

常规的推荐系统范式已经逐渐走入瓶颈,原因是在当前固定化的问题描述下模型和系统几乎已经发展到极限。当前的主要范式在模型上为召回+排序+重排,系统上为样本挖掘+特征工程+线上打分预估能力建设。一线大厂在上述领域已经把空间挖掘殆尽。同时可以看到,我们的用户对当前推荐系统的满意度仍然未达到理想状态。推荐系统是一个非常面向于用户满意度的平台系统,而用户满意是一个永远存在不同理解的问题,一千个用户眼里有一千种对好的推荐系统的理解。
构建更好的推荐系统需要我们重新定义“什么是好的推荐系统”。这并不是学术界的“强行挖坑”或者“继续填坑”,而是不同层面上都在呼唤新的定义。事实上,新的推荐系统已经零散地在学术界和工业界展现星星之火。
为何本文主题提出 2026 呢?是因为当前无论在业务上还是技术上都有一些亟待解决的问题,希望在未来 3 年能找到好的解法。
一、留存提升
对于所有 APP 来说,留存是第一生命力,APP 留下多少用户,DAU 多高,决定着公司的估值和市值。业界和留存相关的课题主要有以下三种:
通过相关性分析、因果推断找出影响留存的因素。比如爱奇艺、腾讯视频和优酷等平台。对于长视频平台,影响留存的最大因子是热播剧,在腾讯视频中我们会发现假如有热播剧上线,那么当季的留存和 DAU 会提升很多。但如果一个热播剧下线,DAU 就会降低很多,这就要求平台不断提供爆款的热播剧,热播剧因素跟平台的留存非常相关。
留存拆分为多个子目标建模,再综合排分。
建模多天的收益来逼近留存的概念。如果是次日留存,对用户的正反馈,不要建模为一次点击或者观看 30 秒,而要建模为 48 小时的总体消费指标,这样更能够逼近留存。
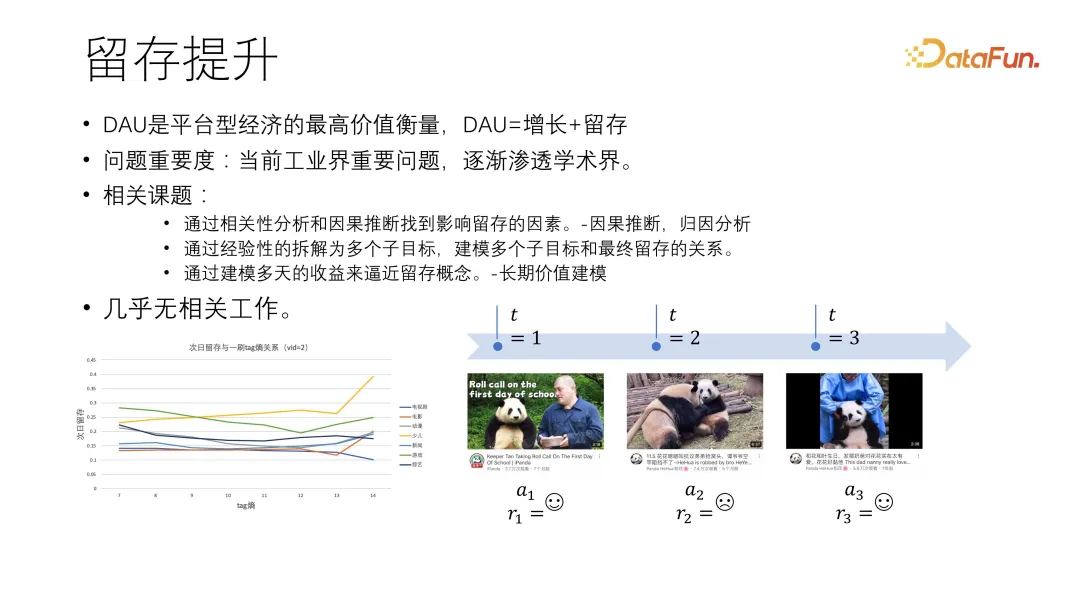
下图中展示了两个项目:
一是留存与一刷 tag 熵的关系,例如今天有 n 个用户来到平台,明天 m 个用户留下,留存就是 m 除以 n,这是次日留存的概念。tag 熵是指内容多样性,我们发现如果用户看的内容比较多样,在当时场景下留存率是比较高的。
二是基于强化学习的分析,我们希望逼近 30 分钟建模,即用户在短视频平台看 30 分钟的总价值。
二、用户增长
