

在大数据时代,数据科学覆盖了从数据中挖掘见解的全周期,包括数据收集、处理、建模、预测等关键环节。鉴于数据科学项目的复杂本质以及对人类专家知识的深度依赖,自动化在改变数据科学范式方面拥有极大的发展空间。随着生成式预训练语言模型的兴起,让大语言模型智能体处理复杂任务变得越来越重要。
传统的数据处理和分析大多依赖专业的数据科学家,费时费力。如果能够让大语言模型智能体扮演数据科学家的角色,那么除了能够为我们提供更高效的洞察和分析,还可以开启前所未有的工业模式和研究范式。
这样一来只要给定数据任务需求,专注于数据科学的智能体就可以自主地处理海量数据,发现隐藏在数据背后的模式和趋势。更广阔地,可以提供清晰模型构建的策略和代码,调用机器进行模型部署推理,最后利用数据可视化,使复杂的数据关系一目了然。
近期,吉林大学、上海交通大学和伦敦大学学院汪军团队合作提出了 DS-Agent,这一智能体的角色定位是一名数据科学家,其目标是在自动化数据科学中处理复杂的机器学习建模任务。技术层面上,团队采用了一种经典的人工智能策略 —— 基于案例的推理(Case-Based Reasoning,CBR),赋予了智能体 “参考” 他山之石的能力,使其能够利用以往解决类似问题的经验来解决新问题。

论文链接:https://arxiv.org/pdf/2402.17453.pdf
代码链接:https://github.com/guosyjlu/DS-Agent
论文题目:DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning
