


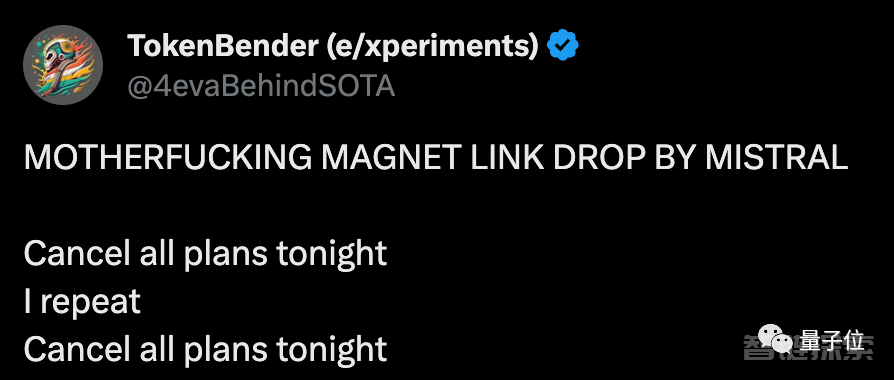
“取消今晚所有计划!”,许多AI开发者决定不睡了。
只因首个开源MoE大模型刚刚由Mistral AI发布。
MoE架构全称专家混合(Mixture-of-Experts),也就是传闻中GPT-4采用的方案,可以说这是开源大模型离GPT-4最近的一集了。
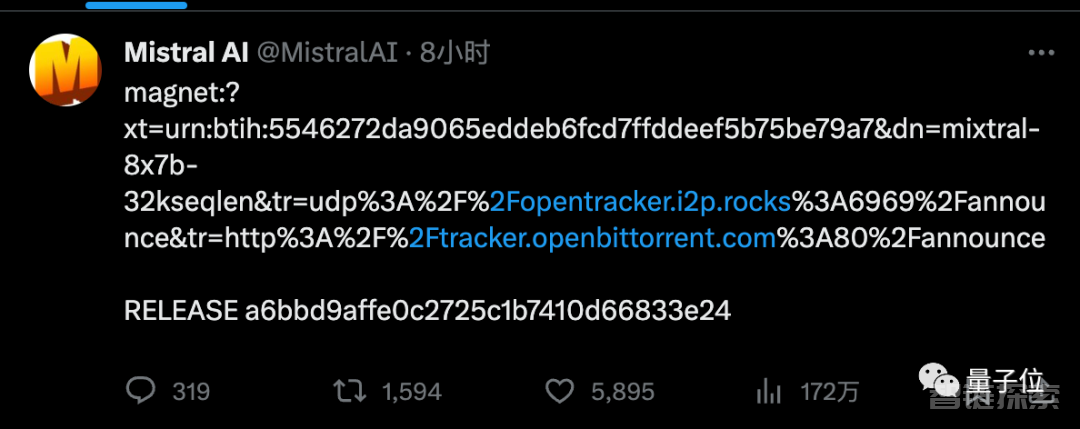
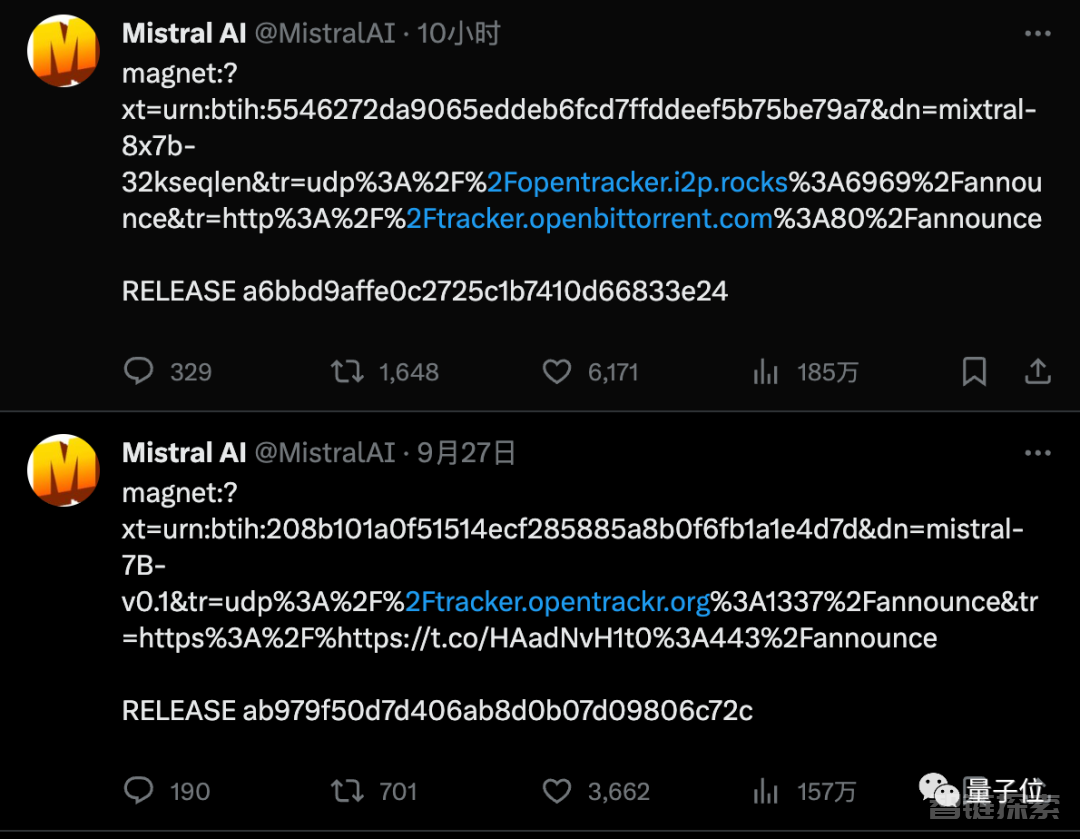
