

Gemini是谷歌开发的一个新模型。有了Gemini可以为查询提供图像、音频和文本,获得几乎完美的答案。
我们在本教程中将学习Gemini API以及如何在机器上设置它。我们还将探究各种Python API函数,包括文本生成和图像理解。
Gemini AI模型介绍
Gemini是谷歌研究院和谷歌DeepMind等团队合作开发的新型AI模型。它为多模态而建,理解并处理不同类型的数据,比如文本、代码、音频、图像和视频。
Gemini是谷歌迄今为止开发的最先进、最庞大的AI模型。它非常灵活,可以从数据中心到移动设备的各种系统上高效运行。这意味着它有望彻底改变企业和开发人员构建和扩展AI应用程序的方式。
以下是针对不同用例设计的Gemini模型的三个版本:
Gemini Ultra:最庞大最先进的AI,能够执行复杂的任务。
Gemini Pro:一种良好性能和可扩展性兼备的模型。
Gemini Nano:最适合移动设备。
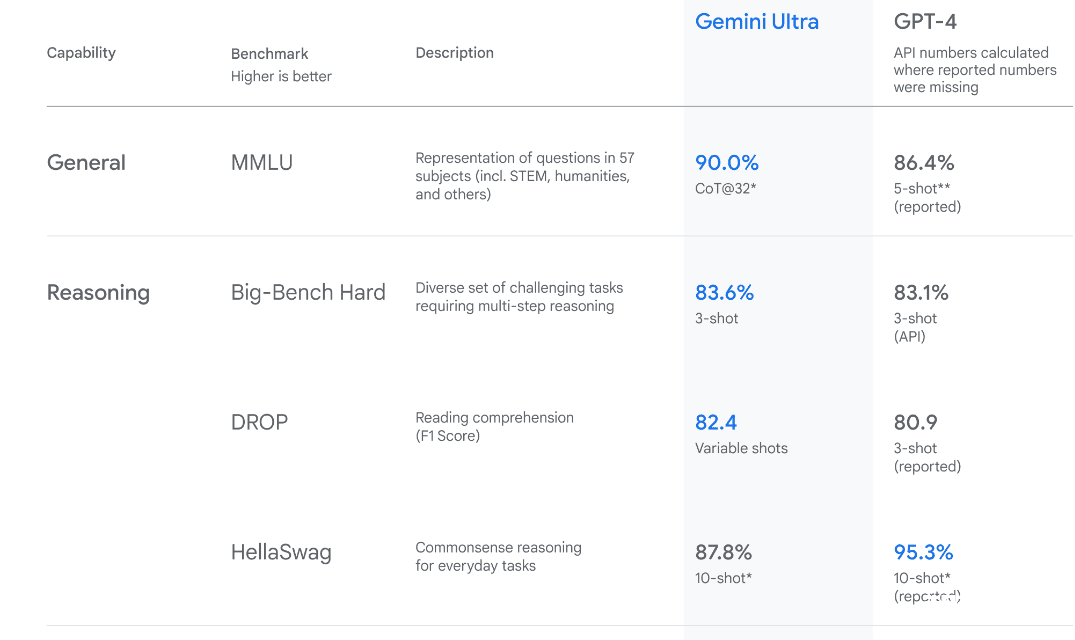
Gemini Ultra具有最先进的性能,在几个指标上超过了GPT-4的性能。它是第一个在大规模多任务语言理解基准测试中超越人类专家的模型,该基准测试57个不同学科的世界知识和解决问题的能力。这展示了其先进的理解和解决问题的能力。
设置
要使用API,我们必须先获得一个API密钥,可以从这里获取:https://ai.google.dev/tutorials/setup。
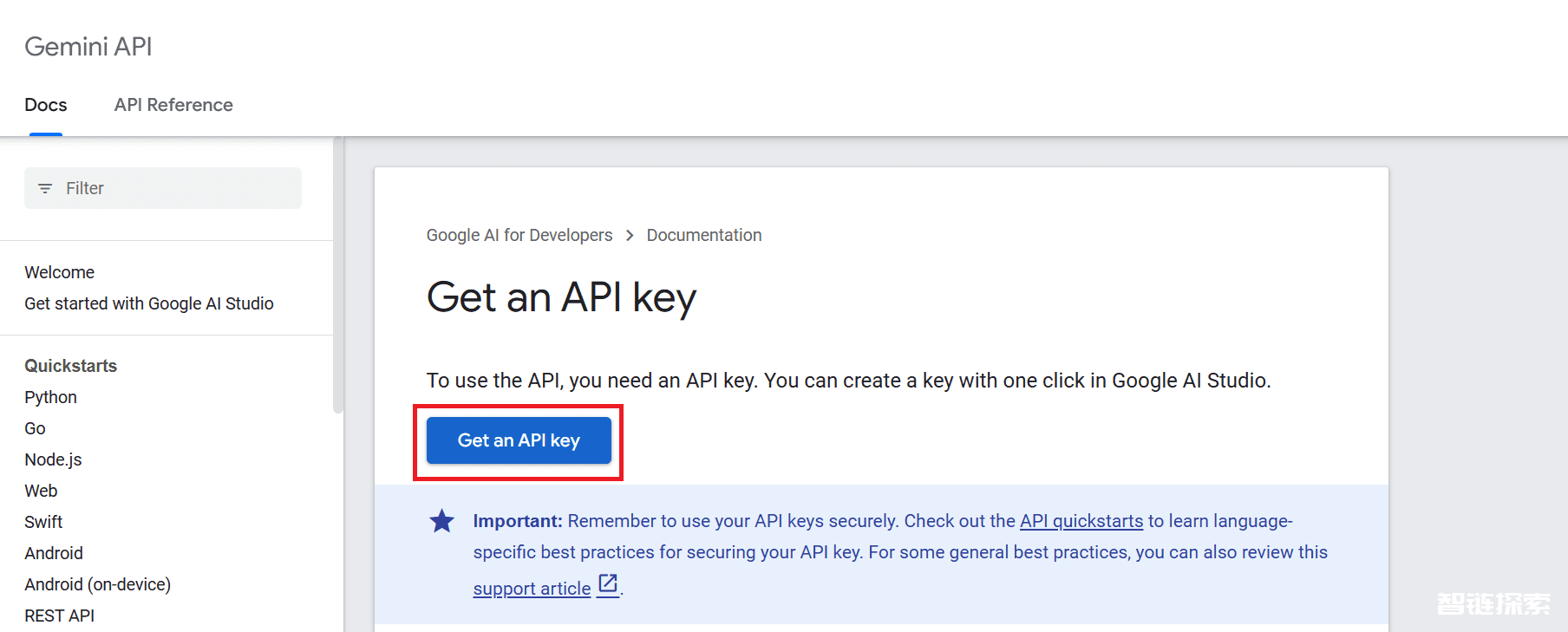
然后,点击“获取API密钥”按钮,随后点击“在新项目中创建API密钥”。
复制API密钥并将其设置为环境变量。我们使用Deepnote,很容易设置名为“GEMINI_API_KEY”的密钥。只要转入到集成,向下滚动并选择环境变量。
在下一步中,我们将使用PIP安装Python API:
pip install -q -U google-generativeai1.
之后,我们将根据谷歌的GenAI设置API密钥,并初始化实例。
import google.generativeai as genai import os gemini_api_key = os.environ["GEMINI_API_KEY"] genai.configure(api_key = gemini_api_key)1.2.3.4.5.
使用Gemini Pro
设置好API密钥后,使用Gemini Pro模型生成内容就很简单。向‘generate_content’函数提供一个提示,将输出显示为Markdown。
from IPython.display import Markdown model = genai.GenerativeModel('gemini-pro') response = model.generate_content("Who is the GOAT in the NBA?") Markdown(response.text)1.2.3.4.5.6.这令人惊讶,但我不同意这个列表。然而,我明白这完全是个人喜好。

