

2005年,划时代之作「The Graph Neural Network Model」的问世,将图神经网络带到每个人面前。
在此之前,科学家处理图数据的方式是,在数据预处理阶段,将图转换为一组「向量表示」。
而CNN的出现彻底改变这种信息丢失的弊端,近20年来,一代又一代模型不断演变,推动ML领域进步。
今天,谷歌正式官宣发布TensorFlow GNN 1.0(TF-GNN)——用于大规模构建GNN的经过生产测试的库。
它既支持在TensorFlow中的建模和训练,也支持从大型数据存储中提取输入图。
TF-GNN是专为异构图从头开始构建的,其中对象和关系的类型由不同的节点和边集合来表示。
现实世界中的对象及其关系以不同的类型出现,而TF-GNN的异构焦点,使得表示它们变得非常自然。
谷歌科学家Anton Tsitsulin表示,复杂的异构建模又回来了!

TF-GNN 1.0首面世
对象及其相互之间的关系,在我们的世界中无处不在。
而关系对于理解一个对象的重要性,不亚于孤立地看待对象本身的属性,比如交通网络、生产网络、知识图谱或社交网络。
离散数学和计算机科学长期以来一直将这类网络形式化为图,由「节点」以各种不规则方式通过边任意连接而成。
然而,大多数机器学习算法只允许输入对象之间存在规则统一的关系,如像素网格、单词序列,或完全没有关系。
图形神经网络,简称GNN,是一种强大的技术,既能利用图的连通性(如早期算法DeepWalk和Node2Vec),又能利用不同节点和边输入特征。
GNN可以对图的整体(这种分子是否以某种方式做出反应?)、单个节点(根据引用,这份文档的主题是什么?)、潜在的边(这种产品是否可能与另一种产品一起购买?)进行预测。
除了对图形进行预测之外,GNN还是一个强大的工具——用于弥合与更典型的神经网络用例之间的鸿沟。
它们以连续的方式对图的离散关系信息进行编码,从而可以将其自然地纳入另一个深度学习系统。
谷歌在今天正式宣布用于大规模构建GNN的经过生产测试的库——TensorFlow GNN 1.0(TF-GNN)。
在TensorFlow中,这样的图形由 tfgnn.GraphTensor 类型的对象表示。
这是一个复合张量类型(一个Python类中的张量集合),在 tf.data.Dataset 、 tf.function 等中被接受为「头等对象」。
它既能存储图结构,也能存储节点、边和整个图的特征。