这里使用的是狭义的用户增长定义,如何把一个新的不活跃的消费者变成平台的活跃用户。
平台仅依靠巨大的人口红利获得持续发展的时代已经过去,很多平台进入存量竞争。在新平台新 APP 上线的阶段,更是用户增长能力决定生死的关键阶段。
相关的课题:
用户分层优化,预估 high value action。举个例子,比如有些用户状态能够很好地区分用户的等级,我们会利用这些关键的动作把用户分层[2]。
二是营销手段建模 uplift 和推荐算法的分人群。营销的手段主要就是物质奖励,推荐算法就是更精准的匹配,针对不同层次的用户,有不同推荐算法的目标。
用户的知识融合,一个中小型 APP 其实非常缺乏数据,无法建模用户偏好,我们希望能够从外部融合一些数据,来弥补数据不足[3][4]。

三、内容生态
内容生态的定义是平台供给侧繁荣程度,它是平台的 B 面,好的内容生态应该能充分反映用户的需求,而且自身应该有比较好的生长发育衰退机制,就像一片森林或者是一个社会的经济系统,这也是其称为生态的一个原因。
内容生态非常重要,是平台真正的护城河,很多时候平台经济的护城河其实不在于C 端,更多在于 B 端。例如淘宝的服饰类、拼多多的机制供应链竞争、抖音很大程度上靠优质内容供给来搞定前期用户。
相关的课题:
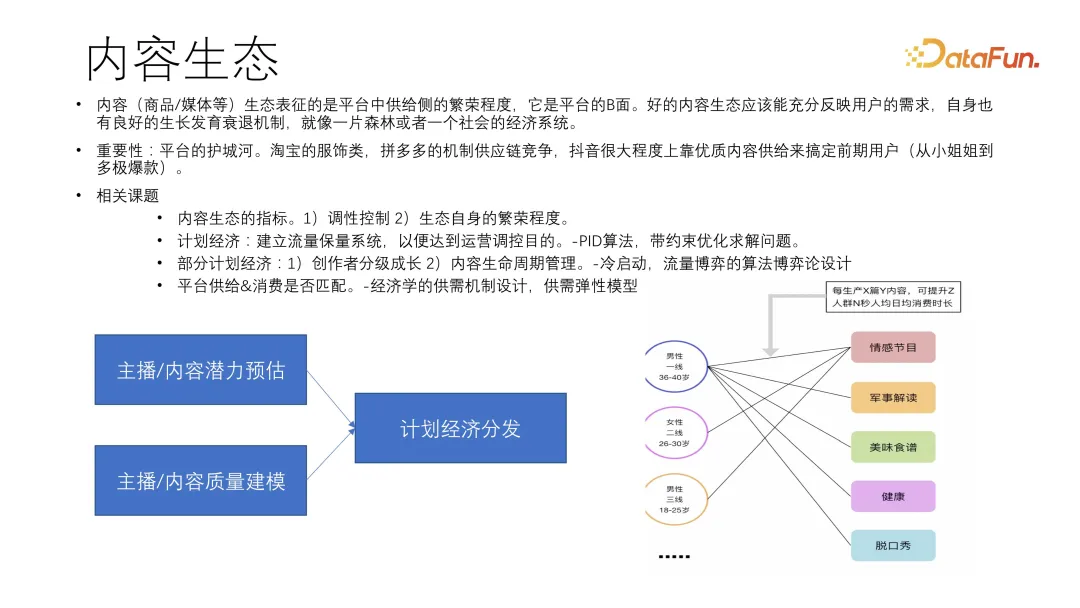
内容生态的指标:建立调性控制生态自身的繁荣程度
计划经济:建立保量系统,达到运营调控的目标
部分的计划经济:建立创作者的分级成长、内容生命周期管理,利用 PID 算法、带约束优化以及流量博弈等。
平台供给 & 消费是否匹配:从用户出发设计供需机制。理解用户平台内容侧的需求是什么。预估主播内容的潜力+主播内容质量的建模,进行有计划地分发。通过预估增长程度指导内容生产,我们可以知道生产 X 个某种内容到底能让用户侧产生怎样的反应。
四、多目标帕累托最优
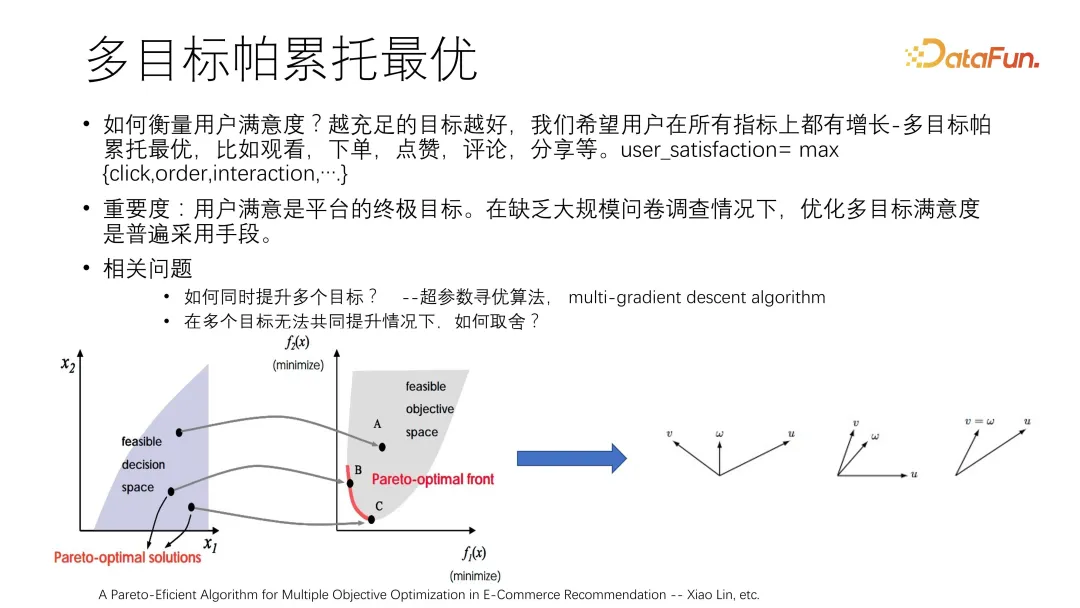
要实现更加精细地优化用户满意度,目标越充足越好,我们希望用户在所有指标上都有增长,即多目标帕累托最优,比如观看、下单、点赞、评论、分享等。user_satisfactinotallow= max {click,order,interaction,....}