Gemini可以为一个提示生成多个响应,名为候选响应。你可以选择最合适的一个。在本文的例子中,我们只有一个响应。
response.candidates1.

不妨让它用Python编写一个简单的游戏。
response = model.generate_content("Build a simple game in Python") Markdown(response.text)1.2.结果很简单,也很中肯。大多数LLM开始解释Python代码,而不是编写代码。

配置响应
你可以使用‘generation_config’变量定制响应。我们将候选响应计数限制为1,添加停止词“space”,并设置最大token和温度。
response = model.generate_content( 'Write a short story about aliens.', generation_config=genai.types.GenerationConfig( candidate_count=1, stop_sequences=['space'], max_output_tokens=200, temperature=0.7) ) Markdown(response.text)1.2.3.4.5.6.7.8.9.
正如你所见,响应在“space“这个单词前停止了。很神奇。

流式传输响应
你也可以使用‘stream ’参数来流式传输响应。它类似Anthropic和OpenAI API,但速度更快。
model = genai.GenerativeModel('gemini-pro') response = model.generate_content("Write a Julia function for cleaning the data.", stream=True) for chunk in response: print(chunk.text)1.2.3.4.5.
使用Gemini Pro Vision
下面我们将加载Masood Aslami的图像,并用它来测试Gemini Pro Vision的多模态性。将图像加载到“PIL”中并显示它。
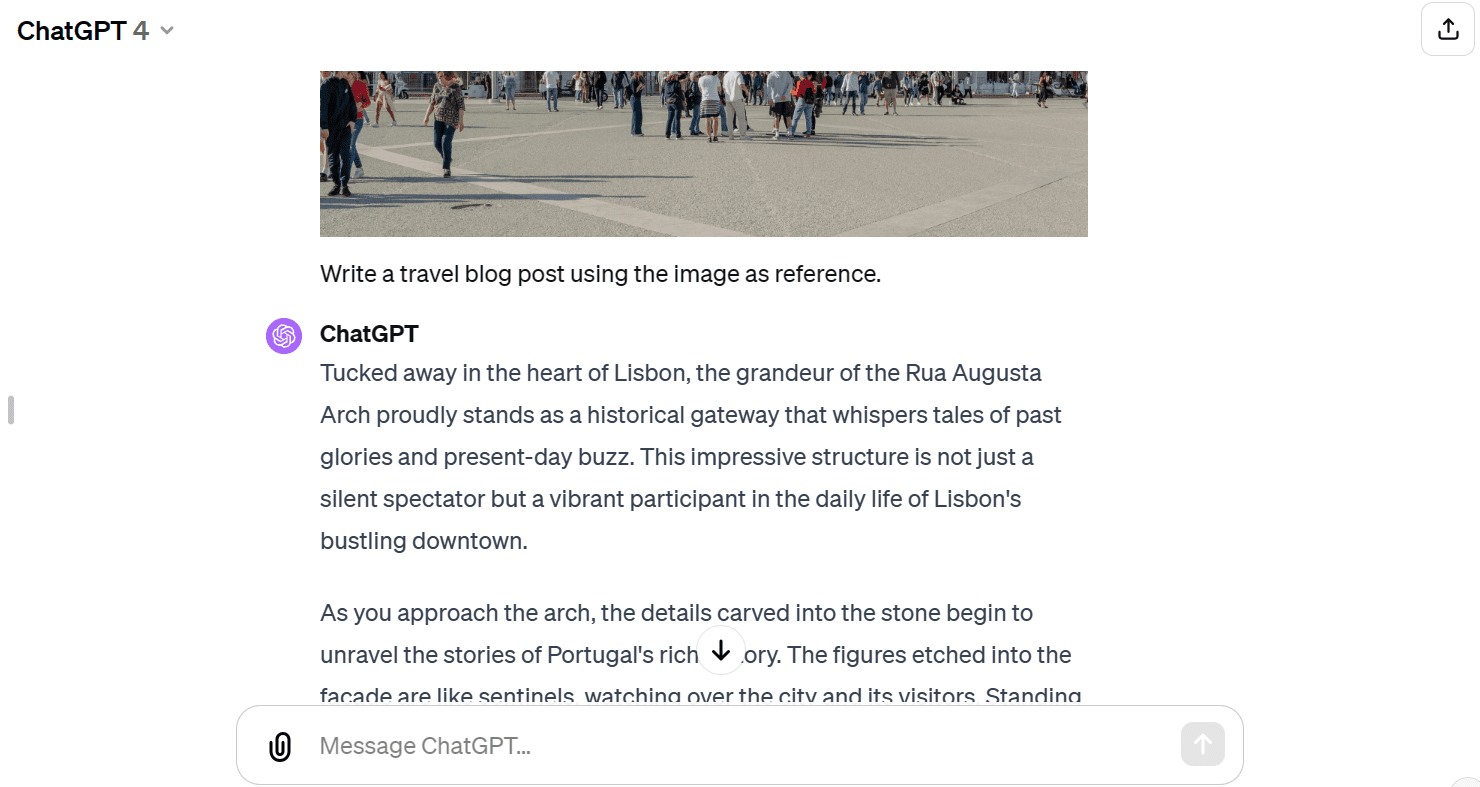
import PIL.Image img = PIL.Image.open('images/photo-1.jpg') img1.2.3.我们有一张奥古斯塔拱门的高质量图像。

