

让大模型能快速、准确、高效地吸收新知识!
被EMNLP 2024收录的一项新研究,提出了一种检索增强的连续提示学习新方法,可以提高知识终身学习的编辑和推理效率。
模型编辑旨在纠正大语言模型中过时或错误的知识,同时不需要昂贵的代价进行再训练。终身模型编辑是满足LLM持续编辑要求的最具挑战性的任务。
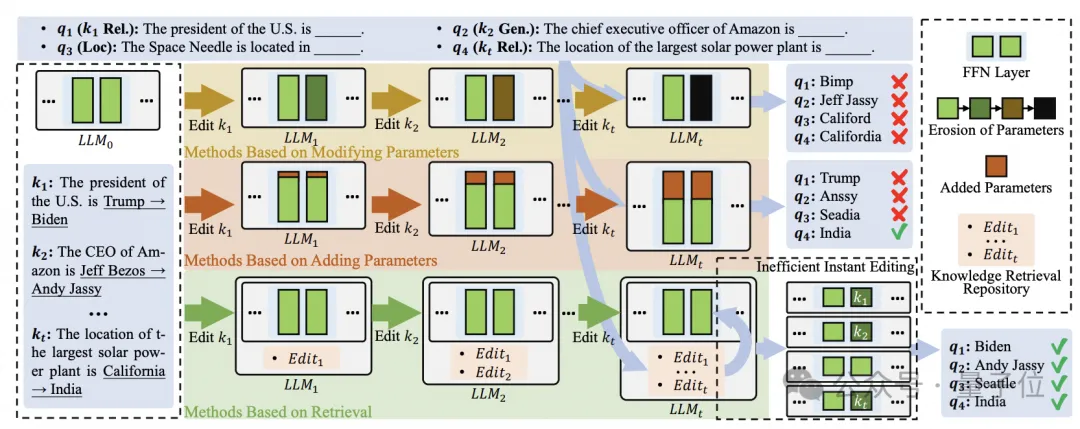
之前的工作主要集中在单次或批量编辑上,由于灾难性的知识遗忘和模型性能的下降,这些方法在终身编辑场景中表现不佳。尽管基于检索的方法缓解了这些问题,但它们受到将检索到的知识集成到模型中的缓慢而繁琐的过程的阻碍。
而名为RECIPE的最新方法,它首先将知识描述转换为简短且信息丰富的连续提示的token表示,作为LLM输入查询嵌入的前缀,有效地细化基于知识的生成过程。
它还集成了知识哨兵机制,作为计算动态阈值的媒介,确定检索库是否包含相关知识。
检索器和提示编码器经过联合训练,以实现知识编辑属性,即可靠性、通用性和局部性。
在多个权威基座模型和编辑数据集上进行终身编辑对比实验,结果证明了RECIPE性能的优越性。
这项研究由阿里安全内容安全团队与华东师范大学计算机科学与技术学院、阿里云计算平台针对大语言模型知识编辑的联合推出。

研究背景
即使有非常强大的语言理解能力,像ChatGPT这样的大型语言模型(LLM)也并非没有挑战,特别是在保持事实准确性和逻辑一致性方面。
一个重要的问题是,是否能够有效地更新这些LLM以纠正不准确之处,而无需进行全面的继续预训练或持续训练过程,这些操作带来的机器资源开销大且耗时。
编辑LLM模型提供了一种有前景的解决方案,允许在特定感兴趣的模型中进行修改,同时在各任务中保持模型整体性能。
之前各种知识编辑的模型方法和架构包括类似于:修改模型内部参数、增加额外参数和基于检索方法都会有冗长的编辑前缀影响推理效率。对模型本身进行微调可能会导致过拟合,从而影响其原始性能。
为了解决上述问题,研究人员期望探索更有效的检索和即时编辑方式,以及对模型进行更小的干预,以避免在编辑数据集上过度拟合。
模型方法
知识编辑相关背景