这个问题很重要,因为用户满意也是平台的终极目标之一。只有用户满意,平台才能够存活。在缺乏大规模问卷调查的情况下,目前很多公司采用的就是优化多目标满意,一般是点击率、转化率、观看时长等指标。
帕累托最优[5]可能难以达到,因为有些目标是相冲的,这时的帕累托最优是在相冲的情况下最优的一种情况。例如下图中红色的线,被认为是帕累托最优的前沿,这条线代表已经到达临界值。临界值指的是在不损害某一个指标的情况下,是无法提升其他指标的,这被称为帕累托前沿。我们的目标就是找到帕累托最优前沿,在不同指标间进行 trade off。
相关课题包括:
提升多个目标-超参数寻优算法。
在多目标无法共同提升情况下,如何取舍。
五、时间-长期价值预估
接下来介绍建立时间维度的长期价值预估。当前的推荐系统比较专注于瞬时价值,缺乏对更长期价值的预估,而长期价值更加接近 DAU 目标。
短期价值优化容易出现很多问题,比如标题党、软色情等,导致平台失败。
相关课题包括:
优化 session 的总价值,将 session 定义为一个用户一次不间断的跟 APP 的交互。
优化多个场景之间的总价值,比如淘宝现在是双列流,用户在双列流进行浏览,但又可能点进去某一个具体详情继续浏览。双列流可能会具有多样性,单列流则更偏向于单类目。双列流跟单列流之间也会存在此消彼长的效应,需要进行调和。
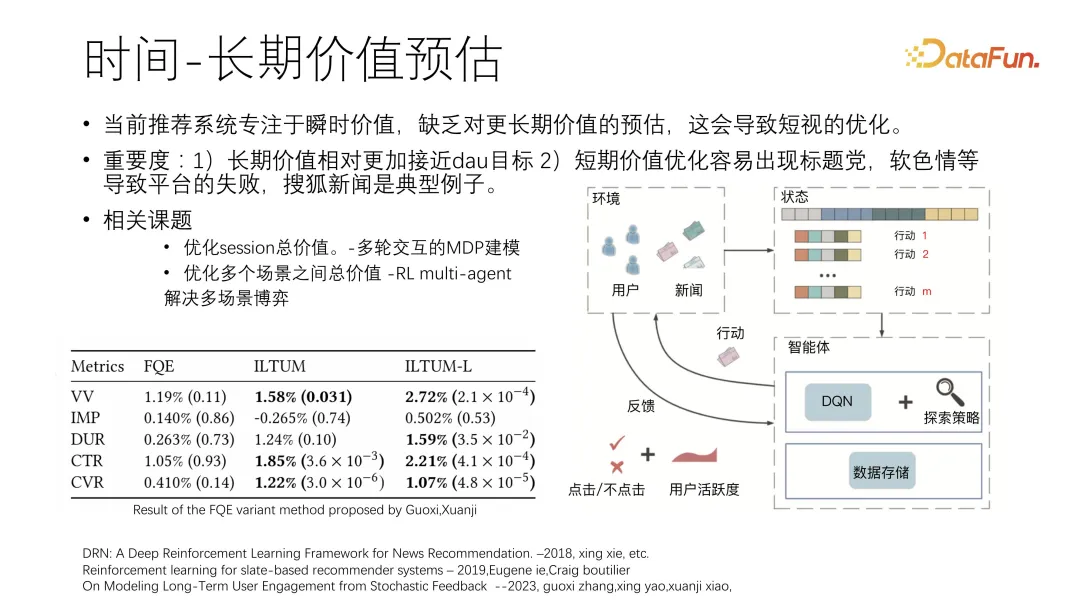
session 总价值可以用马尔可夫过程建模成一个多轮交互。这里引用微软谢幸老师在微软新闻上的一个工作[6],他把推荐系统称为一个智能体,把用户称为环境,智能体推荐给用户一些新闻,根据用户是否点击作为反馈来建模。
另一个是腾讯视频的一个工作[1],通过优化 session 价值,使 VV、GTR 等提高了两个点。
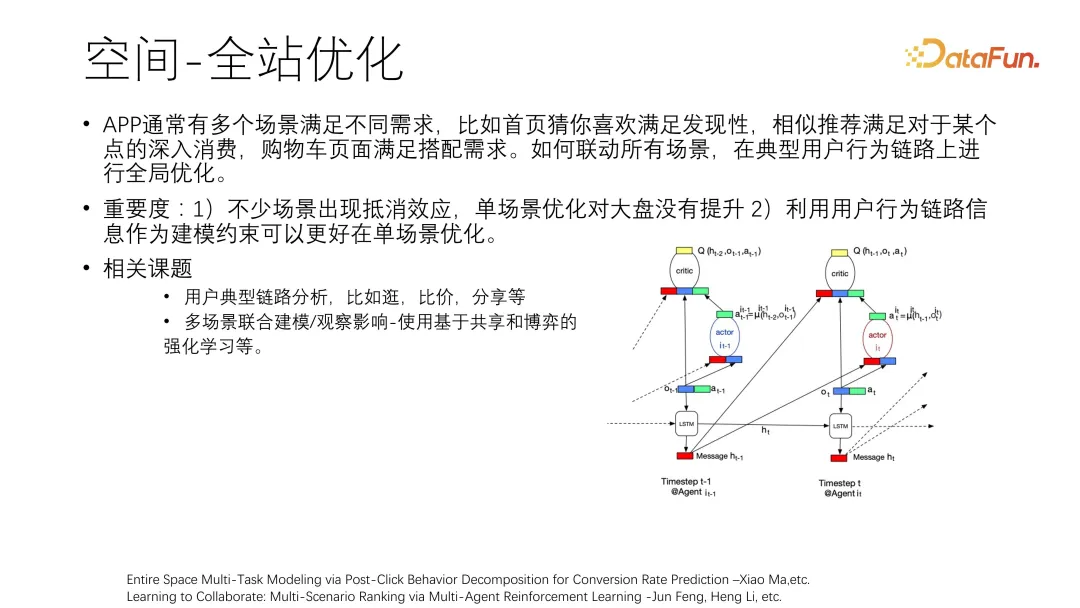
六、空间-全站优化
APP 通常有多个场景满足不同需求,比如首页猜你喜欢满足发现性、相似推荐满足对于某个点的深入消费、购物车页面满足搭配需求。需要联动所有场景,在典型用户行为链路上进行全局优化。
