输入,然后生成背景,但有些错误,用户可以自己选择图片。
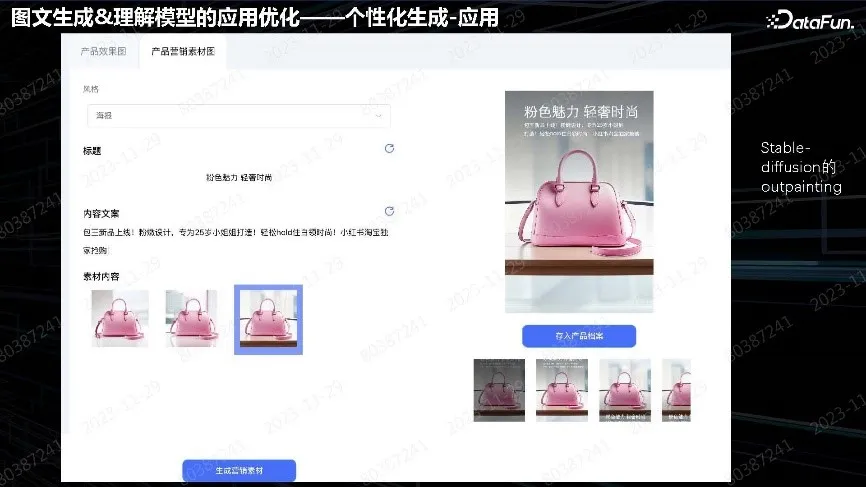
最终形态如浏览器中的广告,对质量要求不是很高。主要关注实效性、用户能立刻看到效果图,所以贴的字都比较粗糙。图片生成是主要业务需求。
三、文图生成模型的端侧轻量化
手机厂商在云侧图片生成的应用不多,需要做更精细化的结果,让用户得到更多的价值,比如减少用户的工作量,这种情况多为小型 ToB 用户。前面内容落地都在云上,成本会很高,所以端侧厂商的优势就是把所有算法都搬到手机上,用芯片去计算实现无任何成本、无隐私的问题,愿意怎么用就怎么用。后续工作重点在文生图模型端侧轻量化,接下来的介绍将更多涉及技术细节和工程方面,不涉及落地场景问题。
1. 技术路线-模型结构优化
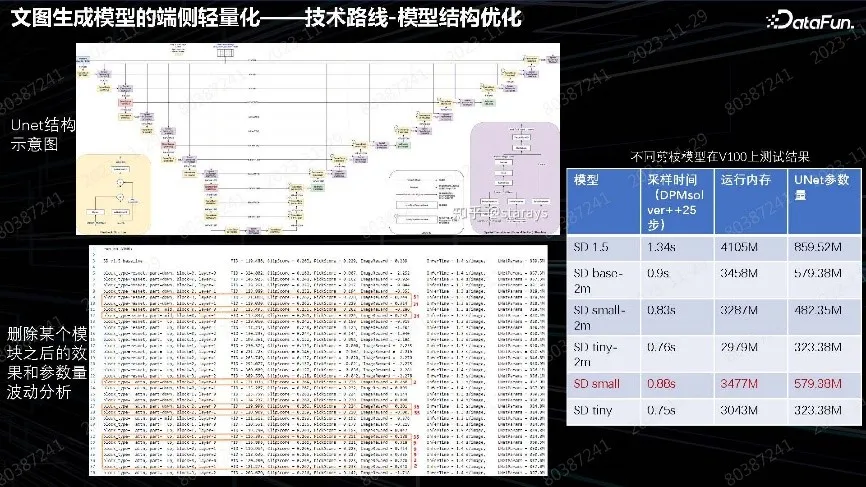
通过我们的实践,从 Difusion 端侧优化分成三个方向:
模型的压缩。一般大模型都会压缩模型,Unet 也不例外,因为 Stable Diffusion 最主要还是 Unet 压缩。对 Unet 的每层进行分析,寻找效果影响最小、整个时效和内存要求最高的层,剔除这些层,再去继续训练,得到 Tradeoff 模型。我们的 Tradeoff 小模型,比原版 SD 参数量少大概 1/3。在这个模型的基础上,再按上述方法训练一轮,用蒸馏方法做中文小模型,得到内存可控的端侧模型。这是常规的模型压缩方法。
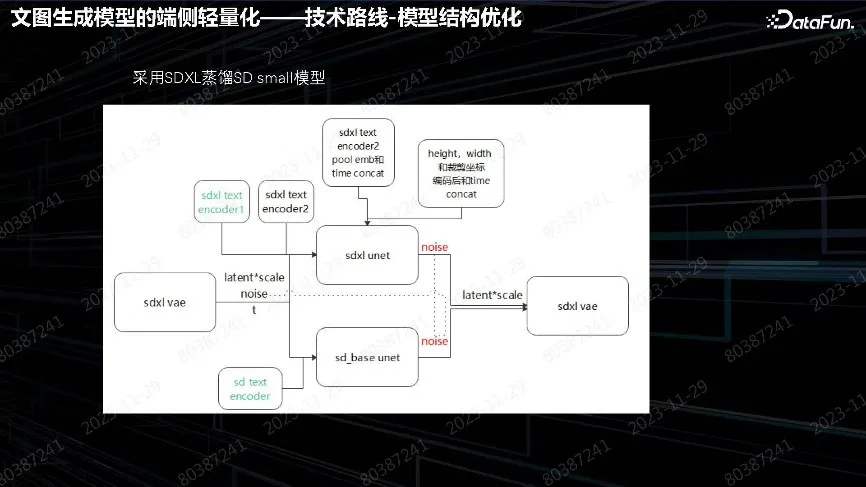
Stable Diffusion 对采样要求比较高,采样是主要的时间消耗。蒸馏主要用 SDXL 效果比较好、相对比较小的 SD_base 模型。用它自己的 text encoder 或者 VAE decoder 做前处理和后处理。重点是 Unet 的循环蒸馏该怎么做,其算法会更深一些,也是学术界研究比较深入的一个方向。
2. 技术路线-采样加速
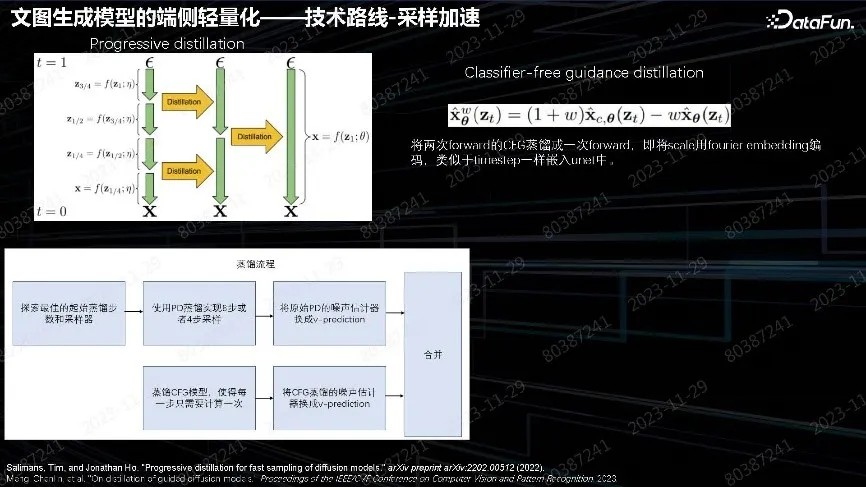
SD 做迭代采样时间会成倍增长。最开始的云侧模型用了 25 步 DPM-Solver,这个时间成本比较高。遵循图中提到的做法,把 Diffusion 步数逐渐缩减,四步缩减两步,两步缩减一步,蒸馏两步的输出效果、做到一步实现。这是 Progressive distillation 方法。
另一个方法是 Classifier-free guidance distillation。在 Stable Diffusion 里面增加泛化性、多样性和质量评估,都用 W 参数控制深层的多样性和效果的平衡参数。在 inference 时需要做两步才能合成最后一步,所以实际步数都会乘以 2。但是下面这篇文章把 CFG 蒸馏和原始蒸馏合成了一步,使用 CFG 蒸馏一步来做,节约了一半时间。
最后的蒸馏流程用以前训练好的 SD 小模型,先做 Progressive distillation 的蒸馏,再做 CFG 模型蒸馏,然后把这两块合在一起。逐渐迭代,从最开始用 32 步,然后迭代到 16 步、8 步,最后做到 4 步。重点是训练蒸馏数据,做出高质量数据,保证蒸馏质量没有损失。
3. 技术路线-效果对比