没有发布会、没有宣传视频,只靠一个磁力链接,就产生如此轰动效果。
具体参数还得是网速快的人下载完之后,从配置文件里截图发出来的:
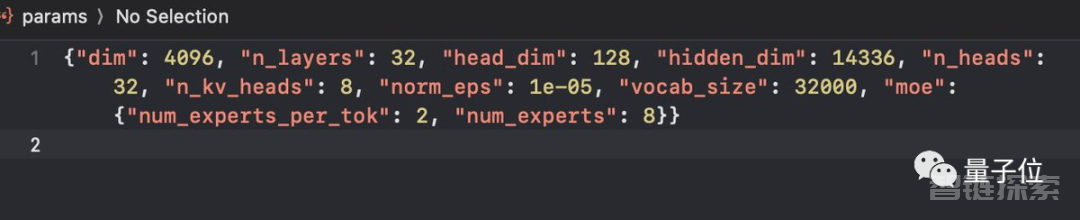
7B参数x8个专家,对每个token选择前两个最相关的专家来处理。
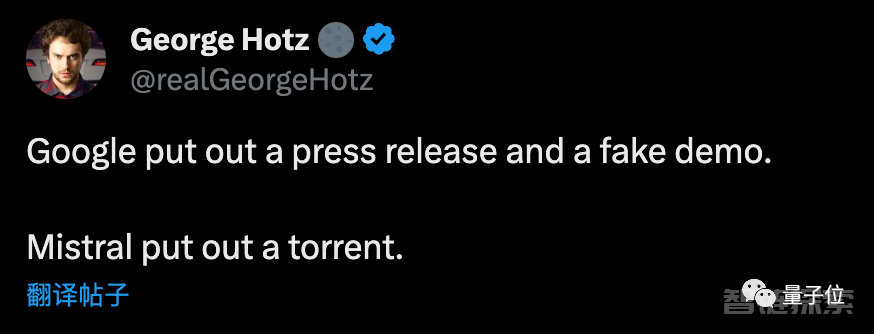
以至于OpenAI创始成员Karpathy都吐槽,是不是少了点什么?