在本文中,研究团队首先形式化模型编辑任务在终身学习场景中的任务定义形式,然后介绍模型编辑中的重要评估属性。
任务定义

任务属性

RECIPE终身编辑方法
总体模型框架如下:

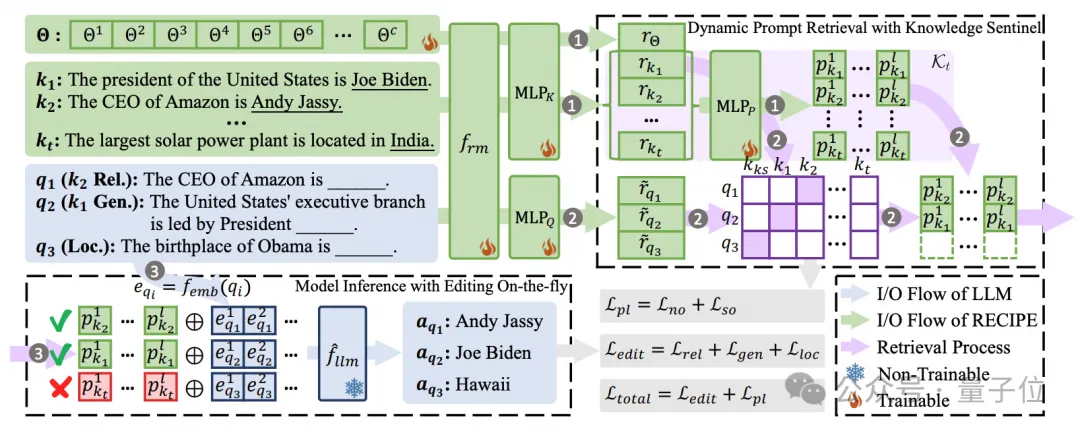
构造和更新知识检索仓库
在第t个时间步,给定一个新的知识描述kt,则新知识表示通过编码器frm中的MLP层可以获得:
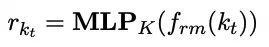
其中frm编码器将输出token表示的最大、最小、平均的池化级联到一个向量空间中作为新知识表示。然后连续prompt表示pkt可以被其他初始化的MLP层实现:
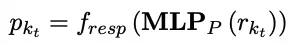
最终知识检索仓库被从Kt-1更新到Kt
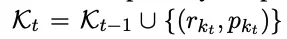
基于知识哨兵的动态prompt检索

动态编辑模型的推理
研究人员认为LLM将被编辑为:
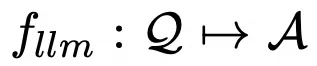
给定输入查询q和连续检索prompt p(kr) = KS(q), 推理过程可以被重新形式化为:
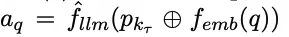
其中⊕表示检索到的连续提示矩阵和q的单词嵌入矩阵的连接。
本文方法的可行性得到了P-Tuning等先前工作的支持,该工作证明了训练连续提示嵌入可以提高LLM在下游任务上的性能有效性。
在RECIPE中,研究人员将每个知识陈述的编辑视为一项小任务,没有为每个小任务微调特定的提示编码器,而是通过训练生成连续提示的RECIPE模块来实现这些小任务的目标,确保LLM遵守相应的知识。
模型训练
制定损失是为了确保对生成的连续提示进行编辑,并有效检索LLM的查询相关知识。给定包含b个编辑样例的训练数据:
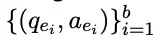
对应的泛化性和局部性数据为:
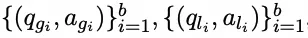