研究背景
在自动化数据科学这种开放决策场景中,目前的大模型智能体(例如 AutoGPT、LangChain、ResearchAgent 等)即使搭配 GPT-4 也难以保证较高的成功率。其主要挑战在于大模型智能体无法稳定地生成可靠的机器学习解决方案,并且还面临着幻觉输出的问题。当然,针对数据科学这一特定场景对大模型进行微调似乎是一种可行的策略,但这同时引入了两个新问题:(1)生成有效的反馈信号需要基于机器学习模型训练,这一过程需要耗费大量时间才能积累足够的微调数据。(2)微调过程中需要执行反向传播算法,这不仅增加了计算开销,而且大幅度提升了对计算资源的需求。
在这种情况下,团队决定使用 Kaggle 这一关键资源。作为世界上最大的数据科学竞赛平台,它拥有由经验丰富的数据科学家社区贡献的大量技术报告和代码。为了使大模型智能体能够高效地利用这些专家知识,团队采用了一个经典的人工智能问题解决范式 —— 基于案例的推理。
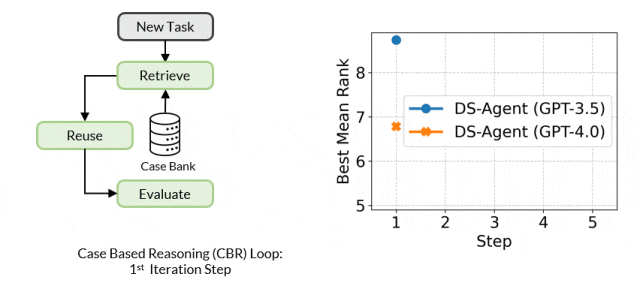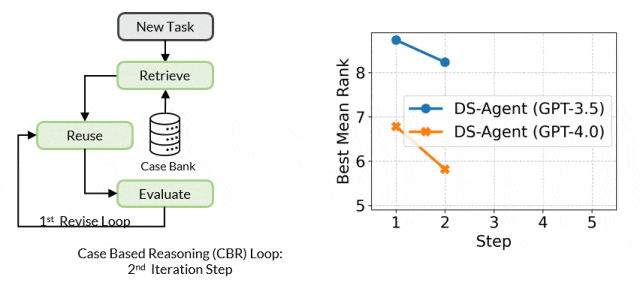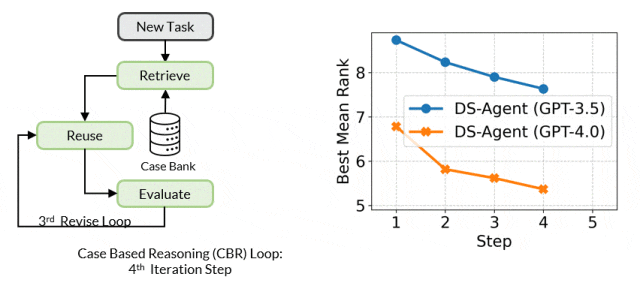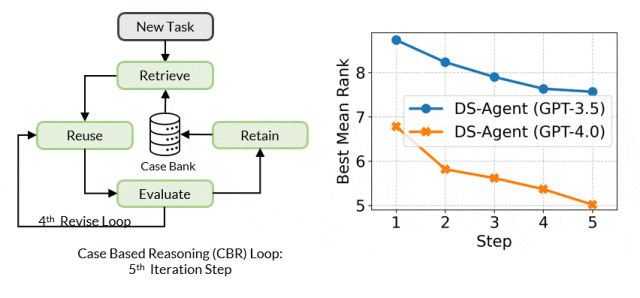
基于案例的推理的核心工作机制是维护一个案例库来不断存储过往经验。当出现一个新问题时,CBR 会在案例库中检索相似的过往案例,并尝试复用这些案例的解决方案来解决新问题。随后,CBR 会评估解决方案的有效性并根据反馈修订解决方案,这一过程中的成功的解决方案会被增加到案例库中以供未来复用。