单场景优化会出现抵消效应,所以要对用户的典型链路进行分析。利用用户行为链路信息作为建模约束可以更好地实现单场景优化。
相关课题包括:
用户典型链路分析,比如逛、比价、分享等。
多场景联合建模/观察影响-使用基于共享和博弈的强化学习等。
七、交互式推荐系统(IRS)
个性化问答助手逐渐商用,并在未来的人类生活中被寄予厚望。基于人类直接语言交互的推荐系统,能够更加满足用户意图,并且更加便捷。
目前有两种 IRS 系统,隐式对话和显式对话。前者已经在大厂初步展示了价值,后者随着 chatGPT 热度再起,但是当前仍不成熟。
相关课题包括:
显示的对话式推荐,GPT 加推荐算法以及意图识别等。
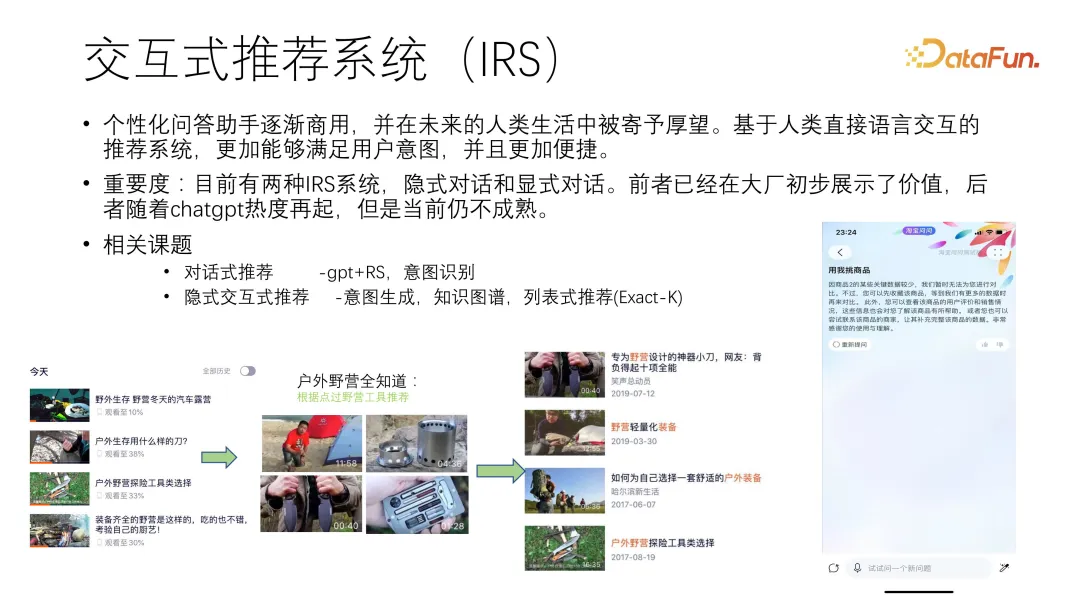
隐式交互式推荐-意图生成,知识图谱,列表式推荐(Exact-K) ,下图所示是当时提出的腾讯视频的心向标项目。
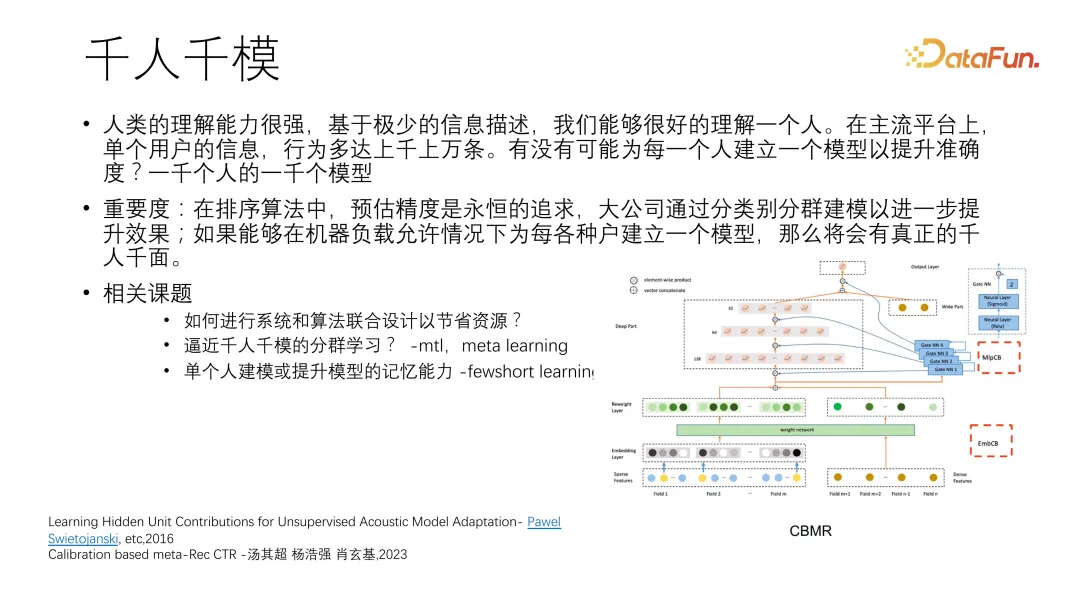
八、千人千模
人类的理解能力很强,基于极少的信息描述,就能够很好地理解一个人。在主流平台上,单个用户的信息、行为多达上千上万条。是否有可能为每一个人建立一个模型以提升准确度呢?虽然我们现在的推荐算法就是千人千面,但其实 pattern 是被大部分主流人群主导的,对于长尾用户表现得并不理想。
在排序算法中,预估精度是永恒的追求,大公司通过分类别分群建模以进一步提升效果,如果能够在机器负载允许情况下为每一个用户建立一个模型,那么将会实现真正的千人千面。
目前相关课题包括:
如何进行系统和算法的联合设计节省资源。
如何逼近千人千模分群学习,工业界其实很难给每个用户建立模型,比如淘宝有 10 亿的用户,如果每个用户建一个模型,那么机器负载消耗是巨大的。但我们可以采用一些逼近方法,比如多任务学习或 Meta learning。
单个人建模或提升模型的记忆能力。主流排序算法模型+千人千模。如下图所示,Gate 特征与 CTR 模型融合来校准学习[8]。
九、当作决策问题的推荐算法
工业界推荐的本质不是一个常规的回归/分类,而是一个决策问题。平台通过感知用户并决策给到用户在不同时刻想要的东西,从而希望用户能够喜欢这个平台最终停留下去。同时用户反馈(比如点不点)也是一个决策问题,里面含有不确定性。从决策角度看,推荐不同于 CV/NLP 等问题,更加类似于 AI。当前的解法基本上把推荐当作分类问题,这是存在缺陷的。