表中展示了最终实现的效果。从起初的 10 秒以上,到现在的 2.5 秒,相比之前有了大幅度提升。目前已进入端侧 Diffusion model 落地的时代。前不久,高通和联发科都发布了广告,能够把 Stable Diffusion 做到 1 秒以内,其中包括在算子优化上非常多的工作。我们和他们紧密合作,在没有做任何算子上的优化情况下,上述纯算法优化版本我们做到了 2.5 秒。下一步会做算子加算法的综合优化。最终的目标是达到用户无感知的生成,并保证效果。

上图已经实现相同效果。上面是 SD 原版模型,在 DPM solver 25 步的结果,云上可以采用这种采样方法。端侧可以做到 4 步,然后做 W8 的量化。这个小模型是用更强的大模型蒸馏出来的,所以在指标上比 SD 更好。实现在端侧做到用户基本无感生成,把 SD 能力完全继承的效果。预计明年手机厂商会考虑把整个生成的模型搬到端侧,直接在手机上即可生成。
以上就是关于端侧落地技术优化场景的分享。后续问题是对于集模型,在端侧除生成速度还要考虑内存问题。无论个性化生成、还是 LoRA 微调,都只能在这个集模型上加小模块。把这些模块堆叠起来,如何使用、调度还需要制定策略和编写算法。真正实现全端侧、生成 AIGC 的 Pipeline 工具还需要一段时间。




还没有评论,来说两句吧...