

11 月 30 日,全球第一所人工智能大学——穆罕默德·本·扎耶德人工智能大学(MBZUAI),在 arXiv 预印平台发布了题为《大数据时代的数据集蒸馏》(Dataset Distillation in Large Data Era)的文章。
数据蒸馏应用及当前挑战
数据集蒸馏(Dataset distillation)引起了计算机视觉和自然语言处理各个领域的广泛关注。
数据集蒸馏的目的是从大型数据集中生成较小但具有代表性的子集,从而可以有效地训练模型,同时评估原始测试数据分布以实现良好的性能。
随着数据和模型规模的不断增长,这种数据集蒸馏概念在大数据时代变得更加重要,因为数据集通常非常庞大,带来存储、计算和处理方面的挑战。
一般来说,数据集蒸馏可以提供公平的竞争环境,使计算和存储资源有限的研究人员能够参与最先进的基础模型训练和应用程序开发,例如在当前的大数据和大模型政权中负担得起的 ChatGPT 和 Stable Diffusion。此外,通过使用蒸馏数据集,有可能减轻一些数据隐私问题,因为原始的、个人可识别的数据点可能会被排除在蒸馏版本之外。
最近,在各个研究和应用领域采用大型模型和大数据已成为显著趋势。然而,许多先前的数据集蒸馏方法主要针对 CIFAR、Tiny-ImageNet 和下采样 ImageNet-1K 等数据集,发现将其框架扩展到更大的数据集(例如完整的 ImageNet-1K)具有挑战性。这表明这些方法尚未完全按照当代的进步和主流方法论发展。
提取各种大规模数据集,优于所有先前方法
许多先前的工作旨在与原始数据集的各个方面保持一致,例如匹配训练权重轨迹、梯度、特征/BatchNorm 分布等。
在该研究中,研究人员展示了如何提取各种大规模数据集,以实现优于所有先前方法的最佳精度。
在此,MBZUAI 研究人员将注意力扩展到 ImageNet-1K 数据集之外,以 224×224 的传统分辨率进入完整 ImageNet-21K 的未知领域。这标志着在处理如此庞大的数据集以进行数据集蒸馏任务方面的开创性努力。其方法利用简单而有效的课程学习框架。精心解决每个方面,并制定强大的策略来有效地训练完整的 ImageNet-21K,确保捕获全面的知识。
具体来说,根据先前的研究,该方法最初训练一个模型,将原始数据集中的知识封装在其密集参数中。然而,研究人员引入了一个精炼的训练方案,超越了 Ridnik 等人在 ImageNet-21K 上的结果。
在数据恢复/合成阶段,研究人员采用一种策略学习方案,根据区域的难度顺序更新部分图像裁剪:从简单过渡到困难,反之亦然。通过在不同的训练迭代中调整 RandomReiszedCrop 数据增强的下限和上限来调节这一进程。
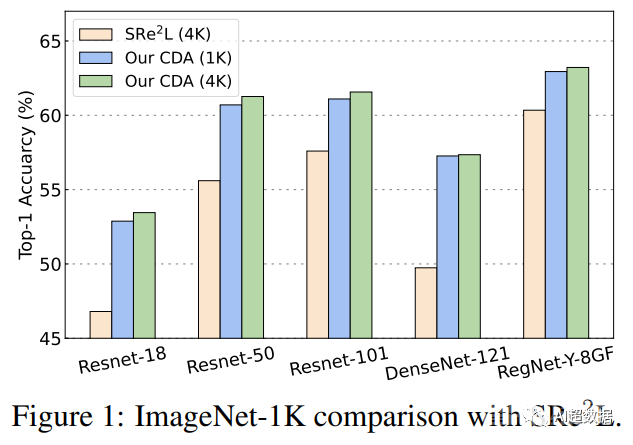
在数据合成过程中引入了一种简单而有效的课程数据增强(Curriculum Data Augmentation,CDA),它在大规模 ImageNet-1K 和 21K 上获得了在 IPC(每类图像)50 下的准确率 63.2% 和在 IPC 20 下的 36.1% 的准确率。
值得注意的是,研究人员观察到这种简单的学习方法极大地提高了合成数据的质量。在论文中,研究人员深入研究了与课程学习框架相关的数据合成的三种学习范式。首先是标准课程学习,其次是其替代方法,逆向课程学习。最后,还考虑了基本的和以前使用的不断学习的方法。
最后,研究表明,通过将所有增强功能集成在一起,所提出的模型在 ImageNet-1K/21K 上的 Top-1 准确率比当前最先进的模型高出 4% 以上,并且首次缩小了差距 与其全数据训练对应物相比,绝对值不到 15%。
此外,该研究代表了标准 224×224 分辨率下大规模 ImageNet-21K 数据集蒸馏的首次成功。
其代码和 20 个 IPC、2K 恢复预算的精炼 ImageNet-21K 数据集可在 GitHub中找到。




还没有评论,来说两句吧...