GraphTensors的可训练变换可以定义为高级Kera API中的Layers对象,或直接使用 tfgnn.GraphTensor 原语。
GNN:对上下文中的对象进行预测
接下来,进一步解释下TF-GNN,可以看下其中一个典型的应用:
预测一个庞大数据库中,由交叉引用表定义的图中某类节点的属性
举个例子,计算机科学(CS)的引文数据库arxiv论文中,有一对多的引用和多对一的引用关系,可以预测每篇论文的所在的主题领域。
与大多数神经网络一样,GNN也是在许多标记样本(约数百万个)的数据集上进行训练的,但每个训练步骤只包含一批小得多的训练样本(比如数百个)。
为了扩展到数百万个样本,GNN会在底层图中合理小的子图流上进行训练。每个子图包含足够多的原始数据,用于计算中心标记节点的GNN结果并训练模型。
这一过程,通常被称为子图采样,对于GNN训练是极其重要的。
现有的大多数工具都是以批方式完成采样,生成用于训练的静态子图。
而TF-GNN提供了,通过动态和交互采样来改进这一点的工具。
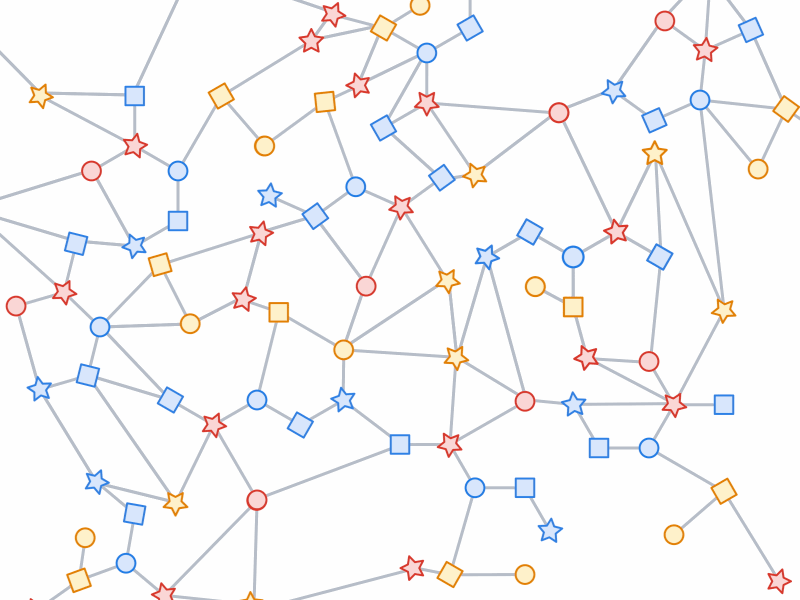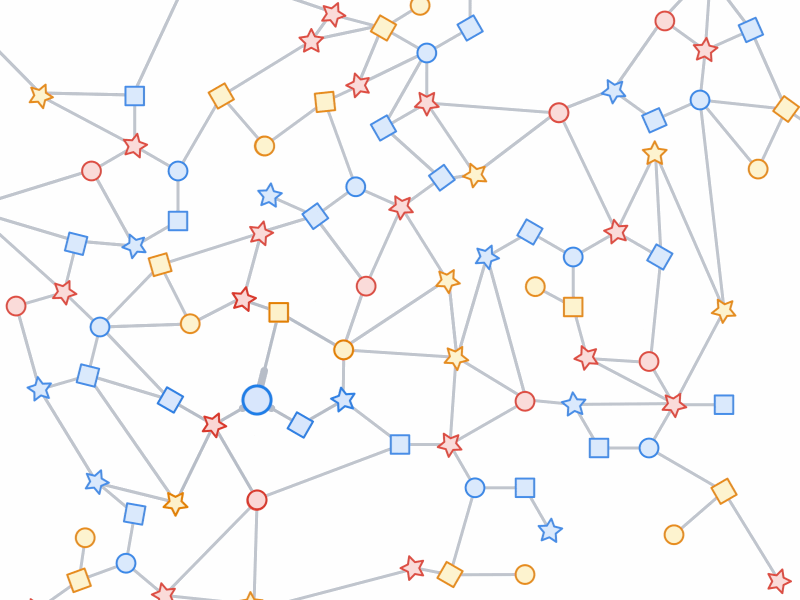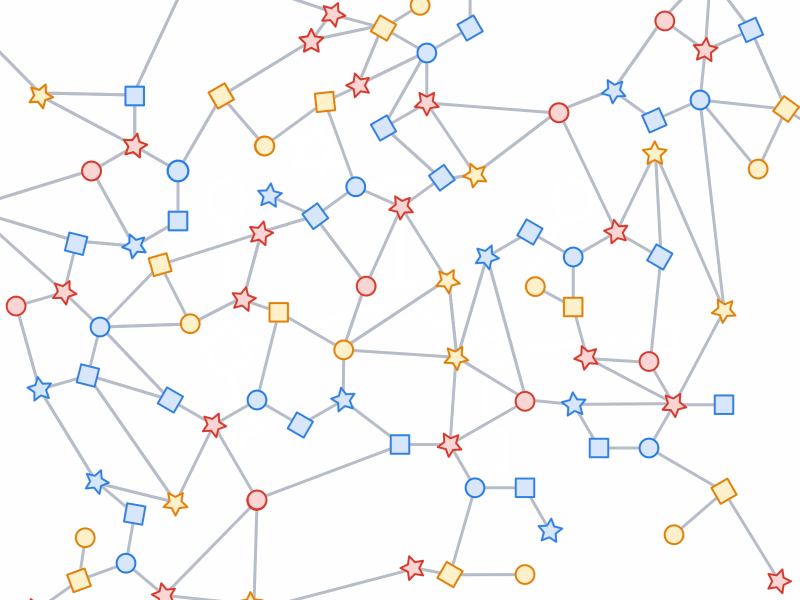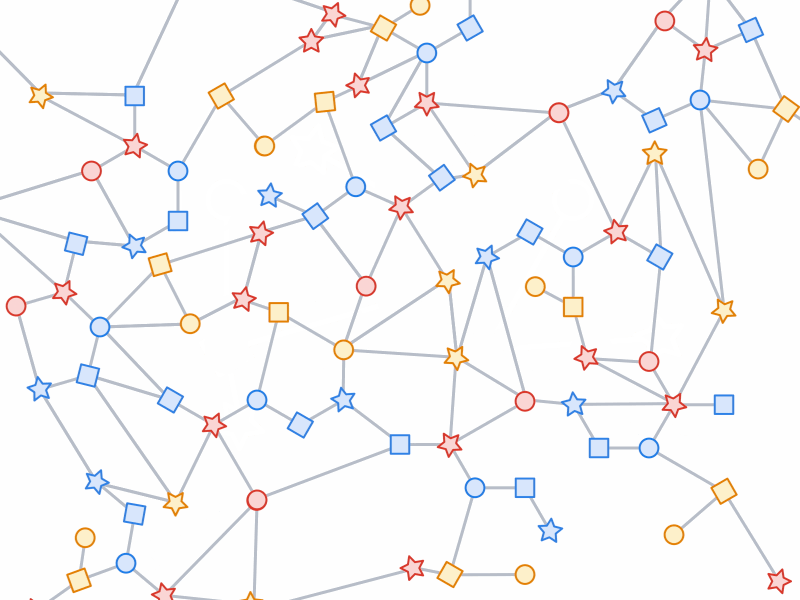
子图抽样过程,即从一个较大的图中抽取小的、可操作的子图,为GNN训练创建输入示例
TF-GNN 1.0推出了灵活的Python API,用于配置所有相关比例的动态或批处理子图采样:在Colab笔记中交互采样。
具体来说,对存储在单个训练主机主内存中的小型数据集进行「高效采样」,或通过Apache Beam对存储在网络文件系统中的庞大数据集(多达数亿节点和数十亿条边)进行分布式采样。
在这些相同的采样子图上,GNN的任务是,计算根节点的隐藏(或潜在)状态;隐藏状态聚集和编码根节点邻域的相关信息。
一种常见的方法是「消息传递神经网络」。
在每一轮消息传递中,节点沿着传入边接收来自邻节点的消息,并从这些边更新自己的隐藏状态。
在n轮之后,根节点的隐藏状态反映了,n条边内所有节点的聚合信息(如下图所示,n=2)。消息和新的隐藏状态由神经网络的隐层计算。
在异构图中,对不同类型的节点和边使用单独训练的隐藏层通常是有意义的。

图为一个简单的「消息传递神经网」,在该网络中,每一步节点状态都会从外部节点传播到内部节点,并在内部节点汇集计算出新的节点状态。一旦到达根节点,就可以进行最终预测