怎么缺了一个那种排练很多次的专业范视频,大谈特谈AI变革啊。
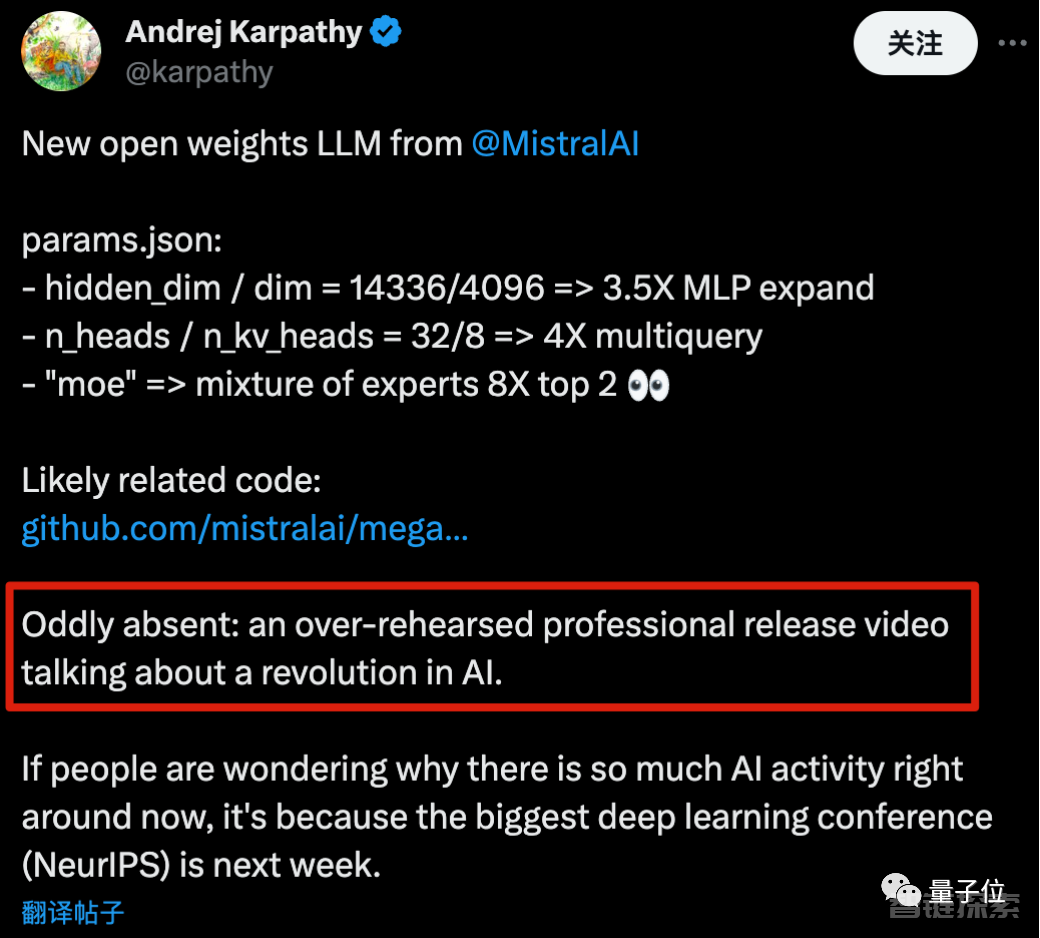
至于吐槽的是谁,懂得都懂了。
以及他还解释了为什么AI社区这几天如此活跃:最大的深度学习会议NeurIPS即将在下周开启。
MoE,开源大模型新阶段?
为何这款开源MoE模型如此受关注?