因此损失形式化如下:
编辑损失训练:编辑损失旨在确保生成的连续提示引导LLM遵循可靠性、通用性和局部性的特性。基于输入的编辑数据,对应于这三个属性的样本损失定义如下:
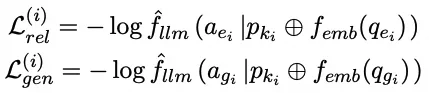
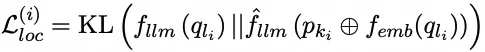
模型编辑的批量损失函数推导如下:
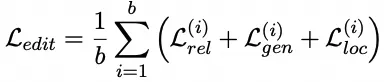
prompt损失训练:prompt学习的训练损失是基于对比学习,并与可靠性、通用性和局部性的特性相一致。对于一批样本,学习连续提示的损失函数形式化如下:
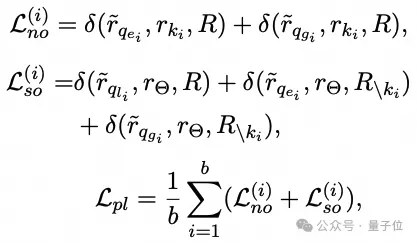
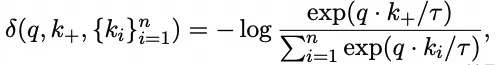

实验结果
实验设置
测试编辑能力的数据集:研究人员使用了三个公共模型编辑数据集,包括ZSRE、CounterFact(CF)和Ripple Effect(RIPE)作为实验数据集。
ZSRE是通过BART问答和手动过滤生成的,包括162555个训练和19009个测试样本。每个样本包括一个编辑样本及其改写和不相关的对应样本,与可靠性、通用性和局部性编辑属性相匹配。
CF数据集的特点是编辑虚假事实,包括10000个训练样本和10000个测试样本。这些虚假事实更有可能与LLM中的原始知识相冲突,使编辑过程更具挑战性,从而对编辑执行的能力进行强有力的评估。
RIPE将通用性和局部性属性分为细粒度类型,包括3000个训练样本和1388个测试样本。每个样本的一般性包括逻辑泛化、组合I、组合II和主题混叠,而局部数据则包括遗忘和关系特异性。
测试通用能力的数据集:为了评估编辑对LLM总体性能的损害,研究人员选择了四个流行的基准来评估LLM的总体通用能力。分别是用于评估常识知识的CSQA、用于推理能力的ANLI、用于衡量考试能力的MMLU和用于理解技能的SQuAD-2。PromptBench被用作本实验的评估框架。
模型baseline:除了微调(FT)作为基本基线外,研究人员还将RECIPE方法与各种强大的编辑基线进行了比较。
