

作者简介
Terry,携程自然语言处理和大语言模型算法方向专家,有多年的自然语言处理项目经验和AI落地经验。
一、背景
随着OpenAI的ChatGPT火遍全球,大语言模型(Large Language Model,下文简称LLM)成为了人工智能领域的热门话题。大语言模型是一种基于深度学习的自然语言处理技术,它能够模拟人类的语言能力并生成连贯的文本。这种技术的出现引起了广泛的关注和应用。大型语言模型在机器翻译、文本生成、智能对话等领域发挥着重要作用。在这些领域中,它们能够理解和生成自然语言,使得机器能够更好地与人类进行交流和合作。
无论是在学术研究还是商业领域中,LLM都有潜力成为一个强大的工具,帮助我们更好地理解和利用自然语言。但由于ChatGPT是闭源且信息安全存疑,并不适合在企业内部的所有业务场景使用。此外,最近有大批优秀的开源大语言模型涌现,比如Llama-2。因此,很多企业构建属于自己领域的LLM和配套系统,应用在自身的业务场景中。为了适应旅游场景的应用,我们也构建了一套训练、推理LLM的系统,充分利用LLM的强大能力。
二、LLM训练系统
2.1 训练基础架构
LLM训练系统有预训练(Pretrain)、继续预训练(Continue Pretrain)、微调(Finetune)几个模式。
1)预训练阶段使用的数据是大规模的通用数据,通常训练成本高达数百万GPU-hour,成本很高。例如在Llama-2-70B的预训练中,使用的172万GPU-hour,在Falcon-180B的预训练中,使用了超过700万GPU-hour。
2)继续预训练阶段基于预训练过的基座模型(foundation model),使用特定领域的无标注数据训练,通常需要数千GPU-hour。可以用于学习领域内知识,拓展语言、领域词表。
3)微调阶段基于基座模型,使用特定任务的数据训练,可以使模型对齐某些输出范式,完成特定的任务,通常需要10到1000 GPU-hour,成本较低。代表模型有Alpaca等。
训练框架基于PyTorch + DeepSpeed、Transformers的技术路线,有Nvidia、Meta、Microsoft、HuggingFace等公司支持,并且有广泛社区支持。PyTorch在更新至2.0后,加入compile模式,大幅提升训练速度;DeepSpeed中的ZeRO与offload技术帮助模型在多机多卡的训练中使用较小的显存用量;这些技术简化了百亿到千亿参数的模型的训练,并且在训练中保持稳定。