因为其前身Mistral-7B本来就是开源基础模型里最强的那一档,经常可以越级挑战13B、34B。
并且Mistral-7B以宽松的Apache-2.0开源协议发布,可免费商用,这次新模型很可能沿用这个协议。
在多个评测排行榜上,基于Mistral-7B微调的Zephyr-7B-beta都是前排唯一的7B模型,前后都是规模比他大得多的模型。
LLMSYS Chatbot Arena上,Zephry-7B-beta目前排第12。
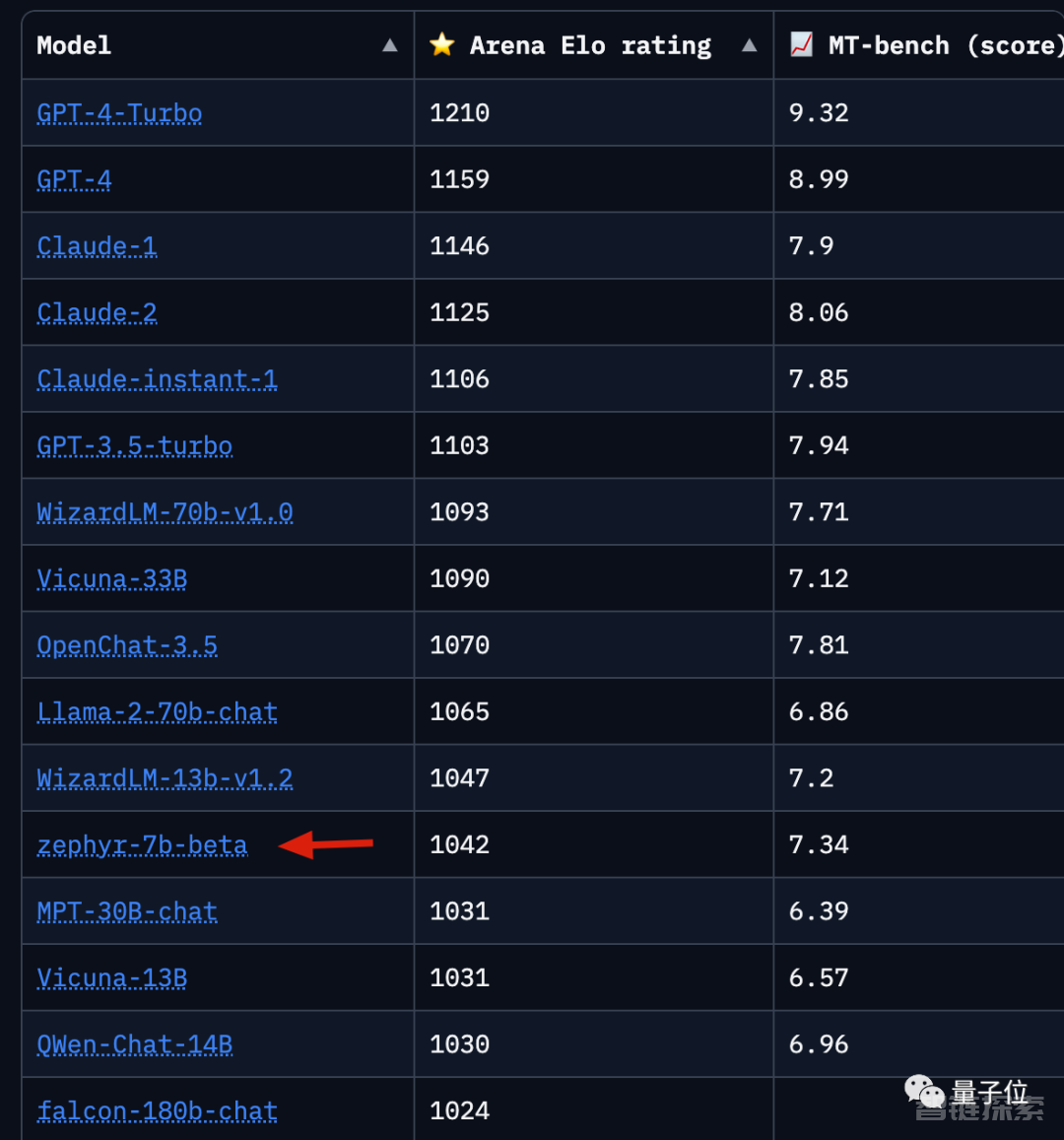
AlpacaEval上,也排到第15。
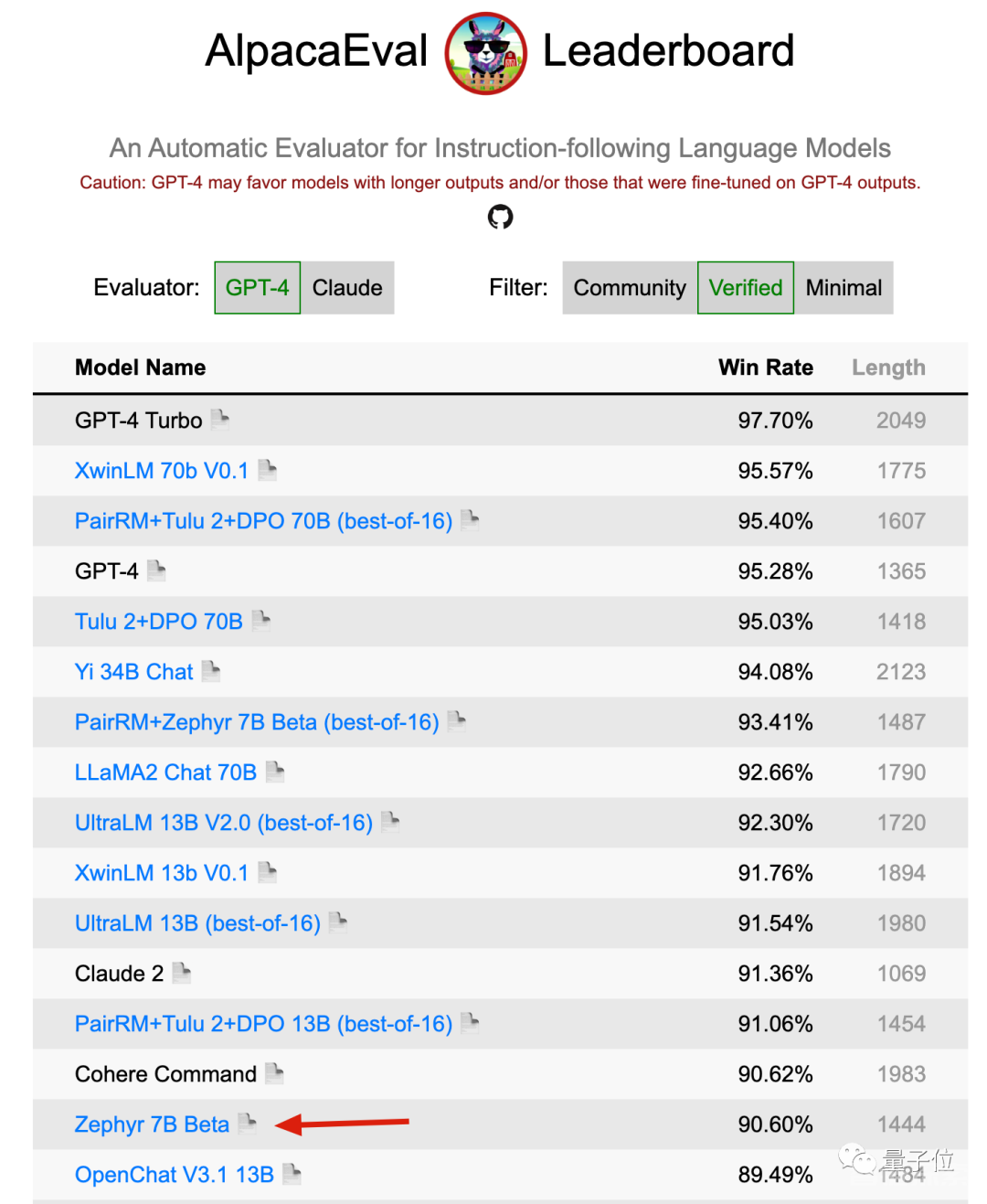
目前这个新的MoE模型连个正式名字都还没有,社区一般称呼它为Mistral-7Bx8 MoE。
