


Part 01、 Series和DataFrame:Pandas的核心
Pandas的两个主要数据结构是Series和DataFrame。Series是一维标记数组,类似于Python中的列表。而DataFrame是二维标记数据结构,类似于关系型数据库中的表格。这两个数据结构的简洁性和灵活性使得数据的加载、处理和分析变得非常高效。
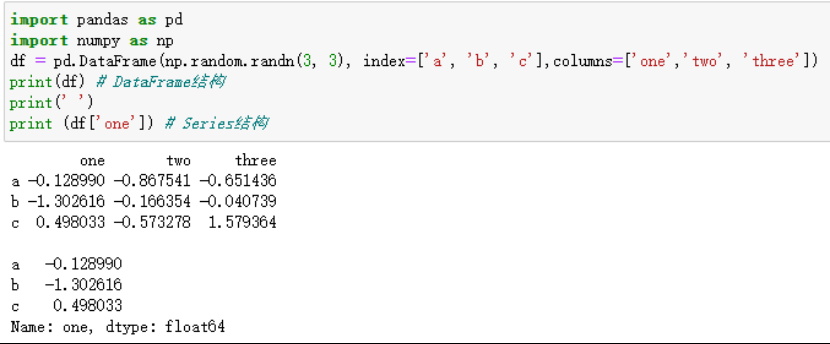
图1 Series和DataFrame的数据结构
Part 02、数据清洗和处理的便捷性
Pandas提供了丰富的数据处理功能,包括数据的选择、过滤、排序、合并等。通过Pandas,我们可以轻松处理缺失值、重复数据和异常数据,使得数据清洗变得简单而不失灵活性。

图2 Pandas fillna()填充空值
Part 03、快速的向量化运算
Pandas通过底层的NumPy数组进行向量化计算,大大加快了数据处理的速度。它允许用户避免使用显式循环,而是通过矢量化运算来处理数据,这在处理大规模数据时尤为重要。
Part 04、强大的分组和聚合功能
Pandas中的groupby操作允许我们根据某些条件将数据分组,然后进行聚合操作,如计算平均值、求和等。这为数据分析和汇总提供了便利,让复杂的数据分析变得简单。
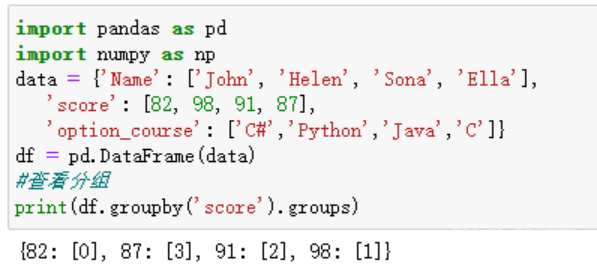
图3 Pandas groupby分组操作
Part 05、时间序列处理
Pandas对时间序列数据提供了专门的支持,可以方便地进行时间索引、重采样、滚动窗口计算等操作。这使得时间序列数据的处理和分析变得更加高效。
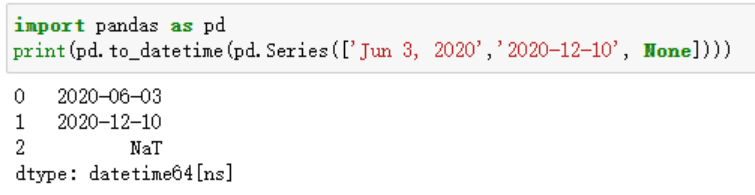
图4 Pandas to_datetime() 函数将 series转换为日期对象
Part 06、总结与其他数据科学库的无缝集成
Pandas与其他流行的数据科学库(如NumPy、Matplotlib、Scikit-learn等)无缝集成,使得数据处理、可视化和机器学习流程之间的衔接更加流畅。这种整合性让数据科学家能够更专注于解决问题,而不用过多关注数据转换和接口问题。
Part 07、总结
Pandas作为Python数据科学生态系统的核心库,为数据处理和分析提供了强大的工具和便利性。从数据清洗到机器学习,Pandas都展现出其魅力,成为数据科学家们的得力助手,极大地提高了数据处理和分析的效率和便捷性。
👉参考文献
[1] McKinney, Wes. "Data Structures for Statistical Computing in Python." Proceedings of the 9th Python in Science Conference. 2010.
[2] VanderPlas, Jake. "Python Data Science Handbook." O'Reilly Media, 2016.
[3] Reback, Jeffrey R., et al. "pandas-dev/pandas: Pandas." Zenodo, 2021.
[4] McKinney, Wes. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython. O'Reilly Media, 2017.
[5] Van Rossum, Guido, and Fred L. Drake. "Python 3 Reference Manual." Scotts Valley, CA: CreateSpace, 2009.




还没有评论,来说两句吧...