

字节跳动,陷入大模型舆论风波。
据The Verge报道:
字节跳动一直在秘密使用OpenAI的技术,来开发自家大语言模型(LLM)。

而在此消息被披露不久,The Verge进一步称OpenAI已经暂停了字节跳动的账户。
具体而言,OpenAI发言人Niko Felix发布的声明如下:
虽然字节跳动使用我们API的量很少,但我们已经暂停了他们的账户,同时我们会进一步调查。
如果我们发现他们的使用不符合规则,我们将要求他们进行必要的更改或终止他们的帐户。
这里提到的“规则”是指在OpenAI的服务条款中有一项明确的规定,那就是OpenAI提供的模型能力,不允许用来被“开发任何与之产品和服务形成竞争的 AI 模型”。
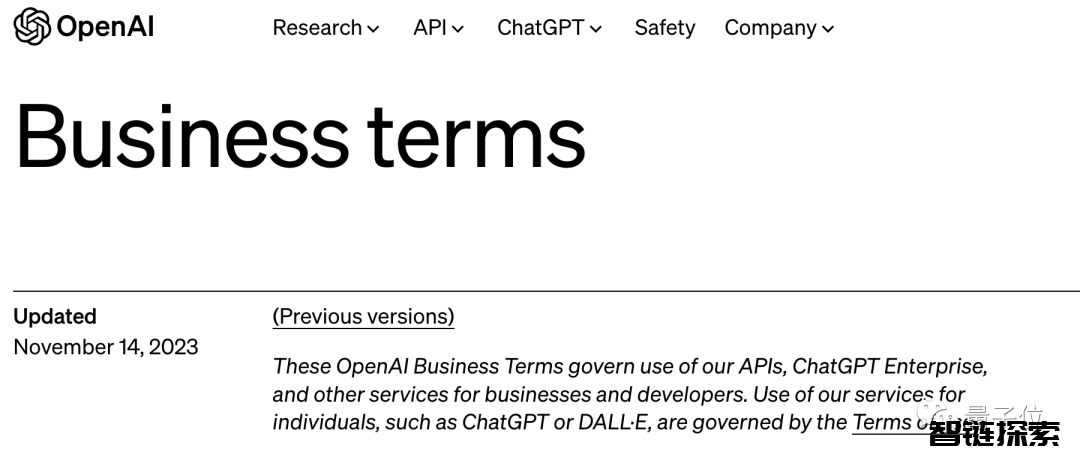
据了解,字节跳动是通过微软购买的OpenAI访问权限,但是微软也制定了与OpenAI同样的政策。
The Verge表示正在向微软做进一步的咨询,是否也会跟OpenAI采取同样的措施暂停字节跳动的账户。
那么,此次的抄袭风波具体是怎么一回事呢?
内部文件被曝光
根据The Verge的说法,证据是来自字节跳动的一份内部文件——海外版飞书Lark的聊天记录。
这份文件表明,字节跳动在代号为“种子计划”(Project Seed)基础大语言模型项目中,几乎是在每个开发阶段都依赖OpenAI的API来进行开发,包括训练和评估模型。
“种子计划”是大约在一年前启动,目前主要研发两个产品,一个是在国内已经上线的Doubao;另一个是针对商业用户的聊天机器人平台,目前正在开发中。
据称,参与“种子计划”的员工是深知过度依赖OpenAI API的后果,于是他们就开始讨论如何通过“数据脱敏”来粉饰证据。
以至于经常会出现员工达到OpenAI API的最大访问上限的情况。
更具体而言,字节跳动更多的是在“种子计划”的早期阶段使用了OpenAI的技术。
The Verge根据内部文件表示,字节跳动大约是在几个月前下达了“模型开发的任何阶段停止使用 GPT 生成的文本”的命令。
不过也正是在这个时候,字节跳动发布了自家大语言模型Doubao。

但The Verge表示即便到了这个时候,字节跳动依旧没有停止违规行为:
字节跳动继续以违反OpenAI和微软服务条款的方式使用 API,包括评估豆包背后模型的性能。
并且还表示一位对字节跳动内部情况有一手消息的人指出:
他们说他们想确保一切都是合法的,但他们实际上只是不想被抓住把柄。
字节跳动已作回应
在The Verge发出这篇报道之后,字节跳动发言人Jodi Seth做出了如下回应:
GPT 生成的数据在“种子计划”的早期开发中用于注释模型,并且在今年年中左右的时候已从字节跳动的训练数据中删除。
字节跳动得到了微软的授权,可以使用GPT API。
我们在非中国市场利用GPT支持我们的产品;但在中国市场,则是使用我们自研的模型来支持Doubao。

微软方面,发言人Frank Shaw则表示:
像Azure OpenAI服务这样的Microsoft AI解决方案,属于我们的有限访问框架的一部分,意味着所有客户都必须申请并得到 Microsoft 的批准。
我们还制定了标准,并提供资源帮助客户负责任地使用这些技术,并符合我们的服务条款。
我们有流程来检测滥用,并在发现违反行为准则的公司时,将停止他们的访问权限。
量子位也在第一时间与字节跳动取得了联系,但目前字节跳动并未做出正式回应。




还没有评论,来说两句吧...