MEND训练MLP,以转换要编辑的模型相对于编辑样本的梯度的低秩分解。ROME首先使用因果中介分析来定位对编辑样本影响最大的层。MEMIT基于ROME将编辑范围扩展到多层,从而提高了编辑性能并支持批量编辑。T-Patcher(TP)在要编辑的模型最后一层的FFN中附着并训练额外的神经元。MALMEN将参数偏移聚合表述为最小二乘问题,随后使用正态方程更新LM参数。WILKE根据编辑知识在不同层之间的模式匹配程度来选择编辑层。
研究人员还利用基于检索的编辑方法来进一步验证其有效性。
GRACE提出了用于连续编辑的检索适配器,它维护一个类似字典的结构,为需要修改的潜在表示构建新的映射。RASE利用事实信息来增强编辑泛化,并通过从事实补丁存储器中检索相关事实来指导编辑识别。
在基线设置中,研究人员使用ROME模型作为RASE的特定基本编辑器来执行名为R-ROME的编辑任务。LTE激发了LLM遵循知识编辑指令的能力,从而使他们能够有效地利用更新的知识来回答查询。
编辑能力的实验效果
下面两个表格分别表示在LLAMA2和GPT-J模型上的编辑效果对比。
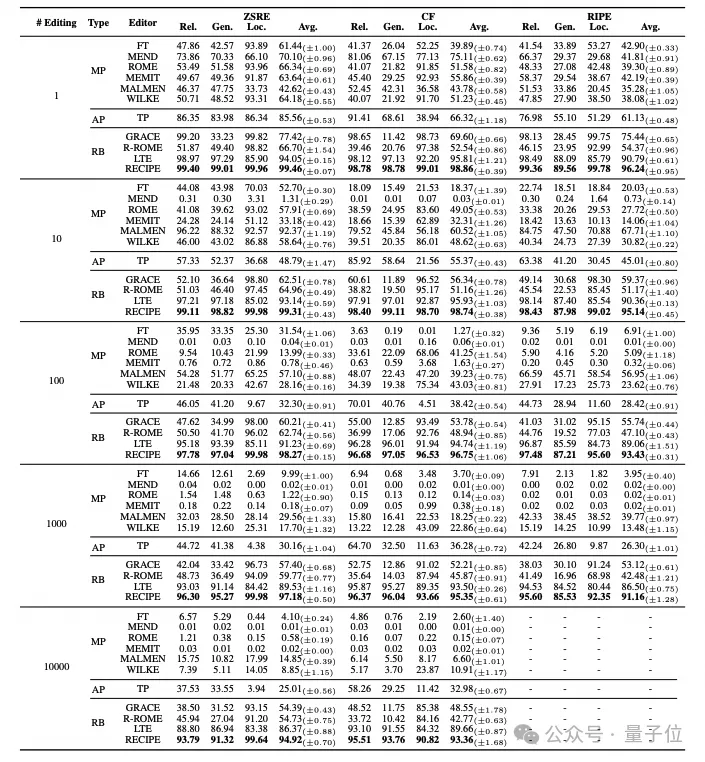
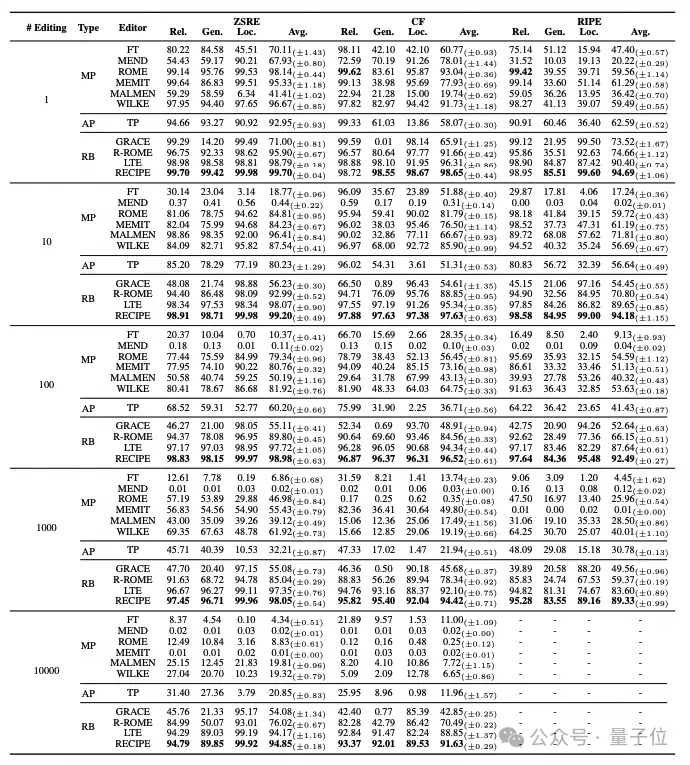
从单次编辑的角度来看,本文方法在大多数测试场景中表现出最佳性能。
在终身编辑场景中,研究人员有以下观察结果:
修改LLM参数的方法在单次编辑中显示出出色的编辑性能。然而,随着编辑次数的增加,它们的编辑性能显著下降。这一趋势与已有工作强调的毒性积累问题相一致;
引入额外参数的方法在终身编辑过程中保持了一定程度的可靠性和通用性。然而,在ZSRE中观察到的局部性明显恶化证明,额外参数的累积添加会损害原始推理过程;
基于检索的方法对越来越多的编辑表现出鲁棒性。其中,本文方法取得了最好的结果,肯定了检索的优势,也验证了策略的有效性。
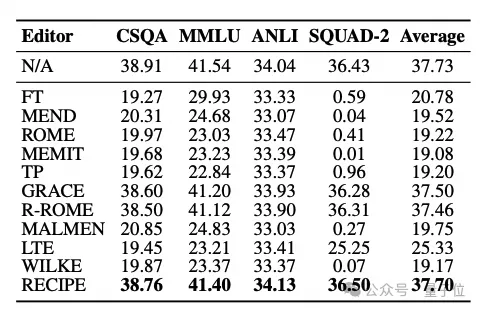
通用能力的实验效果
虽然这三个编辑指标有效地展示了编辑性能,但研究人员进一步研究了这些编辑器在多大程度上影响了模型的通用能力。