训练设置是,通过将输出层放置在已标记节点的GNN的隐藏状态之上、计算损失(以测量预测误差)并通过反向传播更新模型权重来完成的,这在任何神经网络训练中都是常见的。
除了监督训练之外,GNN也可以以无监督的方式训练,可以让我们计算节点及其特征的离散图结构的连续表示(或嵌入)。
然后,这些表示通常在其他ML系统中使用。
通过这种方式,由图编码的离散关系信息,就能被纳入更典型的神经网络用例中。TF-GNN支持对异构图的无监督目标进行细粒度规范。
构建GNN架构
TF-GNN库支持构建和训练,不同抽象层次的GNN。
在最高层,用户可以使用与库绑定在一起的任何预定义模型,这些模型以Kera层表示。
除了研究文献中的一小部分模型外,TF-GNN还附带了一个高度可配置的模型模板,该模板提供了经过精心挑选的建模选择。
谷歌发现这些选择,为我们的许多内部问题提供了强有力的基线。模板实现GNN层;用户只需从Kera层开始初始化。
在最低层,用户可以根据用于在图中传递数据的原语,从头开始编写GNN模型,比如将数据从节点广播到其所有传出边,或将数据从其所有传入边汇集到节点中。
当涉及到特征或隐藏状态时,TF-GNN 的图数据模型对节点、边和整个输入图一视同仁。
因此,它不仅可以直接表示像MPNN那样以节点为中心的模型,而且还可以表示更一般形式的的图网络。
这可以(但不一定)使用Kera作为核心TensorFlow顶部的建模框架来完成。
训练编排
虽然高级用户可以自由地进行定制模型训练,但TF-GNN Runner还提供了一种简洁的方法,在常见情况下协调Kera模型的训练。
一个简单的调用可能如下所示:
Runner为ML Pain提供了现成的解决方案,如分布式训练和云TPU上固定形状的 tfgnn.GraphTensor 填充。
除了单一任务的训练(如上所示)外,它还支持多个(两个或更多)任务的联合训练。
例如,非监督任务可以与监督任务混合,以形成具有特定于应用的归纳偏差的最终连续表示(或嵌入)。调用方只需将任务参数替换为任务映射:
此外,TF-GNN Runner还包括用于模型归因的集成梯度实现。
集成梯度输出是一个GraphTensor,其连接性与观察到的GraphTensor相同,但其特征用梯度值代替,在GNN预测中,较大的梯度值比较小的梯度值贡献更多。
总之,谷歌希望TF-GNN将有助于推动GNN在TensorFlow中的大规模应用,并推动该领域的进一步创新。




还没有评论,来说两句吧...