

随着开源基础模型的爆炸式增长,例如 Llama-2、Falcon 和 Bloom 等。加上国内大厂也争先恐后地为自家的产品上AI能力。
我们见识了大模型的生产力,也想有一个属于自己的私有模型,但是目前使用API的方式,百度的文言一心API只能调用一次,讯飞的星火的API直接报内部服务器错误(可能是我使用姿势不对,与平台无关😁)。而且使用API的方式也涉及到数据安全的问题(可以看之前的文章)。
那能不能用开源模型,用自己的数据来微调一下,打造一个自己的专属模型呢?然而,从成本的角度来看,这些模型中大部分模型对于一般人来说来说几乎不可能使用,但是也有比较经济的办法(一个开源项目似乎可以帮忙实现,访问地址文末给出)。
门槛
硬件是一个比较高的门槛,可能你已经尝试过在本地跑这些模型但是没有成功,让我们看看 Meta 的 Llama-2 模型的硬件要求。
Llama-2模型有70亿参数,要在GPU上以完整精度加载模型,即32位(或浮点32位),以进行下游训练或推理,每10亿参数大约需要4GB内存,因此,仅仅是加载Llama-2模型,以完整精度需要大约280GB内存。
不过实际上Llama-2 实际上是以 16 位而不是 32 位发布的(不过很多 LLM 是以 32 位发布的)。加载 Llama-2 70B 将花费 180GB。(其实原理都是一样的,就像我们使用Redis 一样,如果想让它占用较小的内存,就用32位而不是64位编译它)。