通过Flash Attention、Apex、算子融合等提高硬件利用率的技术,目前我们可以以超过50%浮点利用率(MFU)的效率训练百亿参数的模型。
2.2 训练参数量
根据可训练的参数量可以分为全参数训练、LoRA、QLoRA等技术。
全参数训练推荐在大量数据及预算充分的情况下使用,训练时模型的全部参数参与训练,可以精准的对齐目标范式;LoRA、QLoRA作为参数高效的训练方式,推荐在资源受限或需要快速获取结果的情况下使用。
2.3 拓展词表
Llama原生词表中1个中文字通常对应2个token,导致中文内容的token数量较长,不利于模型训练与推理的效率;并且Llama的预训练语料中中文占比较少,没有针对中文语料优化。
拓展词表可以帮助解决这两个问题。我们在Llama词表的基础上拓展了超过1万的中文词表,并使用大量中文语料继续预训练,模型在中文数据上的困惑度(Perplexity)显著降低。在训练与推理时,相同字数的中文数据的token减少一半,成本降低。
2.4 Flash Attention
在GPU SRAM与HBM(High Bandwidth Memory)的IO速度相差十多倍,使用更少的内存访问量可以显著提高计算速度。Flash Attention 的目标是避免从HBM中读写注意力矩阵。Flash Attention解决了两个问题达到这个目标:
1)在不访问整个输入的情况下计算 softmax reduction。Flash Attention重组注意力计算,将输入分成块,并在输入块上进行多次传递,从而逐步执行 softmax reduction。
2)在后向传播中不能存储中间注意力矩阵。存储前向传递的 softmax 归一化因子,在后向传播中快速重新计算片上注意力,这比从 HBM 中读取中间注意力矩阵的标准方法更快。
三、LLM推理系统
LLM的推理系统的关键的是延迟与成本。延迟关系到用户的感受,最低标准是不能低于人类的打字速度,每秒1-3字,在给用户整段文章或者代码提示时需要更快的速度,理想情况时可以略高于人类看文字的速度,约每秒5-10字。然而高速通常意味着更高的硬件要求,更高的成本。
我们的推理部署系统有低延迟、高吞吐、高并发、高可用的特性。(以13B模型、1xA100部署为例)
1)低延迟:最快生成速度20ms/token;
2)批量生成吞吐量达到1600+ token/s;
3)可有效应对并发数超过100;
4)高可用部署,仅需10分钟即可部署两地、多区域部署。