为什么推荐是决策且不确定性问题?
平台给用户推荐视频,用户的反馈、用户的状态都具有一定不确定性。所以我们将其视为决策问题。
相关课题:
针对平台调性的留存建模。运营挑选的热门物品根本不匹配用户兴趣,但是用户却喜欢上了平台,比如拼多多首页。
把推荐当作多轮交互的 MDP 过程。
用户决策仅仅是兴趣匹配吗?其实决策不仅仅是兴趣匹配,还包括多样性、精细度、时效性、用户疲劳度等,这些都对用户决策起到了作用。

十、OneRec-推荐融合大模型[3]
大模型和推荐的共同点是参数量都很大,其实在大模型问世之前,淘宝等主流平台的推荐模型也都达到千亿参数规模。
大模型的优势在于深度语义理解和广度世界知识,它能够根据上下文做出比较精准的推断。具备广度世界知识是因为大模型学习了很多不同领域的信息。
然而大模型也有其局限性,推荐模型是高度专有化的,大模型在单独某个任务的精度不容易超越传统模型。
大模型会不会取代推荐模型?比如 GPT 是否会取代推荐算法?
一是取决于人机交互的进化,从应用的角度来看,近二三十年大的互联网变革都是从交互方式发生的。从 PC 时代、移动互联网时代,再到当前的 GPT 时代,交互方式是第一生产力。如果 GPT 控制终端入口,那么推荐将被迫作为 GPT 的子模块,所以整体取决于人类更喜欢的前端交互形态是什么样的。
二是 GPT 是否会成为推荐的入口。当大模型内置于手机等智能终端后,消费者的使用习惯如果一直倾向于通过提问来获取物料,那么推荐就有可能成为 GPT 的一个后端。但如果消费者的习惯没有改,还是喜欢刷淘宝、抖音,那么 GPT 就不会取代传统推荐系统。
三是推荐算法不会消失,因为推荐算法的准确度非常高,最差的情况下它也会作为一种 backend 内嵌于大模型当中。
后续的演进方向:
交互性。chatGPT 类催生新的业务场景,比如基于问答的推荐场景,类似于淘宝问答中的答案生成和推荐。
深度语义理解,大模型对内容理解能力的提升。当前推荐建模依赖大量离散特征以及统计后验特征,如果未来能通过大模型的内容理解能力,直接匹配用户理解,这样端到端的新范式会重塑推荐系统的发展线路。
