


1、SFT需要多少条数据
SFT所需数据量
一般任务:对于大多数常见的自然语言处理任务(如文本分类、情感分析、简单对话等),SFT的数据量通常在2k-10k之间。这个范围的数据量既能保证模型学习到足够的领域知识,又不会因为数据量过大而导致训练成本过高。
复杂任务:对于复杂的任务,如数学推理、代码生成、多轮对话等,可能需要更多的数据来训练。这些任务通常需要模型具备更强的逻辑推理能力和更丰富的领域知识,因此数据量可能需要达到10k以上。
少样本学习:对于一些简单的任务,如人类阅读和生成能力,仅在1000个样本上进行SFT也可能取得不错的效果。这表明在数据质量较高的情况下,少量数据也可以有效提升模型的性能。
训练策略
Epoch数量:根据SFT数据量的大小,可以设定2-10个epoch。一般来说,epoch数量和数据量成反比关系。如果数据量较少,可以适当增加epoch数量,以确保模型能够充分学习;如果数据量较多,则可以减少epoch数量,以避免过拟合。
数据质量和效果:SFT数据的关键在于准确性和多样性,而不仅仅是数据量。高质量的数据可以显著提升模型的性能。例如,在数据比较精确的情况下,5k的数据搭配5个epoch,通常就能得到一个不错的效果。
实际操作建议
数据清洗和标注:在进行SFT之前,务必对数据进行严格的清洗和标注,确保数据的准确性和一致性。
少样本学习的优势:如果任务相对简单,可以尝试使用少样本学习策略。即使只有1000个样本,也可能通过精心设计的训练过程取得良好的效果。
复杂任务的策略:对于复杂的任务,如数学推理或代码生成,建议逐步增加数据量,并通过多轮实验调整epoch数量,以找到最优的训练策略。
2、SFT的数据配比
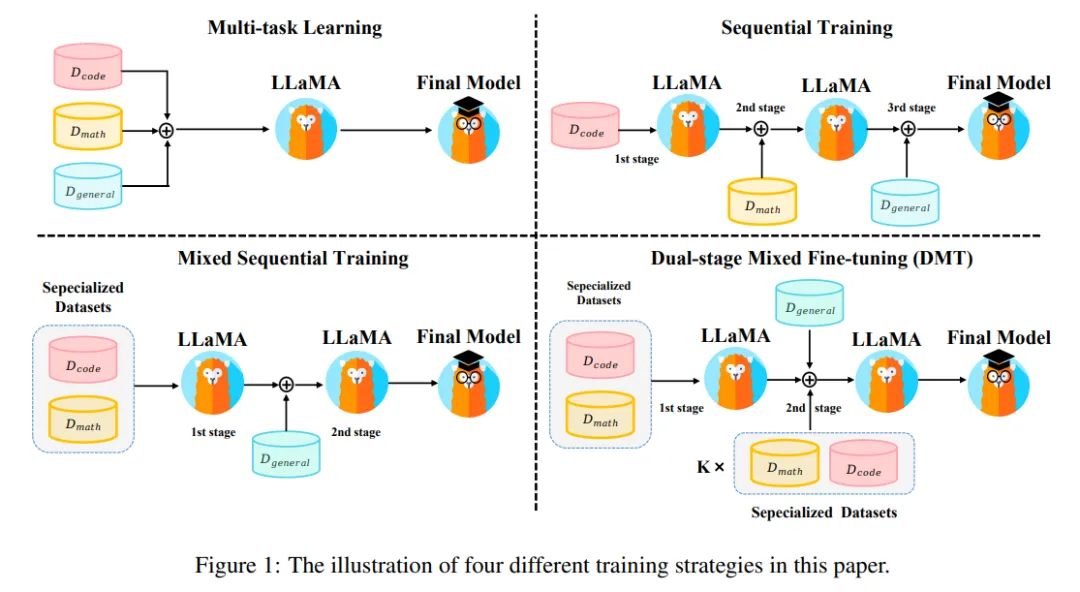
在进行SFT(监督式微调)时,数据配比是一个关键因素,它直接影响模型的性能和泛化能力。以下是根据最新搜索结果总结的SFT数据配比的建议:
数据配比的基本原则
多样化与平衡:SFT数据应包含多种类型的任务和领域,以确保模型能够学习到不同场景下的知识。例如,在多任务学习中,直接混合不同的SFT数据源进行训练,可以视为多任务学习。
避免过度集中:在数据量较低的情况下,数据组合会带来各种能力的提高,但在数据量较高的情况下,能力则会发生冲突。因此,应避免数据过度集中在某一特定任务或领域。
通用与特定能力的平衡:在数据配比中,需要平衡通用能力和特定能力的数据。例如,在双阶段混合微调(DMT)策略中,首先在特定能力数据集(如代码、数学)上进行多任务学习,然后在通用能力数据集上进行SFT。
具体的数据配比策略
多任务学习:直接混合不同的SFT数据源进行训练。这种方法可以保留特定能力,但可能会对通用能力造成较大影响。
顺序训练:按顺序依次在各能力项数据集上微调。这种方法可以保留通用能力,但可能会导致特定能力的灾难性遗忘。