3.1 KV-Cache
LLM在推理时是一个自回归的过程,使用前n个token作为输入预测第n+1个token。其中attention部分使用的K和V部分的前n token的向量在每次预测中时是不变的,可以将KV的值缓存下来,在预测下一个token的时候避免重复计算。
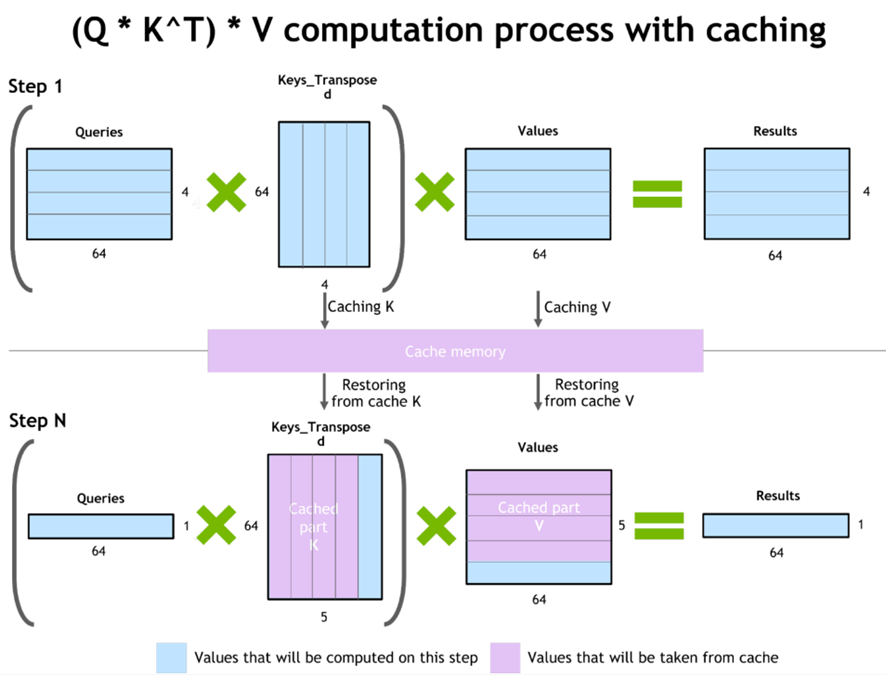
3.2 PagedAttention
在应用KV-cache进行LLM的自回归解码过程中,LLM 的所有输入token都会生成其注意K和V张量,并且这些张量保存在x显存中以生成下一个token。其中有两个特点导致内存大量浪费,大约浪费了60%-80%的显存:
1)缓存占用大:在Llama-13B中单个序列最多占用1.7GB;
2)动态:缓存大小取决于序列长度,序列长度变化很大并且不可预测。
PagedAttention 允许在不连续的内存空间中存储连续的KV张量。PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量toke的KV。在注意力计算过程中,PagedAttention 内核有效地识别并获取这些块。除此之外使用的内存共享,Copy-on-write等机制大幅降低内存使用量,并提升吞吐量。比HuggingFace默认方法提高最多24倍。
3.3 Continuous Batching
批量预测可以减少模型的加载次数,提高内存带宽利用率,提高计算资源的利用率,最终增加吞吐量、降低推理成本。
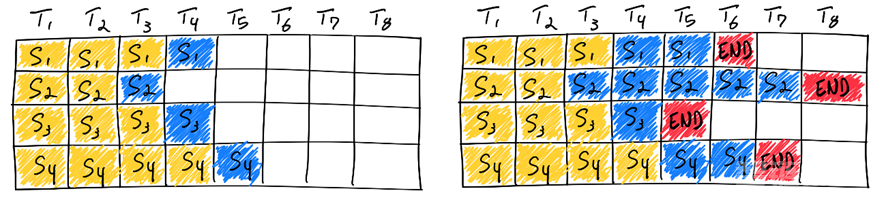
传统的批量预测是静态批处理,批处理的大小在推理完成前保持不变。然而在LLM的推理中每个请求逐个生成token,直到生成到最大长度或者停止token(EOS),在同一批次中每个请求的生成长度几乎不可能相同。如果采用传统的静态批处理,需要不停生成直到最长的序列完成,GPU并不能完全充分利用。在极端情况,同一批次同时生成最大长度为100token与8000token的序列时,需要等待8000 token的序列完成,才能进行下一批次的预测,这样GPU利用率会低于分别推理每一条请求,即批处理大小为1的情况。
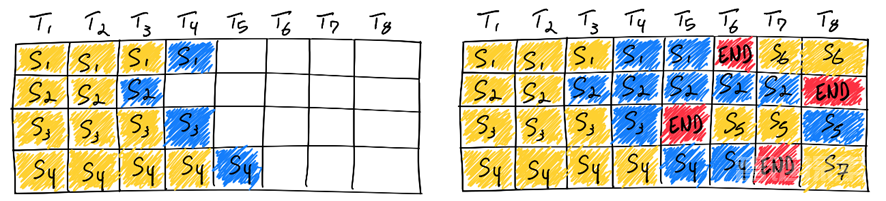
为了充分利用GPU,增大吞吐量,可以使用连续批处理(Continuous Batching)。在模型输出停止token后放入新的待生成序列,批次中的每一个空白token都可以被充分利用。