广度知识,改善长尾。
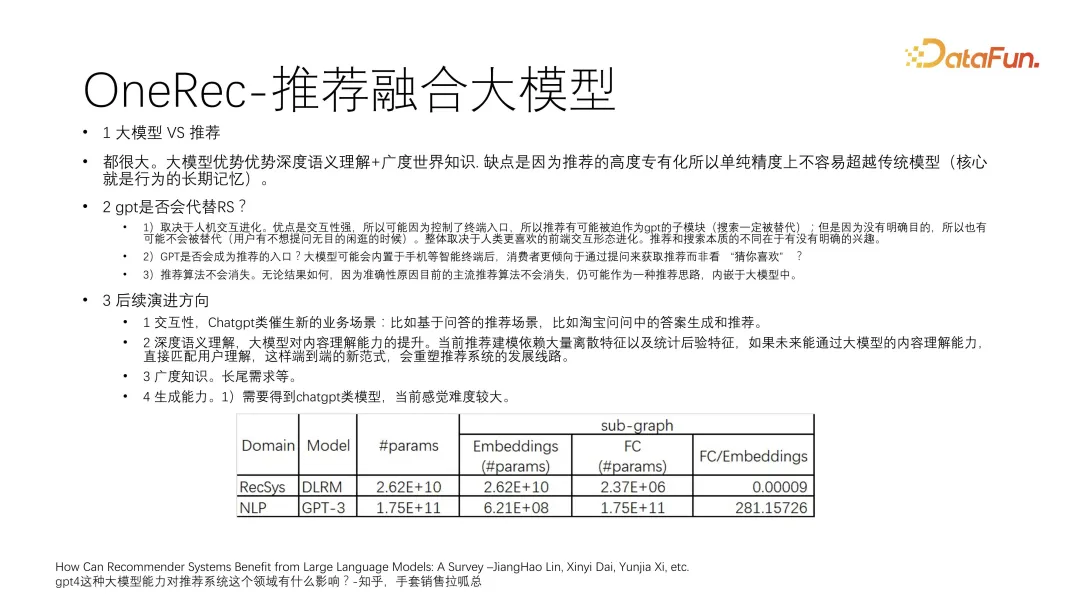
生成能力。需要得到 chatGPT 类模型,当前难度较大。下图中的 case 就是对比一些大模型和原来 Facebook 的 DLIM 模型,可以看到大模型的参数集中在 FC 层,而推荐集中在 embedding 层,FC 层模型有更好的语义理解,集中在 embedding 层模型就有更好的记忆。
基于以上的判断,我们并没有把大模型和推荐系统直接结合起来,而是先开发了OneRec 项目,试图融入各种各样的更广阔的业务知识,从而拿到业务效果。在我们可以灵活有效地进行多信号信息融合基础上,探索统一的大模型之路。
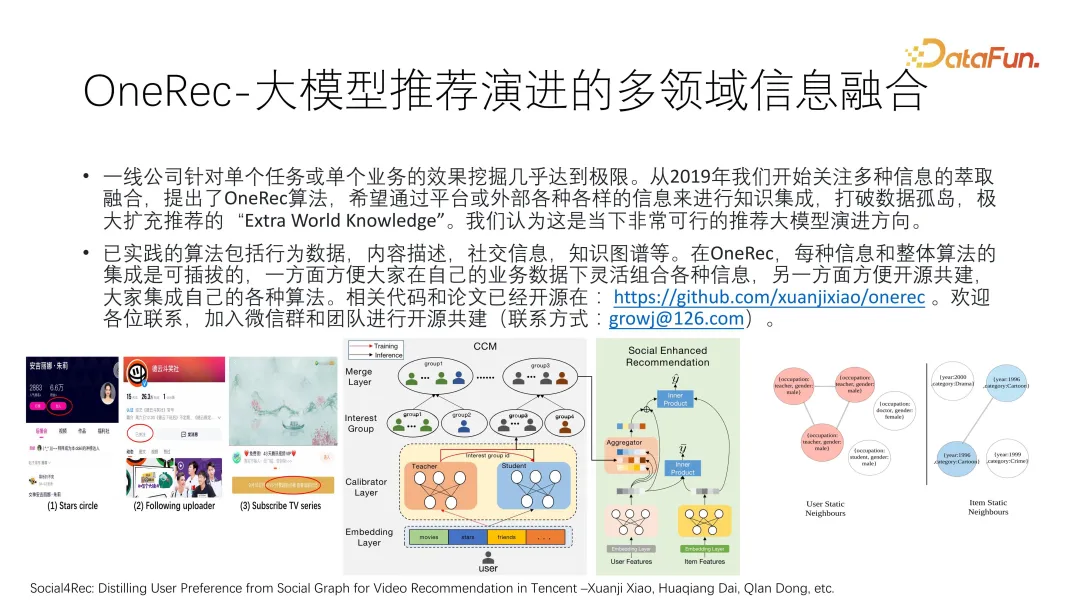
从 2019 年我们开始关注多种信息的萃取融合,提出了 OneRec 算法[3],希望通过平台或外部各种各样的信息来进行知识集成,打破数据孤岛,极大扩充推荐的“Extra World Knowledge”。我们认为这是当下非常可行的推荐大模型演进方向。
已实践的算法包括行为数据、内容描述、社交信息、知识图谱等。在 OneRec,每种信息和整体算法的集成是可插拔的,一方面方便大家在自己的业务数据下灵活组合各种信息,另一方面方便开源共建,大家集成自己的各种算法。相关代码和论文已经开源,项目地址:https://github.com/xuanjixiao/onerec。
十一、参考文献
[1] On Modeling Long-Term User Engagement from Stochastic FeedbackG Zhang, X Yao, X Xiaoin the proceedings of The Web Conference 2023, Oral Presentation (4 in 20+