所以,我们也可以以节约内存为目的,选择加载不同精度级别的模型(以牺牲性能为代价)。如果加载 8 位精度的模型,每十亿个参数将需要 1GB 内存,这仍然需要 70GB GPU 内存才能正常加载。
而且这还没有谈到微调。如果使用AdamW优化器进行微调,每个参数需要8字节的GPU内存。对于Llama-2来说,这意味着额外需要560GB的GPU内存。总的来说,需要在630GB到840GB之间的GPU内存来进行Llama-2模型的微调。
我们可以看看某东上显卡的价格
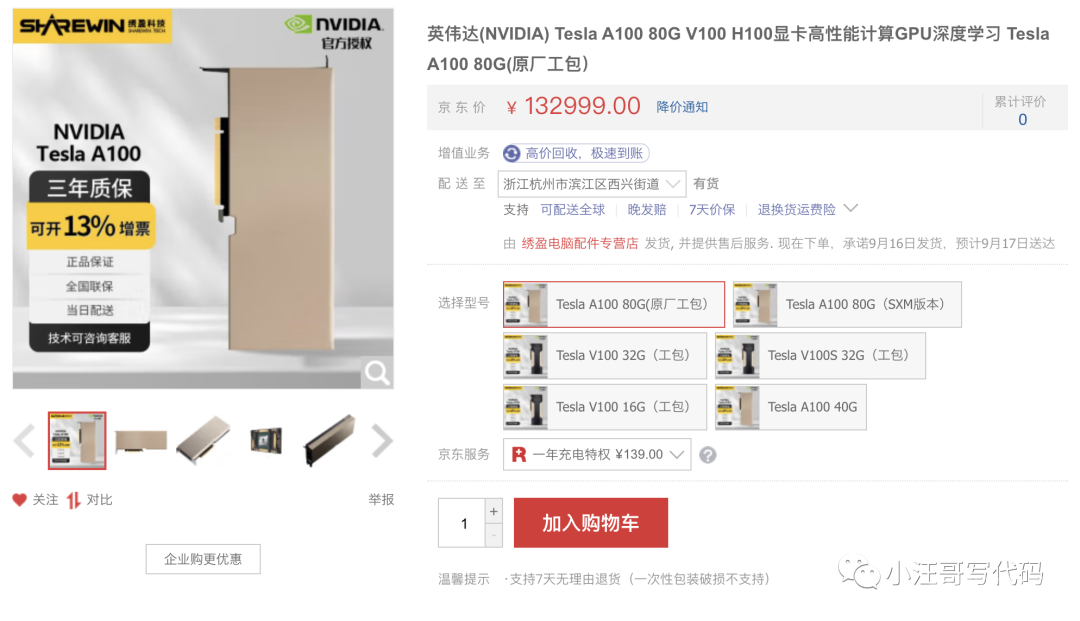
如果你想微调 Llama-2,你将需要至少八个这样的 GPU,你可以算算需要多少money。
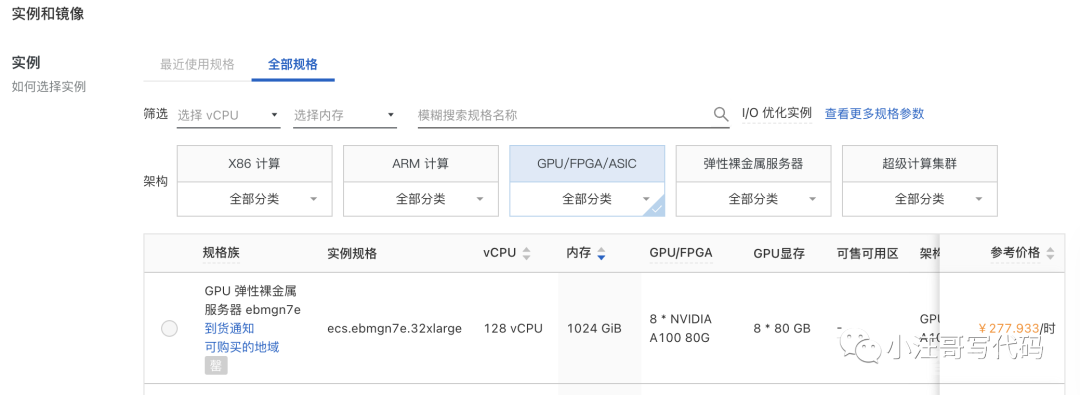
如果使用云环境,按需使用的话,每小时也需要277.933,而且还没有货。
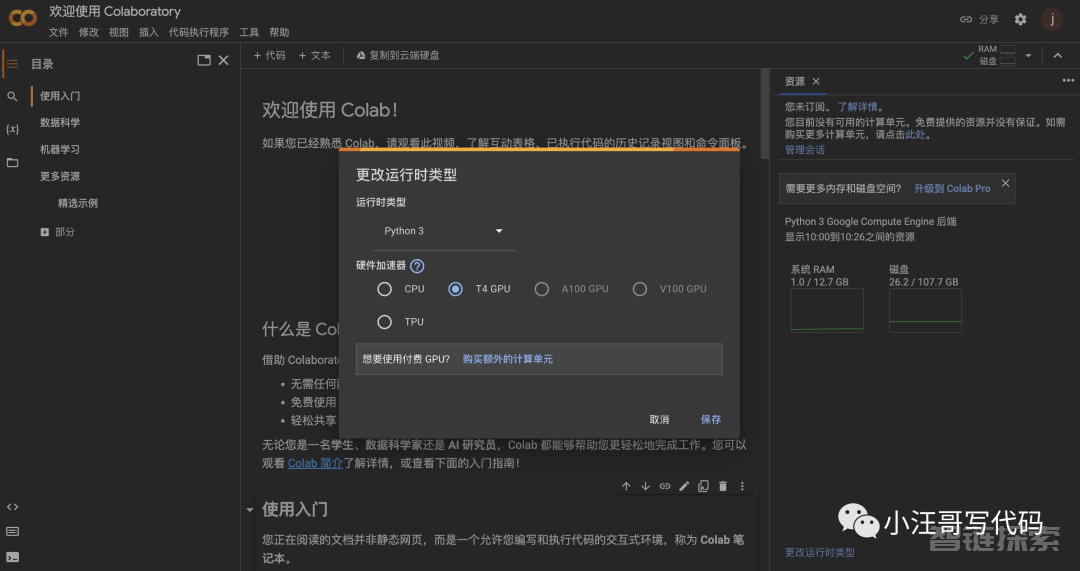
但是如果你只是想学习一下,那么也可以使用Google的Colaboratory( 简称"Colab"),Colab可以给我们分配免费的GPU使用。任何人都可以通过浏览器编写和执行任意 Python 代码。