在此基础上,团队提出 DS-Agent,利用 CBR 使大模型智能体能够分析、提取和重用 Kaggle 上的人类专家见解,并根据实际的执行反馈迭代修订解决方案,从而实现面向数据科学任务的持续性能提升。
框架细节
总体上,DS-Agent 实现了两种模式,以适应不同的应用阶段和资源要求。
标准模式(开发阶段):DS-Agent 采用 CBR 构建自动化迭代流程,这模拟了数据科学家在搭建和调整机器学习模型时的连续探索过程,通过不断的实验和优化以求达到最佳解决方案。
低资源模式(部署阶段):DS-Agent 复用开发阶段积累的成功案例来生成代码,这大大减少了对计算资源和基座模型推理能力的需求,使得开源大模型解决自动化数据科学任务成为可能。
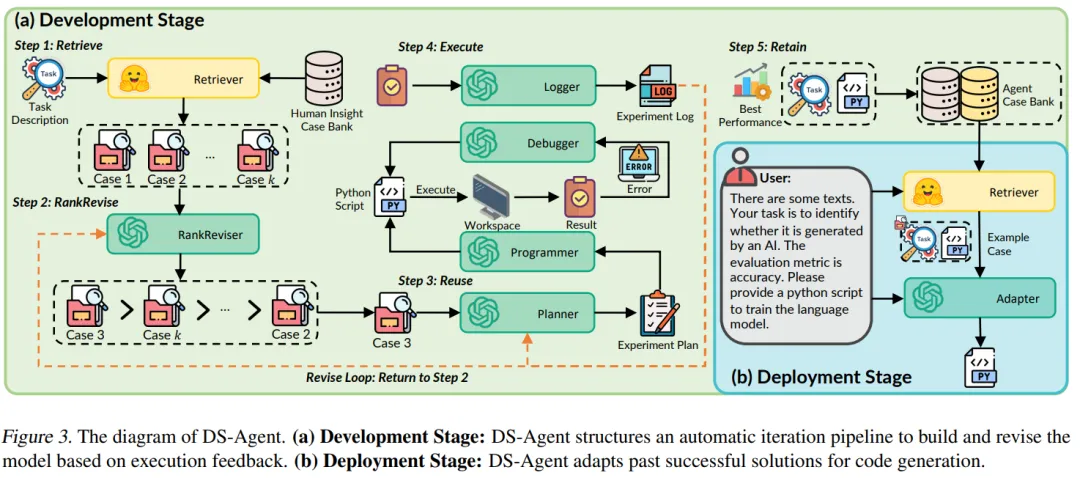
开发阶段中,给定一个新的数据科学任务,DS-Agent 首先从 Kaggle 中检索出与任务相关的人类专家知识,并在此基础上构建初步的解决方案。紧接着,它进入一个迭代循环,通过编程和调试来训练机器学习模型,以获得在测试集上的性能指标。这些反馈指标成为评价和改进解决方案的关键依据。DS-Agent 会根据这些指标对模型设计进行必要的修改,以寻求最优的模型设计。在这个过程中,那些最优的机器学习解决方案被保存在案例库中,为将来遇到类似任务时提供了参考。