[2] STAN: Stage-Adaptive Network for Multi-Task Recommendation by Learning User Lifecycle-Based Representation W Li, W Zheng, X Xiao, S Wangin the Proceedings of the 17th ACM Conference on recommender systems
[3] OneRec:一个专注在多源信息融合的推荐算法库 ,https://github.com/xuanjixiao/onerec, 肖玄基,和子钰,戴华强等
[4]Neighbor Based Enhancement for the Long-Tail Ranking Problem in Video Rank ModelsZ He, X Xiao, Y Zhou in the proceedings of ACM SIGKDD CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA
[5] A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation X Lin, H Chen, C Pei, F Sun, X Xiao, H Sun, Y Zhang, W Ou, P Jiang in the Proceedings of the 13th ACM Conference on recommender systems, 20-28。
[6]A Deep Reinforcement Learning Framework for News Recommendation Zheng, Guanjie and Zhang,etc.The Web Conference 2018, Lyon, France, Apr. 2018
[7]Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning -Jun Feng, Heng Li, etc.
[8]CTR 2023 最新进展:Calibration based MetaRec CTR, 汤其超、杨浩强、肖玄基等,2023
十二、Q&A
Q1:在用户增长部分提到 42 秒,这里分析很细致。请问这个 42 秒的来源是什么?