Colab 中的 GPU 是随机分配,通常包括 Nvidia K80、T4、P4 和 P100。免费用户大多数只能使用速度较慢的 K80 GPU,订阅Colab Pro(每月9.9美元)可以使用 T4 或 P100 GPU。访问地址放到文章末尾
那还有其他选择吗?目前有一个开源方案是Petals
什么是PETALS
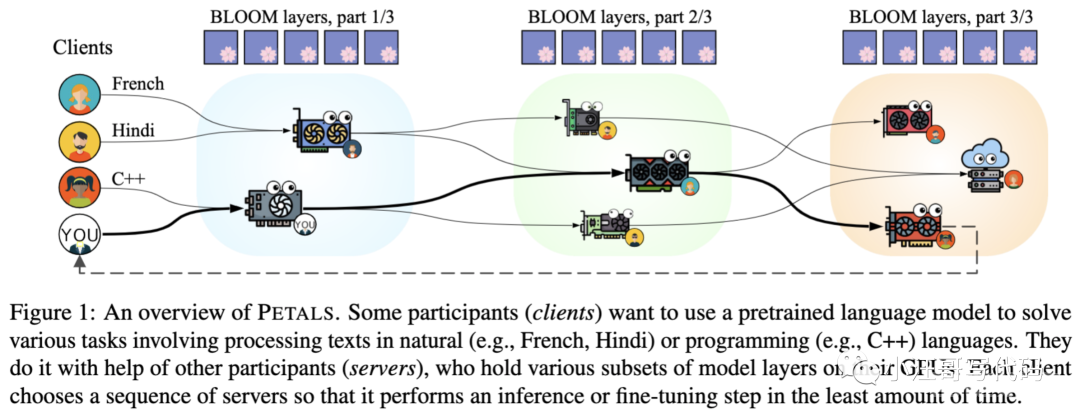
Petals采用客户端-服务器架构。客户端是寻求使用LLM进行推理或微调的一方。服务器则是第三方,他们选择分配一部分GPU资源给Petals网络。
如果你用种子下载过资源,就能理解它的运行原理。BT下载这玩意儿,下载同一个文件的人越多,这个文件的下载速度就越快,因为每个下载用户都会成为一个“资源节点”,互通有无。Petals道理和这个差不多,就是把大家伙的GPU都利用起来,协同推理/微调同一个大模型。
用了它,你的GPU实际上只需要加载大模型的一小部分,就能把模型跑起来。
举个例子:
阿张想基于Llama搞个懂法语的语言大模型,而小李则想微调Llama让它学会C++编程。尽管任务不同,但两者涉及的一些步骤却是共通的。