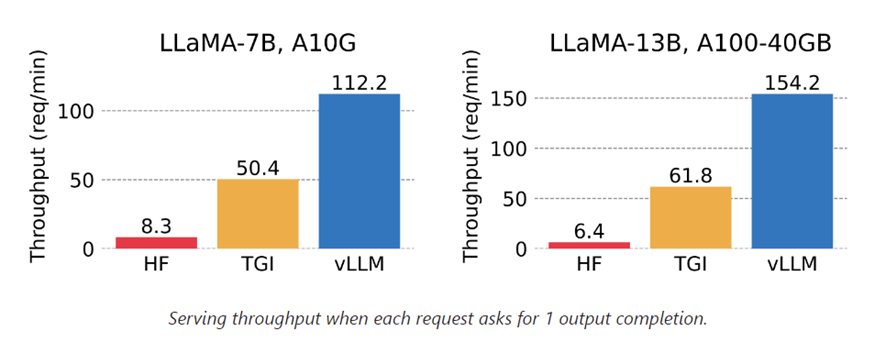
3.4 实际推理速度
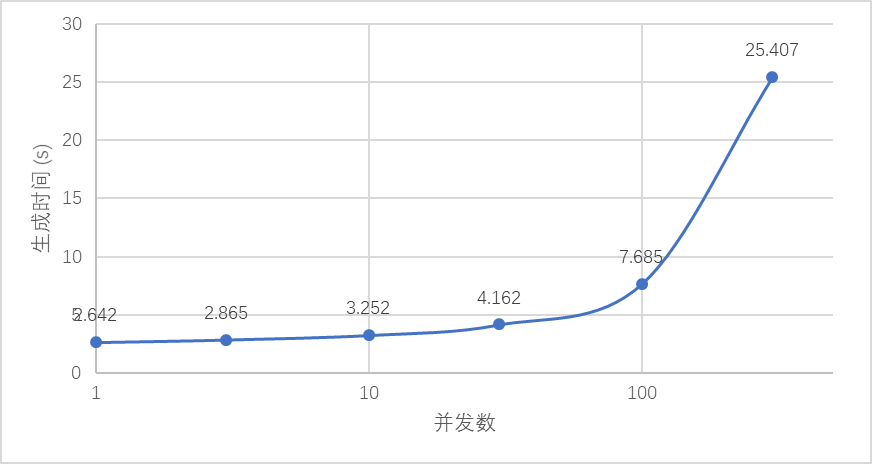
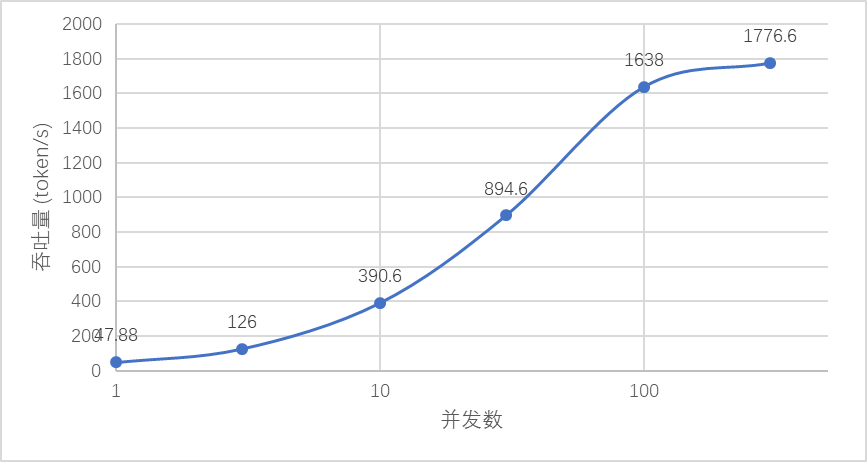
以部署在A100的13B模型为例,从第1个token生成至128token,在并发为1时可以实现2.6qps,在并发100时可以实现13qps,并且延迟得到有效控制,用户感知的生成token速度在16-48 token/s,超过人类聊天时的打字速度,在客服聊天场景下体验良好。在需要高吞吐量的场景下,最高可以超过1700 token/s。按照A100 20元/小时的成本估算,约0.003元/1000token,比使用GPT-3.5的使用成本低5-10倍。
如下图所示,并发限制在100时可以达到用户感知与吞吐量的最佳平衡,用户无需忍受超长时间的等待,服务器可以以较低的成本提供服务。
四、旅游场景的应用
4.1 智能客服机器人
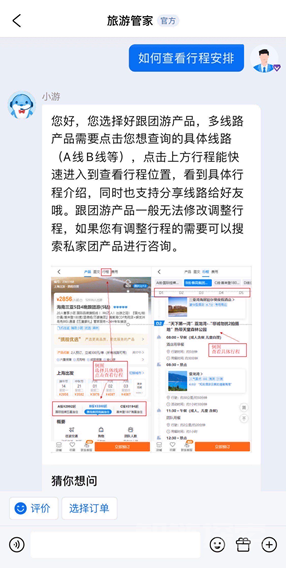
智能客服机器人在携程的服务环节起到非常重要的作用,60%以上的客人通过智能客服机器人等自助功能解决咨询问题,例如下图中的场景。
传统的智能客服机器人,一般借助分类或者匹配模型,准确识别用户的意图,进而回答客人问题或者帮助客人解决问题。但传统的分类或匹配模型经常面临召回率不高,缺少训练语料等问题,特别是针对较为长尾的用户意图。一般情况下,有了充足的高质量训练语料,模型才能有好的效果,而为了收集高质量语料,往往需要投入较多的人力。
大语言模型系统,解决了上述的问题。首先,LLM可以取代传统小模型,完成识别用户意图的任务,并且在准确率和召回率上都有提升。此外,在我们LLM推理系统的加持下,LLM的推理速度可以达到传统小模型的水平。线上数据表明,在识别意图方面,LLM相比于传统模型,准确率提升5%以上,召回率提升20%以上,而响应速度保持不变。
其次,由于LLM使用成本较高,对于继续使用小模型的场景,借助LLM的生成能力,可以轻松构造出大量的高质量语料,并且这些样本类型多样,与客人的真实问题相近。通过这种方式可以提高模型的泛化性能,还能节省人力投入。目前已经落地的场景中,准备语料的人力投入平均从20人日减少到5人日以下。
4.2 信息抽取
在旅游的服务场景中,往往从客人或供应商获取的是大段的非结构化文本信息,此时需要依赖人工进行信息抽取并填表,需要花费很高的人工成本。