混合顺序训练:先在特定能力数据集上进行多任务学习,然后在通用能力数据集上进行SFT。这种方法可以较好地平衡特定能力和通用能力。
双阶段混合微调(DMT):在第一阶段在特定能力数据集上进行多任务学习;在第二阶段使用混合数据源进行SFT,其中包括通用数据和一定比例的特定能力数据(如k = 1/256)。这种方法在特定能力方面(如数学、代码)有显著改善,同时对通用能力也有一定程度的优化。
2.1双阶段混合微调(DMT)
第一阶段:特定能力数据微调
数据选择:在第一阶段,选择特定领域的数据集进行微调,这些数据集通常与目标任务直接相关。例如,如果目标是提升模型的数学推理和代码生成能力,可以选择数学推理数据集(如GSM8K RFT)和代码生成数据集(如Code Alpaca)。
数据配比:在第一阶段,通常将这些特定领域的数据集进行混合微调。例如,可以将数学推理数据和代码生成数据按1:1的比例混合,以确保模型能够同时学习到两种特定能力。
第二阶段:混合数据微调
数据组合:在第二阶段,将通用能力数据(如ShareGPT)与第一阶段的特定能力数据进行混合。通用能力数据通常用于提升模型的通用对话能力和人类对齐能力。
数据配比:第二阶段的数据配比是DMT策略的核心。通常会使用一定比例的特定能力数据与通用能力数据混合。例如,可以将特定能力数据(数学和代码)与通用能力数据按1/256的比例混合。这种比例可以根据模型的具体需求进行调整,以在特定能力和通用能力之间实现平衡。
动态调整:在实际应用中,可以根据模型在特定任务上的表现动态调整特定能力数据的比例。例如,如果发现模型在数学推理任务上的表现下降,可以适当增加数学推理数据的比例。
2.2数据配比结果
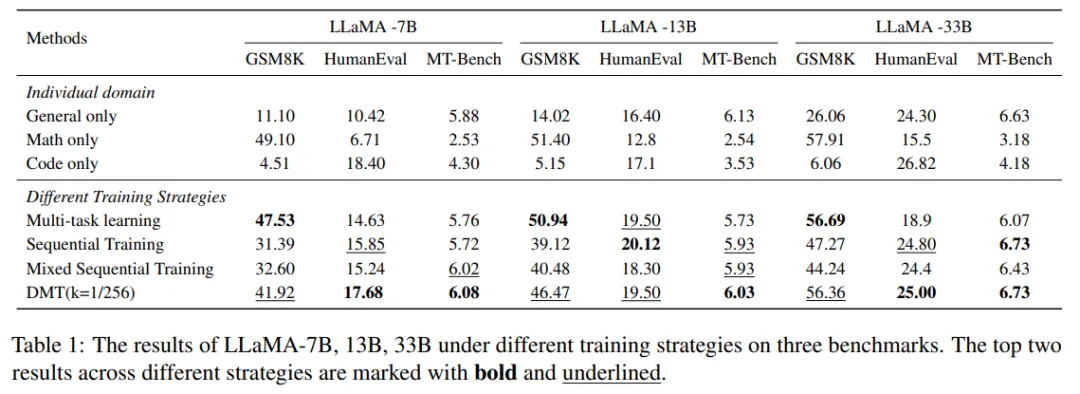
多任务学习在这些策略中保留了专业能力,但同时也是对通用能力伤害最大的策略。
顺序训练和混合顺序训练保留了通用能力,但失去了太多的领域能力。因为在最后的微调阶段,混合顺序训练策略不受领域数据的影响,从而有效地保留了其泛化能力。
DMT策略在特定能力(如数学推理和代码生成)方面有显著提升,同时对通用能力也有一定程度的优化。DMT策略通过在第二阶段加入特定能力数据,有效缓解了模型对特定能力的灾难性遗忘问题。这种策略在不同模型参数量(如7B、13B、33B)下均表现出良好的效果。
2.3数据配比总结
低资源设置:在数据量有限的情况下,混合不同来源的数据可以相互促进,提高模型性能。例如,在通用能力数据中加入少量的特定能力数据,可以提升模型在特定任务上的表现。
高资源设置:当数据量充足时,来自其他领域的数据可能被视为噪声,影响模型在特定任务上的表现。因此,在高资源环境下,需要谨慎调整特定能力数据的比例,以避免性能冲突。




还没有评论,来说两句吧...