部署阶段下,DS-Agent 的工作模式变得更加直接和高效。在这个阶段,它直接检索并复用经过验证的成功案例来生成代码,而无需再次从头开始探索。这样不仅降低了对计算资源的需求,使得 DS-Agent 能够快速响应用户的需求;还显著降低了对大模型基座能力的要求,以一种低资源的方式提供高质量的机器学习模型。
实验设置
我们收集了 30 种不同的数据科学任务,覆盖了三种主要数据模态(文本、表格和时间序列)以及两大机器学习核心问题(分类和回归),并设计了不同的评价指标来保证任务的多样性。
开发阶段实验结果
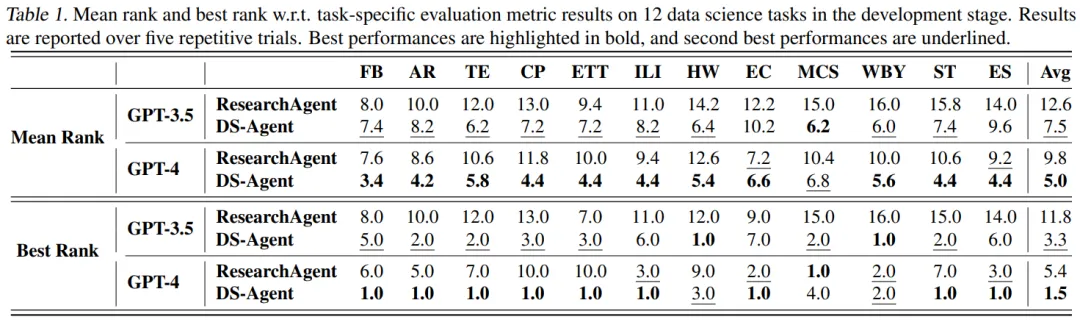
在开发阶段中,DS-Agent 使用 GPT-4 首次在数据科学任务中实现了 100% 的成功率;相比之下,DS-Agent 即使使用 GPT-3.5 也展现出了比最强基线 ResearchAgent 使用 GPT-4 时还要更高的成功率。
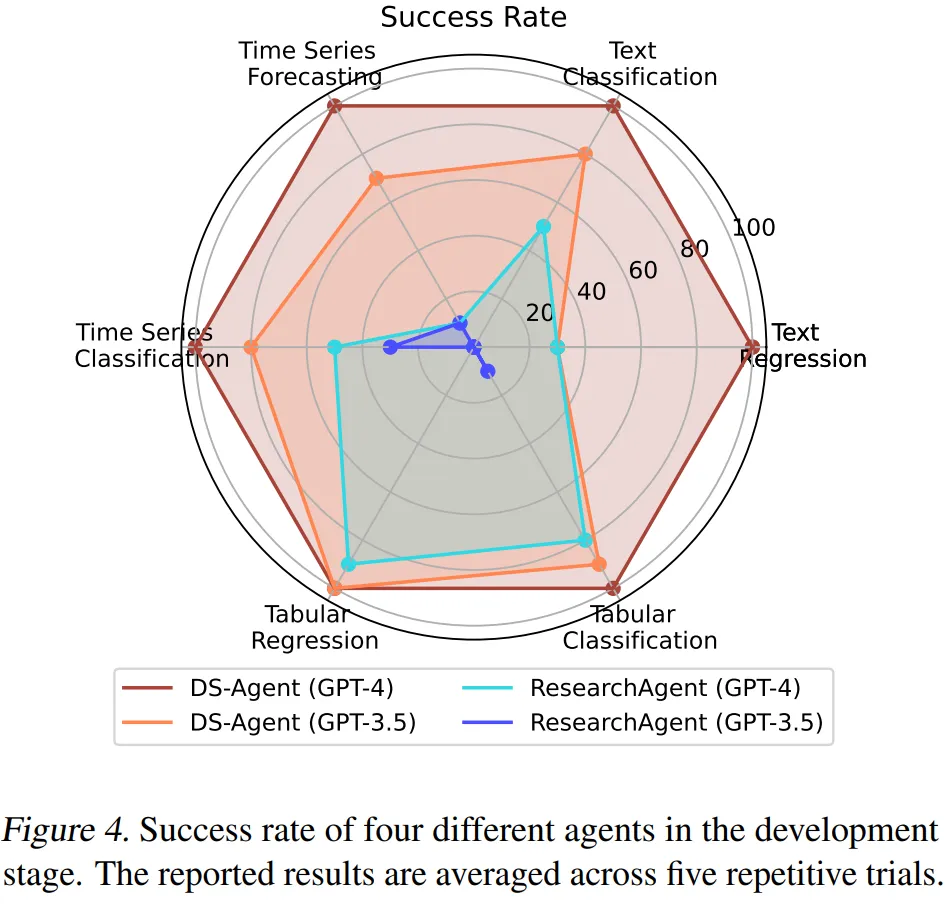
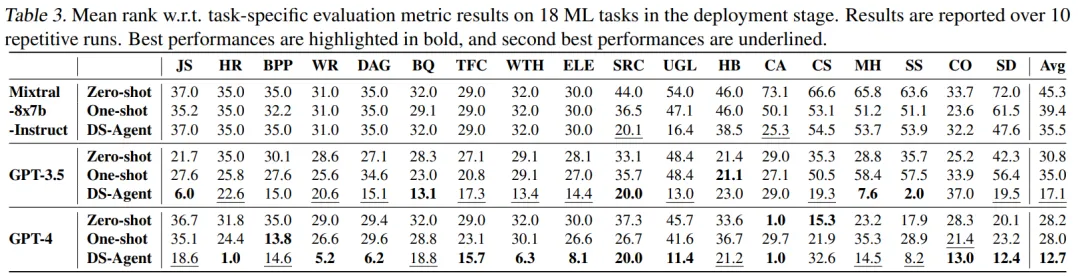
此外,DS-Agent 使用 GPT-4 和 GPT-3.5 时,分别在测试集评价指标中取得了第一和第二的成绩,显著优于最强基线 ResearchAgent。
部署阶段实验结果
部署阶段中,DS-Agent 使用 GPT-4 时,取得了首次接近 100% 的一次成功率,同时将开源模型 Mixtral-8x7b-Instruct 的一次成功率从 6.11% 跃升到了 31.11%。
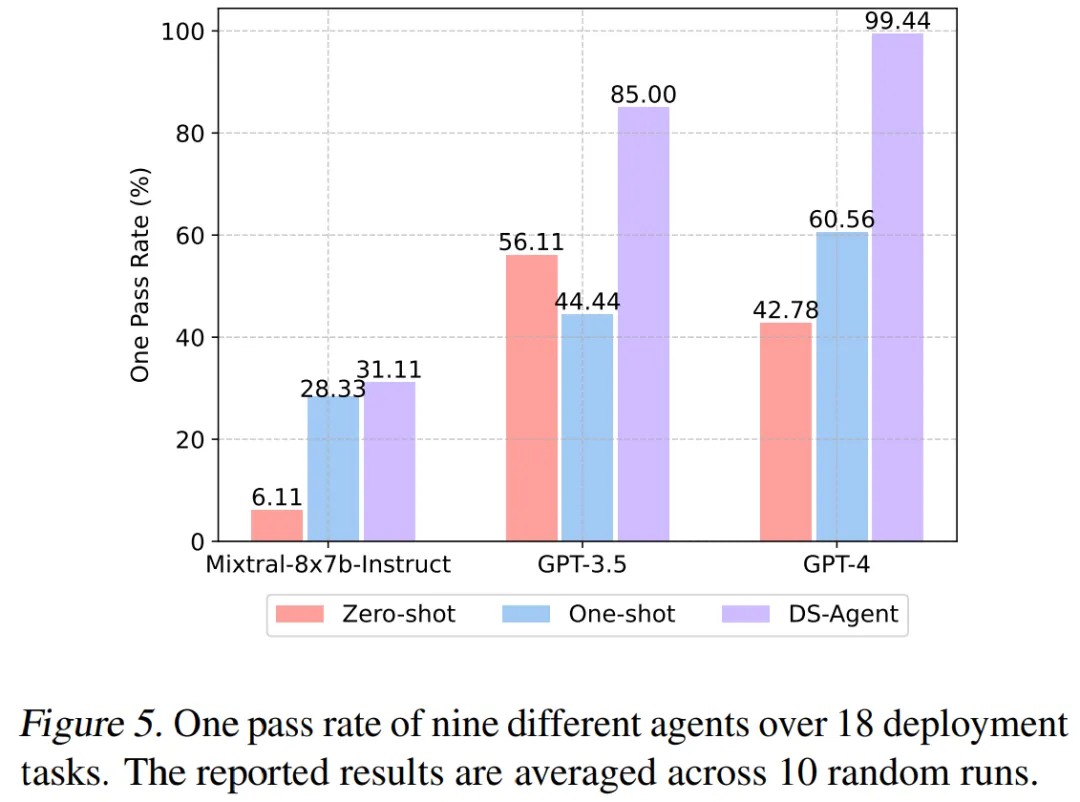