不妨加载Gemini Pro Vision模型,并为其提供该图像。
model = genai.GenerativeModel('gemini-pro-vision') response = model.generate_content(img) Markdown(response.text)1.2.3.该模型准确地识别了宫殿,并提供了有关其历史和建筑的更多信息。

不妨将相同的图像提供给GPT-4,并向它询问该图像。两种模型都给出了几乎相似的答案,但我更喜欢GPT-4的响应。

我们将向API提供文本和图像。我们让Vision模型用图像作为参考写一篇旅游博文。
response = model.generate_content(["Write a travel blog post using the image as reference.", img]) Markdown(response.text)1.2.
它为我提供了一个简短的博文,我原以为是更长的格式。

与GPT-4相比,Gemini Pro Vision模型难以生成长格式博文。
聊天对话会话
我们可以设置模型进行来回的聊天会话。这样一来,模型可以使用之前的对话记住上下文和响应。
在本文中,我们已开始了聊天会话,并要求模型帮助我开始Dota 2游戏。
model = genai.GenerativeModel('gemini-pro') chat = model.start_chat(history=[]) chat.send_message("Can you please guide me on how to start playing Dota 2?") chat.history1.2.3.4.如你所见,“chat”对象保存用户和模式聊天的历史记录。

我们还可以以Markdown样式显示它们。
for message in chat.history: display(Markdown(f'**{message.role}**: {message.parts[0].text}'))1.2.
不妨问一个紧跟的问题。
chat.send_message("Which Dota 2 heroes should I start with?") for message in chat.history: display(Markdown(f'**{message.role}**: {message.parts[0].text}'))1.2.3.我们可以向下滚动,并查看模型的整个会话。

使用嵌入
嵌入模型在上下文感知应用程序中越来越受欢迎。Gemini embedding-001模型允许将单词、句子或整个文档表示为编码语义含义的密集向量。这种向量表示可以通过比较不同文本片段对应的嵌入向量来方便地比较它们之间的相似性。
我们可以将内容提供给“embed_content”,并将文本转换为嵌入。就是这么简单。
output = genai.embed_content( model="models/embedding-001", content="Can you please guide me on how to start playing Dota 2?", task_type="retrieval_document", title="Embedding of Dota 2 question") print(output['embedding'][0:10]) [0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664]1.2.3.4.5.6.7.
我们可以通过将字符串列表传递给“content”参数,将多个文本块转换为嵌入。
output = genai.embed_content( model="models/embedding-001", content=[ "Can you please guide me on how to start playing Dota 2?", "Which Dota 2 heroes should I start with?", ], task_type="retrieval_document", title="Embedding of Dota 2 question") for emb in output['embedding']: print(emb[:10]) [0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664] [0.04775657, -0.044990525, -0.014886052, -0.08473655, 0.04060122, 0.035374347, 0.031866882, 0.071754575, 0.042207796, 0.04577447]1.2.3.4.5.6.7.8.9.10.11.12.13.
如果你在重现同样的结果时遇到麻烦,请查看Deepnote工作区(https://deepnote.com/workspace/abid-5efa63e7-7029-4c3e-996f-40e8f1acba6f/project/How-to-Access-and-Use-Gemini-API-55818013-847a-46c6-ac51-9c814955f5cd/notebook/Notebook%201-af572259a2374c39a21eb31a63dc23a7https://deepnote.com/workspace/abid-5efa63e7-7029-4c3e-996f-40e8f1acba6f/project/How-to-Access-and-Use-Gemini-API-55818013-847a-46c6-ac51-9c814955f5cd/notebook/Notebook%201-af572259a2374c39a21eb31a63dc23a7)。
结语
有很多高级函数在本入门教程中并没有介绍。你可以通过《Gemini API: Python快速入门》了解关于Gemini API的更多信息:https://ai.google.dev/tutorials/python_quickstart#generate_text_from_text_inputs.
我们在本教程中学习了Gemini以及如何访问Python API来生成响应。尤其是,我们学习了文本生成、视觉理解、流传输、对话历史、自定义输出和嵌入。然而,Gemini的功能太强大了,本文只涉及皮毛。
原文标题:How to Access and Use Gemini API for Free,作者:Abid Ali Awan
链接:https://www.kdnuggets.com/how-to-access-and-use-gemini-api-for-free




还没有评论,来说两句吧...