A1:对于 high value action 可以选 41 或 40 秒。42 秒是经过统计分析和模型预估最终得出的结果。
大于 42 秒的用户跟小于 42 秒的用户的长期价值差别非常大。比如大于 40 秒的用户大概平均每年能买 3 单,如果小于 40 秒的用户平均能买 1 单,那么 DIFF 就是两单。再来看为什么不选 40 秒,大于 40 秒的用户可能平均每年只买两单,小于 42 秒的用户可能每年只买 1 单,他们的 DIFF 是 1 单。我们认为 42 秒更能区分用户,他们的 deep 更大,这就是我们选 42 秒的原因。
Q2:内容生态部分提到计划经济会用到 PID 控制,它的约束和优化目标是什么?
A2:对于 PID 控制算法,举个例子,比如我们现在引入了 1 万个网红,是跟 MCN 机构签约的,假设我是其他平台竞争方,我们从那边挖过来 1 万个网红,那么每天要给他们 1 万个 view,这是我们跟他们协议的一部分。
要达到这 1 万 view 量,就由 PID 算法来保证的。比如可能一小时给他 1 万 view,按照每分钟给予数量相同的 view。
带约束优化则是更进阶的算法,在做计划经济的时候我们经常会对原来的市场经济算法的自然分发造成效果的损失。那么如何调节两个 PID 呢?
我们可以将其转换为一个带约束的优化问题,描述为最大化 C 端的收益,比如说 Max CTR(最大化点击率)。可以添加一个超参数 Pij,Pij 代表对于这个用户这次要不要推荐这个短视频或直播,I 代表这个用户,j 代表直播间。比如在当下要不要推荐这个直播,我们自然流量分发的目标是 CTR,约束就是比如每小时给的量不要大于 12000,也不要少于 8000,这样将其变成一个带约束的固化问题。Max CTR*Pij,subject 这个约束指的是,我们给的量,比如 Pij sum 要大于 8000,小于等于 12000,这样可能是一个更好的描述形态,但这个问题可能是非凸的。
Q3:大模型和推荐系统的主要区别是什么?
A3:推荐的最大优势是在单个问题上,比如 CTR 建模上,推荐系统精度非常高。但大模型做不到高精度。
大模型的优势是有深度的语义理解,还有广度的世界知识。




还没有评论,来说两句吧...