

文章开始,我们先来看一段球赛解说视频:
是不是感觉听起来不太对劲?
你的感觉没错,因为这段解说是用 AI 生成的,这个大喊「梅西!梅西!」的声音居然来自 AI。
这是 X 平台(原推特)博主 @Gonzalo Espinoza Graham 发布的一段视频。他表示,在制作过程中,他主要用到了 GPT-4V 和 TTS 两项技术。
GPT-4V 是 OpenAI 前段时间发布的一个多模态大模型,既能像原版的 ChatGPT 一样通过文字聊天,也能读懂用户在聊天中给到的图像。更令人兴奋的是,在昨天的开发者大会上,OpenAI 宣布,他们已经开放了视觉能力相关的 API——gpt-4-vision-preview。通过这个 API,开发者可以用 OpenAI 最新的 GPT-4 Turbo(视觉版)来开发新应用。
对于这个期待已久的 API,开发者们都跃跃欲试。因此,API 刚开放一天,就有不少开发者晒出了试用结果,这个球赛解说就是其中之一。
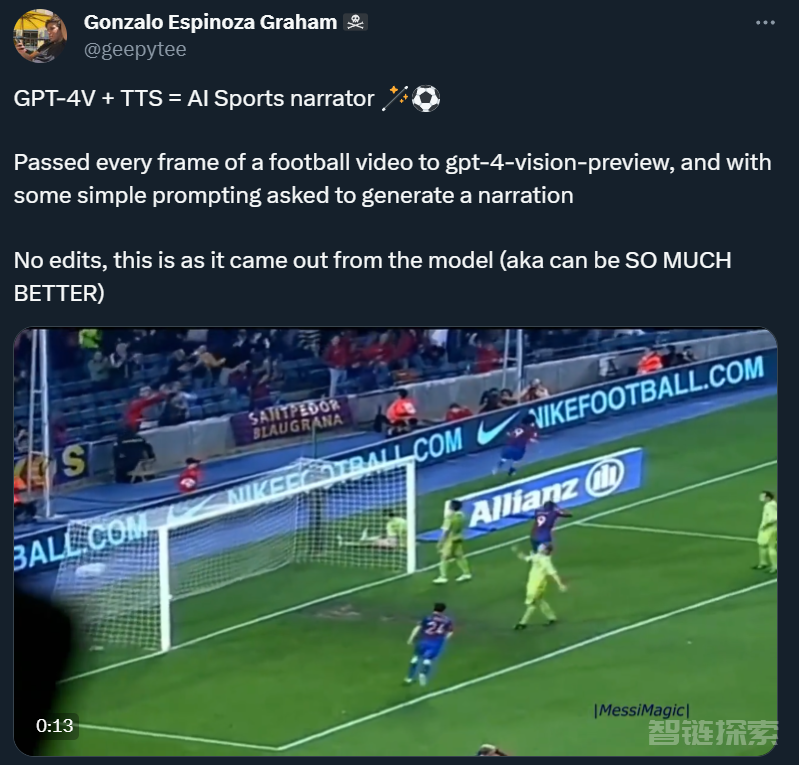
博主表示,为了制作这个解说视频,他将原视频的帧分批传给 gpt-4-vision-preview,然后通过一些简单的提示(prompt)要求模型生成一段旁白,最后把得到的结果用 TTS(文本转语音技术)转成音频,就可以得到视频中展示的效果。如果稍加编辑,理论上还能得到更好的结果。按照 OpenAI 目前的定价,制作这个视频大约要花 30 美元,作者直呼「不便宜」。
相关代码:https://github.com/ggoonnzzaallo/llm_experiments/blob/main/narrator.ipynb
除了球赛,还有开发者晒出了自己用 OpenAI 视觉 API 解说《英雄联盟》的 demo,这个 demo 用到的是 LNG 与 T1 的一场比赛视频,引起了全网 50 多万网友的围观。
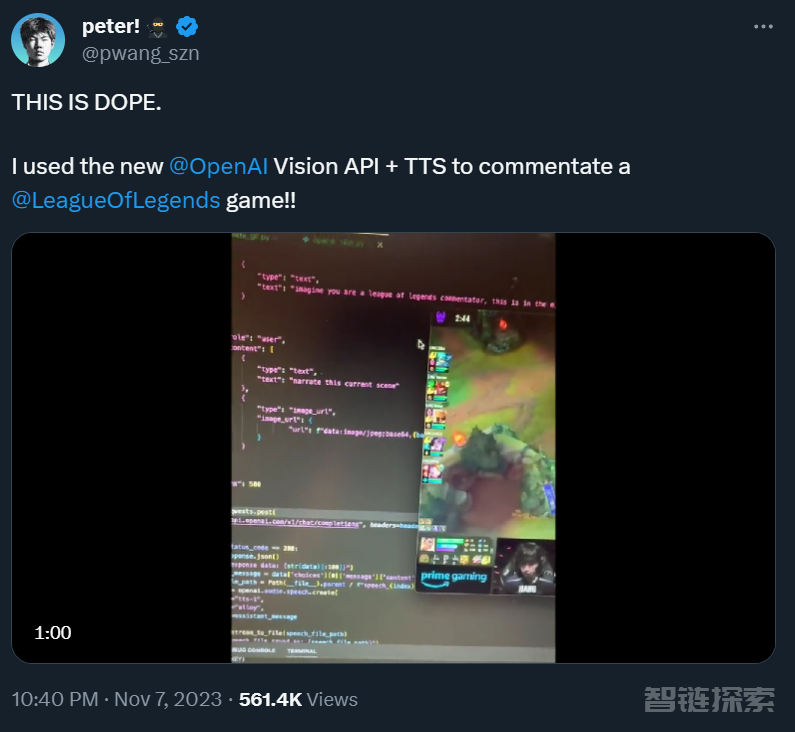
解说效果是这样的:
不过,这类视频具体要怎么做呢?好在,除了这些成品效果,部分开发者还晒出了自己总结的教程,以及每个步骤中涉及的具体工具。
从 X 平台用户 @小互晒出的内容来开,整个实现过程可以分为 7 步:
提取视频帧;
构建描述提示;
发送 GPT 请求;
制作语音解说提示;
生成语音解说脚本;
将脚本转换为音频;
将音频与视频结合。
具体内容请参见以下教程:

不过,有人在评论区提出疑问:解说的这些比赛都是以前的,实时的比赛能解说吗?

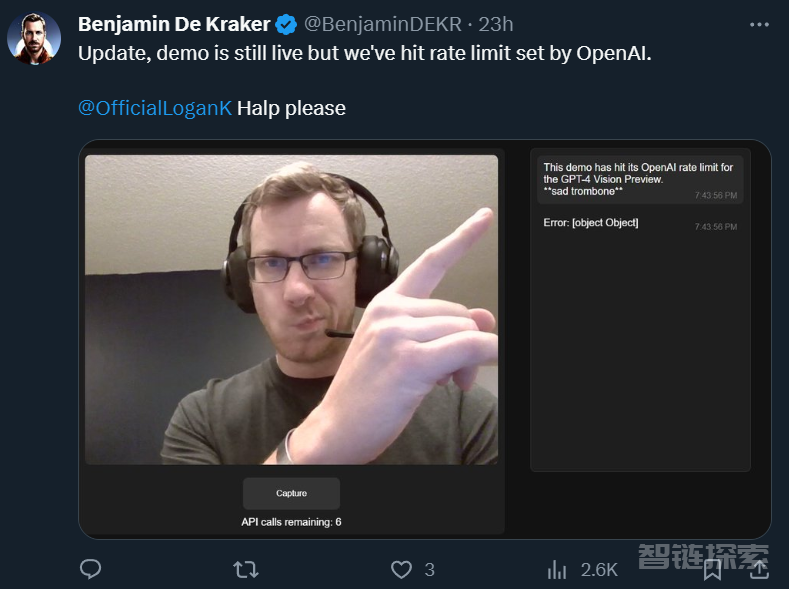
能否解说实时的比赛我们现在还看不出来,不过,确实有开发者晒出了用 OpenAI 视觉 API 实时解读摄像头内容的 demo:

项目链接:https://github.com/bdekraker/WebcamGPT-Vision
做了类似实验的开发者评价说,OpenAI 视觉 API 的识别速度很快、准确性也很高。
甚至有人直接把它当实时绘图工具来用,把手里的草图实时转换为此前调用专业绘图工具才能绘制的图表:
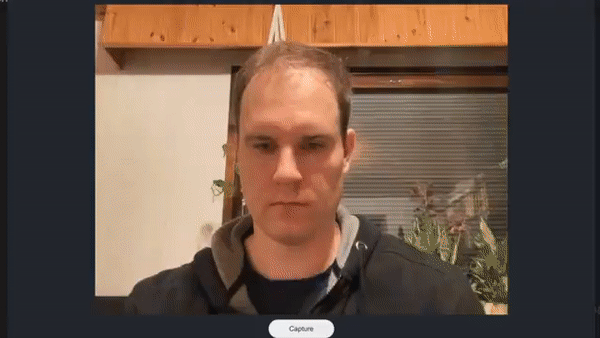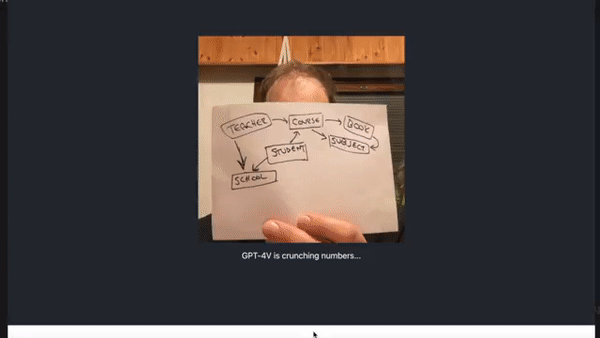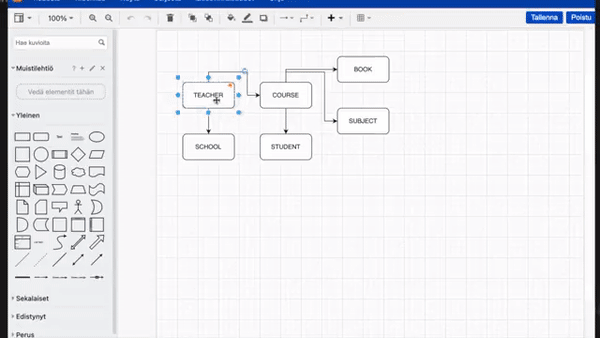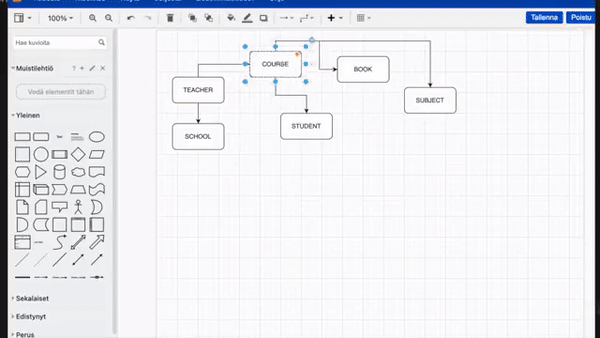
不过,这个实时效果的实验会受到 OpenAI 设置的速率限制。
可以说,OpenAI 正通过 GPT-4V 以及刚刚开放的视觉 API 让全世界看到多模态的力量,以上效果只是冰山一角。
其实,无论是在现实生活中,还是在研究领域,一个能读懂图像、视频的 AI 都有广泛的用途。
在生活中,它能用于构建更加智能的机器人,让机器人实时分析眼前的情景,随机应变,这也是当前大火的具身智能所研究的问题。


国内创业公司开发的具身智能机器人(参见《独家 | 达摩院后的下一站:陈俊波推出具身智能大模型,要给所有机器人做一颗脑袋》)
此外,它还能用于改善视障群体的生活质量,帮助他们解读视频画面和生活场景。其实,在字节跳动去年举办的一个帮助视障群体的公益比赛中,我们就能看到不少类似的创意,只是当时多模态技术还不够成熟(参见《穿颜色成对的袜子,追最新的剧:这群 coder 正帮视障者移走身上的大山》)。
在微软最近的一篇论文中,研究者也展示了他们在这方面取得的进展,比如用 GPT-4V 解读《憨豆先生》剧情。
这种优秀的视频解读能力能够帮助研究人员更好地理解视频,从而把广泛存在的视频转化为新的训练数据,训练出更聪明的 AI,形成一个闭环。
看来,一个更智能的世界正在加速到来。




还没有评论,来说两句吧...