此时包括阿张小李在内的Petals用户们,自个儿的GPU里已分别加载好了模型的一部分(子集)。
于是,阿张和小李就可以通过网络寻求其他用户的帮助,利用别人已经拥有的模型子集,在最短时间内对Llama进行微调。同时,他们GPU上的模型资源也会被其他用户利用。
 图片
图片
这样的话,现在来运行Llama-2模型进行推理,GPU要求已经降低到仅需不到12GB的GPU内存。
下面是Petals基于BLOOM-176B模型的测试数据:
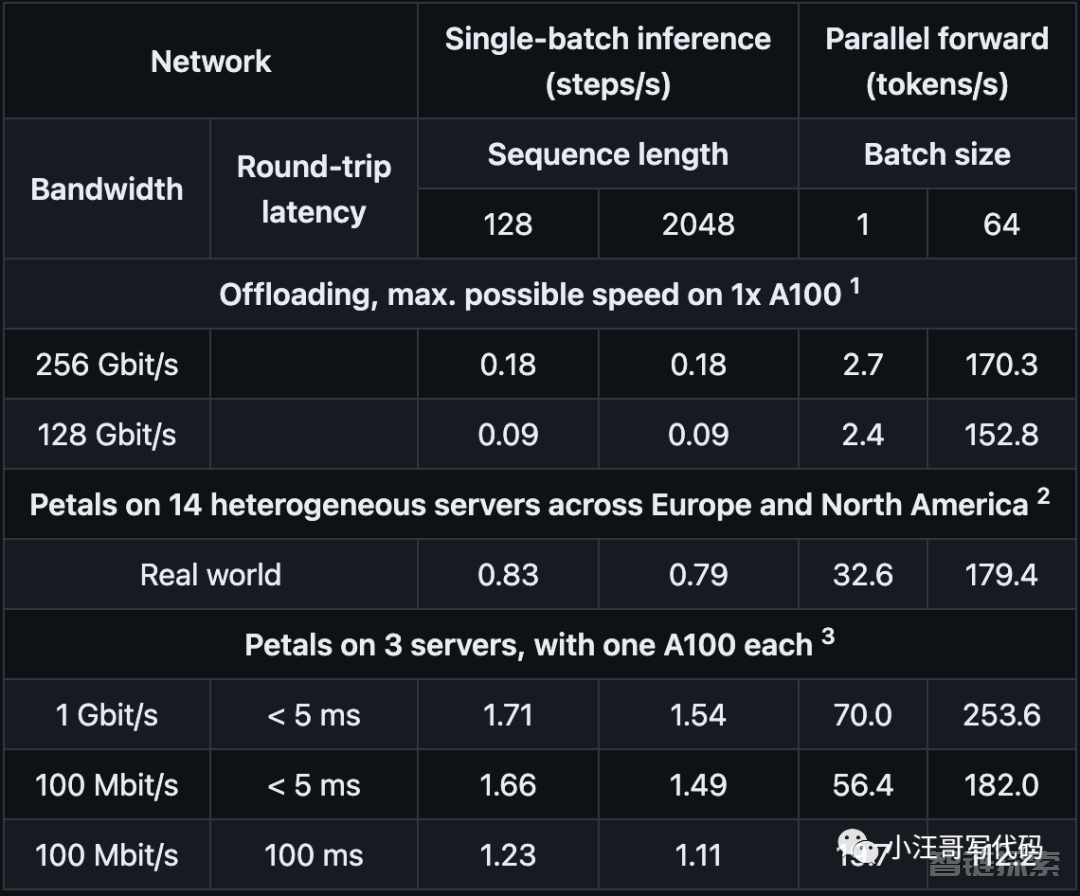 图片
图片
如果你感兴趣,还可以直接在官方提供的Colab链接上试玩一下,地址在文章末尾。
 图片
图片
最后
虽然Petals 提供了一个解决方案,但是它并不是时时刻刻都能使用的,网络上根本没有足够的服务器来实现它。就拿Llama-2–70b-chat-hf 模型来说,有时候找不到在线服务器。
可以在这里看到实时监控 https://health.petals.dev/
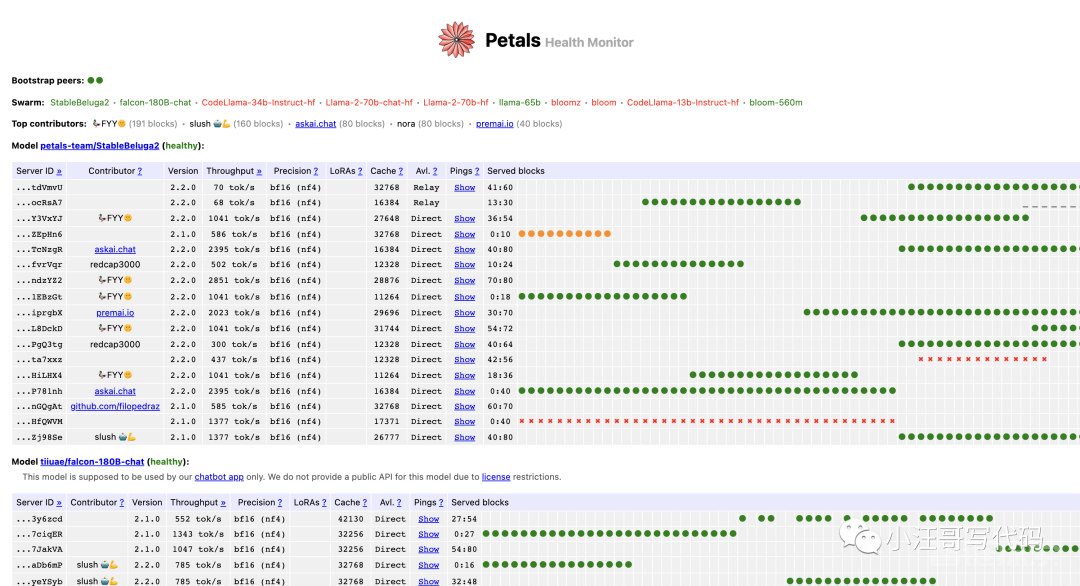 图片
图片
还有一些隐私和数据安全问题,因为在第一层模型上运行的服务器可以对它们进行逆向工程以恢复客户端的输入,这显然不适合涉及敏感数据的用例。




还没有评论,来说两句吧...