但在大家期待的期待中,新MoE模型对比单体Mistral-7B的提升幅度,就应该像GPT-4对比GPT-3.5那样。
但是注意了,有人提醒大家MoE对于本地运行来说不是太友好,因为更占内存
但更适合部署在云端,跨设备专家并行,给公司处理并发需求带来成本优势。
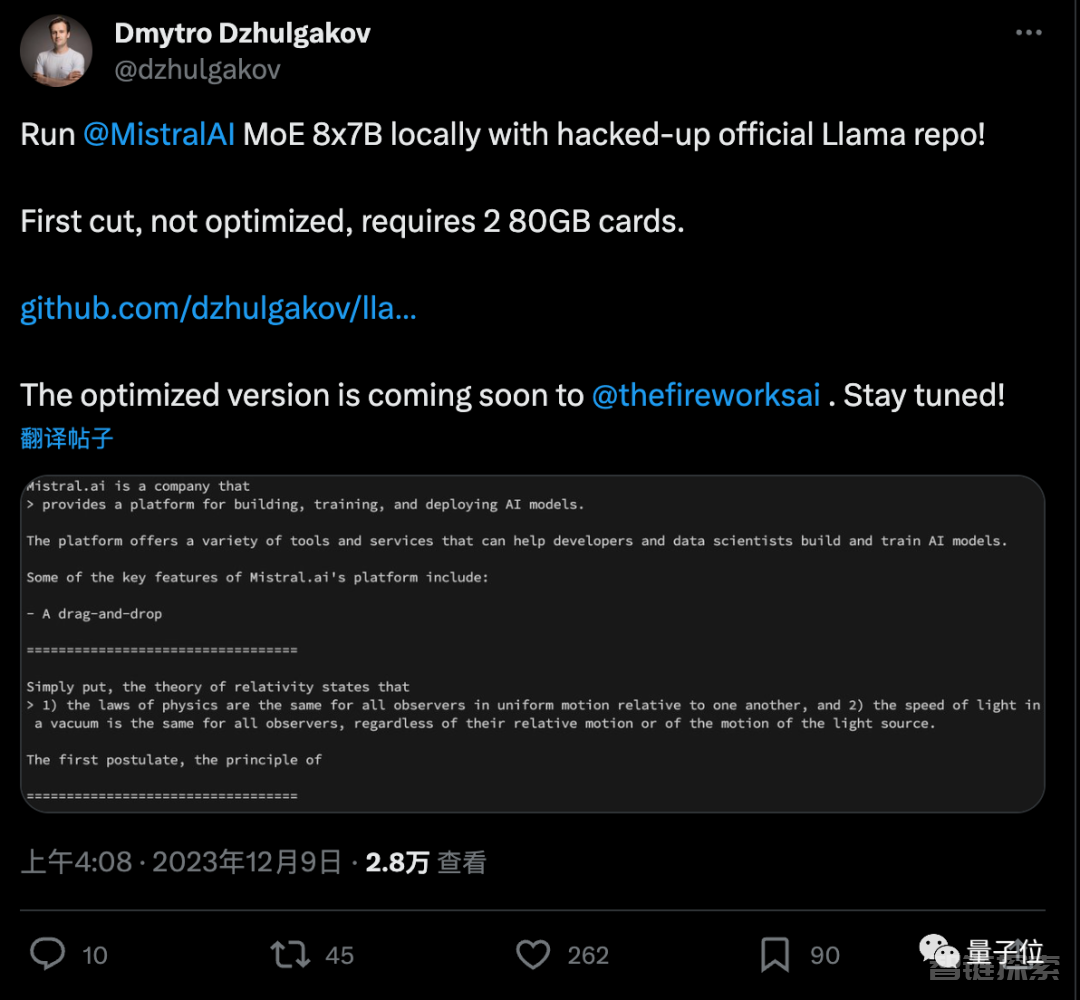
行动比较快的公司是前PyTorch成员出走创办的fireworks.ai。
第一次尝试、没有任何优化的情况下,需要两张80GB内存的卡,优化版本即将推出。
Replicate上也有了可试玩版本,简单试用发现中文水平也不错。
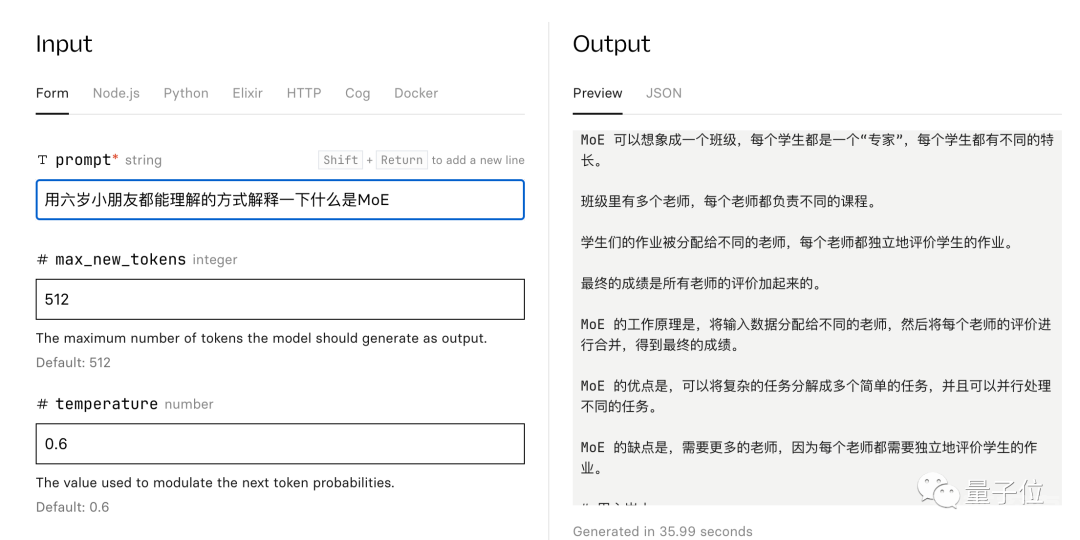