而采用传统算法进行抽取,实际使用中的准确率和召回率都不是很高。此外,当提取复杂关系的实体时,需要花费大量时间设计模型与规则,依然有很高的开发成本。
大语言模型系统,解决了上述的问题。使用LLM只需要简单地构造prompt,就能轻松识别复杂关系的实体,开发成本大大降低。
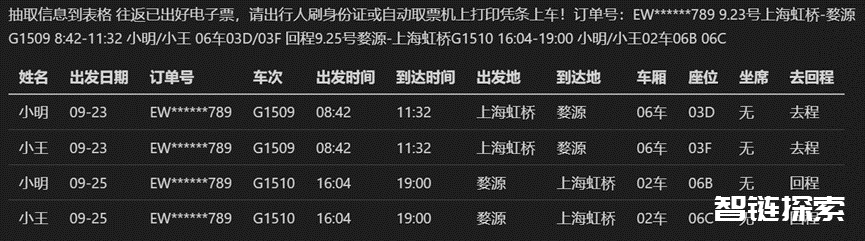
以下图的火车票信息抽取场景为例,非结构化文本内包含多人、多时间、不同出发地、到达地、车厢、座位等实体,并且输出也需要归纳为多行。经过微调后的LLM,可以准确地将目标信息结构化输出为表格。针对火车票信息抽取场景,相比于采用传统算法,LLM的抽取准确率可以从80%提升到95%以上,而开发人日从5人日左右减少到1人日以下。
4.3 会话总结
在客服场景中,不同时间或不同场景,往往会由不同的客服人员服务客人。当客人的对话结束时,需要对客人的对话记录进行归纳、总结,便于后续其他客服人员服务客人时,能快速了解之前的背景信息,否则需要花费时间去查看历史对话记录。
如果依赖人工总结,会花费大量的人工成本。而采用传统的算法小模型,很容易造成信息丢失,准确率不高等问题。
大语言模型系统,解决了上述的问题。借助LLM强大的生成能力,我们可以通过调整prompt,让模型对会话内容进行归纳,并按我们需要的方式输出,例如将客人问题发生的时间、地点、任务等信息,串联成一段通顺且便于理解的话,也可以将客人的问题总结成标签。
线上数据表明,采用LLM,准确率相比小模型提升5%以上,节省客服人员平均每段对话的查看时间2分钟以上。
五、未来与展望
除了大语言模型以外,其他的大模型也在高速发展中,多模态大模型未来会成为主流。可以预见到,大模型在旅游领域的未来是非常广阔的,随着科技的不断发展,大模型将在旅游行业中发挥重要作用。例如:
帮助旅游企业进行市场分析和预测:通过对大量的数据进行分析,大模型可以帮助企业了解旅游市场的趋势和消费者的需求,从而更好地制定营销策略和推出符合市场需求的产品。
提供个性化的旅游推荐和定制服务:通过分析用户的历史数据和偏好,大模型可以为用户提供个性化的旅游推荐,包括旅游线路、酒店、景点等推荐场景。同时,大模型还可以根据用户的需求进行旅游行程的定制,提供更好的旅行体验。
随着使用量的提高,对模型的反馈也可以帮助模型进行大规模的人类反馈的强化学习(RLHF),进一步提升大模型的性能,实现更优秀的表现。




还没有评论,来说两句吧...