通过实验可以看出,非基于检索的方法会导致通用能力的显著降低。这可以归因于编辑的外部干预造成的模式不匹配的累积。在基于检索的方法中,LTE也表现出性能下降。
相比之下,RECIPE不涉及对LLM参数的直接干预,而是依赖于连接一个简短的提示来指导LLM对知识的遵守。它展示了对通用性能的最佳保护,表明它对模型造成的伤害最小。
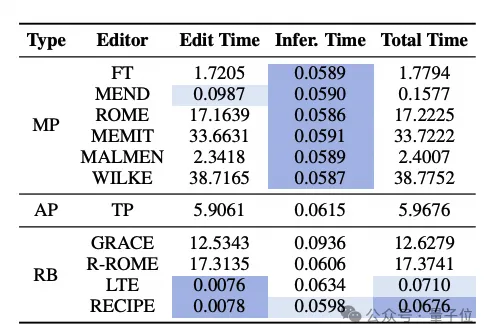
模型编辑效率对比
通过下方表格可以看出,在利用MEND、MALMEN、LTE和RECIPE等编辑特定训练的方法中,与在编辑过程中需要多次迭代反向传播的技术相比,编辑时间显著减少。
对于推理速度,修改模型参数的方法保持一致的速度,因为它们不会改变原始的推理pipeline。T-Patcher由于神经元的积累而减慢了推理速度。
在基于检索的方法中,GRACE由于其独特的字典配对机制,降低了模型推理的并行性。R-ROME和LTE需要动态计算编辑矩阵并分别连接长编辑指令。
相比之下,RECIPE通过连接连续的短提示进行编辑,有效地保留了LLM的原始推理速度。最短的总时间也突显了RECIPE的效率优势。
消融实验效果对比
研究人员使用LLAMA-2对ZSRE、CF和RIPE进行消融研究。在没有CPT的情况下,研究人员求助于使用知识语句的单词嵌入作为从知识库中检索的提示。排除KS涉及应用传统的对比学习损失,使可靠性和通用性样本表示更接近编辑知识,同时与局部样本的表示保持距离。
在训练完成后,研究人员采用绝对相似性阈值决策策略来过滤无关知识。尽管局部性很高,但省略CPT会严重损害RECIPE的可靠性和通用性。
可以观察到,结果与完全不使用编辑器获得的结果几乎相同。
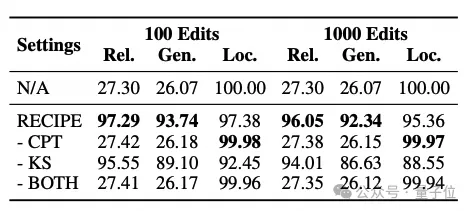
这强调了仅使用原始连接的知识前缀无法使LLM符合编辑指令。相反,CPT有助于LLM遵守指定的编辑。此外,丢弃KS会导致编辑效率下降,特别是影响普遍性和局部性。原因是绝对相似性阈值无法充分解决不同查询所需的不同阈值。




还没有评论,来说两句吧...