在测试集指标评估中,DS-Agent 使用 GPT-4 和 GPT-3 时,取得了第一和第二的成绩;然而遗憾的是,开源大模型 Mixtral-8x7b-Instruct 在 DS-Agent 的加持下仍然没有超越 GPT-3.5。
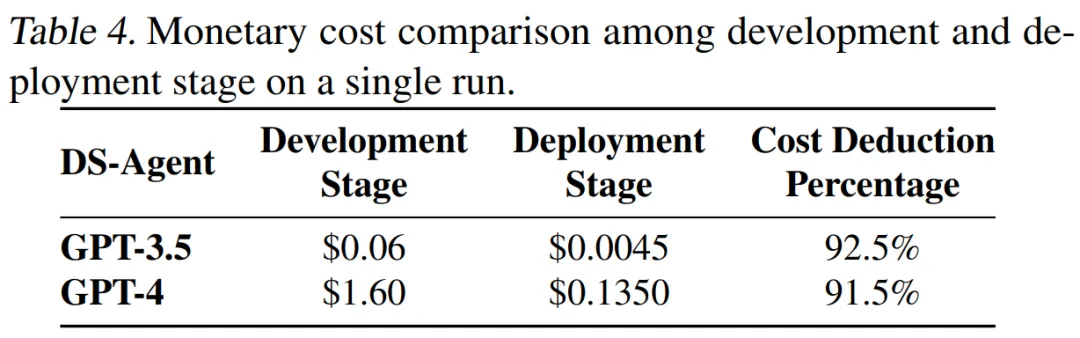
最后,我们对 DS-Agent 在两种不同模式下的 API 调用成本进行了分析。通过对比,我们发现在开发阶段,DS-Agent 分别对 GPT-4 和 GPT-3.5 进行调用时,单次成本分别是 1.60 美元和 0.06 美元。然而,在部署阶段,成本得到了显著降低:DS-Agent 单次使用 GPT-4 的成本下降至仅需 13 美分,而单次使用 GPT-3.5 的成本更是低至不足 1 美分。这意味着在部署阶段,与开发阶段相比,我们实现了超过 90% 的成本节省。
借助 DS-Agent,即便你不懂编程、没学过机器学习,也能轻松应对各种复杂的数据分析挑战,瞬间获得深入的业务洞察,进行有效的决策支持,优化策略,并预测未来趋势,从而使企业数据部门的工作效率有望得到大幅提升。试想一下,营销人员只需用自然语言描述需求,智能体就能快速生成用户画像和营销策略分析;金融分析师告别手动建模的繁琐,转而与智能体探讨市场趋势…… 这一切可能很快就会成为现实。当然,自动化数据科学还处于起步阶段,离规模化应用尚需时日。但 DS-Agent 的出现无疑为我们展现了一幅令人期待的未来图景。随着人工智能的不断发展,冗杂的数据分析工作有朝一日或将被 AI 接管,而人类则可以把更多时间放在洞见思考和创新决策之上。




还没有评论,来说两句吧...