其实Mistral AI也为大家准备了官方配套代码,使用了斯坦福去年发布的轻量级MoE库Megablocks。
创始人:小模型支持更多有意思的应用
Mistral AI由前DeepMind、前Meta科学家创办。
刚刚完成一轮4.87亿美元的新融资,最新估值逼近20亿美元,已晋升独角兽。

三位联合创始人中,CEO Arthur Mensch此前在DeepMind巴黎工作。
CTO Timothée Lacroix和首席科学家Guillaume Lample则在Meta共同参与过Llama系列的研发,Lample是通讯作者之一。
Arthur Mensch曾在接受采访时谈到,让模型变小是支持Agent发展的路径之一。
如果能把计算成本降低100倍,就能构建起更多有意思的应用。
Mistral AI成立于今年5月,种子轮融资1.13亿美元。
9月底,Mistral AI以磁力链接的形式发布第一个开源模型Mistral-7B,当时很多开发者试用后都觉得Llama-2不香了。
12月初,Mistral AI再次甩出开源MoE模型磁力链接,再次掀起一波热潮。
这就是公司官号仅有的几次发言。
不少人都拿来和最近谷歌的过度宣传做对比。
最新的梗图:磁力链接就是新的arXiv。

参考链接:
[1]https://x.com/MistralAI/status/1733150512395038967?s=20。
[2]https://github.com/mistralai/megablocks-public。
[3]https://replicate.com/nateraw/mixtral-8x7b-32kseqlen。




还没有评论,来说两句吧...