

深度学习进入新纪元,Transformer的霸主地位,要被掀翻了?
2017年6月12日横空出世,让NLP直接变天,制霸自然语言领域多年的Transformer,终于要被新的架构打破垄断了。
Transformer虽强大,却有一个致命的bug:核心注意力层无法扩展到长期上下文。
刚刚,CMU和普林斯顿的研究者发布了Mamba。这种SSM架构在语言建模上与Transformers不相上下,而且还能线性扩展,同时具有5倍的推理吞吐量!

论文地址:https://arxiv.org/abs/2312.00752
论文一作Albert Gu表示,二次注意力对于信息密集型模型是必不可少的,但现在,再也不需要了!

论文一出,直接炸翻了AI社区。
英伟达首席科学家Jim Fan表示,自己一直期待能有人来推翻Transformer,并且对Albert Gu和Tri Dao多年以来做出替代Transformer序列架构的尝试表示感谢。

「你们做的研究太酷了,一会儿蹦出一个来,不能稍微停一下吗!」

「湖人粉表示,对Mamba这个名字很满意!」

对于这个架构为何取名曼巴,作者也给出了解释——

- 速度快:原因在于(1)序列长度线性缩放的简单递归,(2)硬件感知设计和实现
- 致命性:它对序列建模问题具有致命的吸引力
- 就连发出的「声音」都很像:其核心机制是结构化状态空间序列模型(S4)的最新演进……SSSS
性能碾压Transformer?
Mamba源自Albert Gu之前「结构化状态空间模型」的相关工作,可以看作是强大的循环运算符。这就得以实现序列长度的线性缩放和快速自回归解码。

论文地址:https://arxiv.org/abs/2111.00396
然而,以前的递归模型的缺点是,它们的固定大小状态难以压缩上下文。
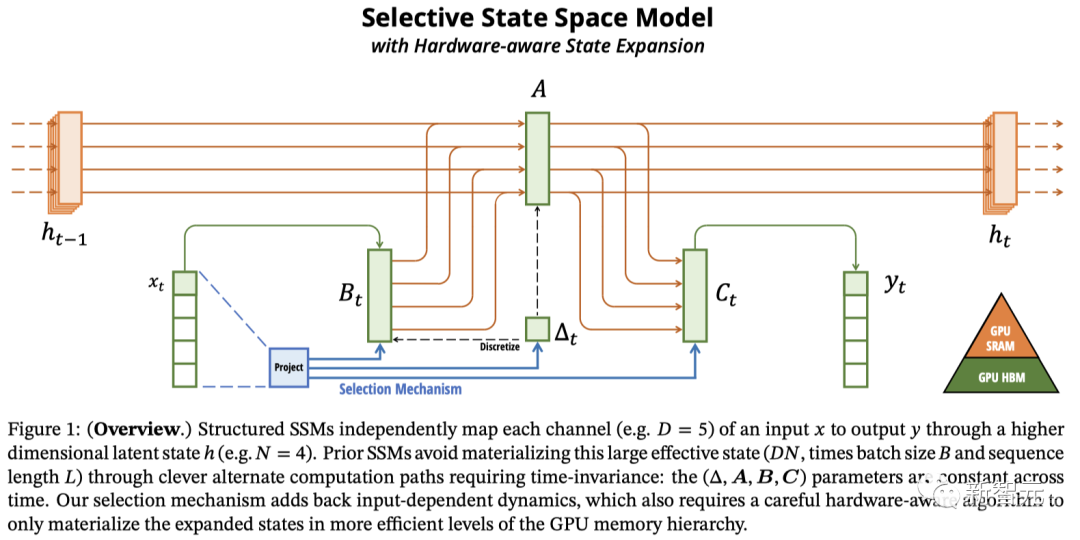
而Mamba的主要贡献,就是引入了「选择性SSM」,这是S4的简单泛化,可以选择性地关注或忽略输入。

这一小小的改变——只需让某些参数成为输入的函数——就能让它立即解决对以往模型来说艰巨无比的任务。
例如,它可以无限长地推断出重要的「联想回忆」任务的解决方案!(训练长度256,测试长度1M)
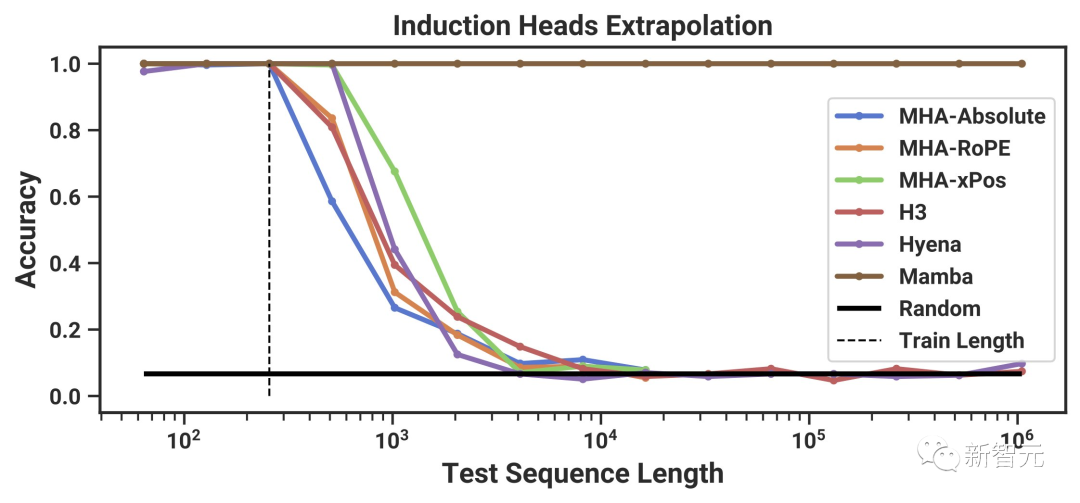
关键就在于:这一变化涉及到非同小可的效率权衡,S4的原始设计有着特定的原因。
在DNA和音频等其他模态的真实数据上,Mamba的预训练性能超过了之前的专业基线(如HyenaDNA和SaShiMi)。
值得注意的是,无论在合成、DNA还是音频数据中,随着序列长度达到1M+,Mamba的性能也在不断提高!
而另一位一作Tri Dao介绍了如何利用硬件感知设计应对这一挑战,以及Mamba在语言方面的强大性能。
他表示,正如Albert所说,状态空间模型(SSM)的特征,就是其固定大小的递归状态。如果想实现更好的性能,就要求这种状态更大,并且更具表现力。
不幸的是,因为较大的状态太慢,会导致无法在实践中使用递归进行计算。
过去,曾有基于S4的SSM通过做出结构假设(也即线性时间不变性)来解决这个问题,这样就可以在不实现大状态的情况下,进行等效的「卷积模式」计算。
但这次CMU和普林斯顿研究者的方法是选择性SSM,只能循环计算。
为了解决这个计算瓶颈,他们利用了其他高效的硬件感知算法(如FlashAttention)使用的技术。
需要注意的是,对于Mamba(和一般的SSM),这种方法只能在SRAM中实现扩展状态,而不是在主存储器中。
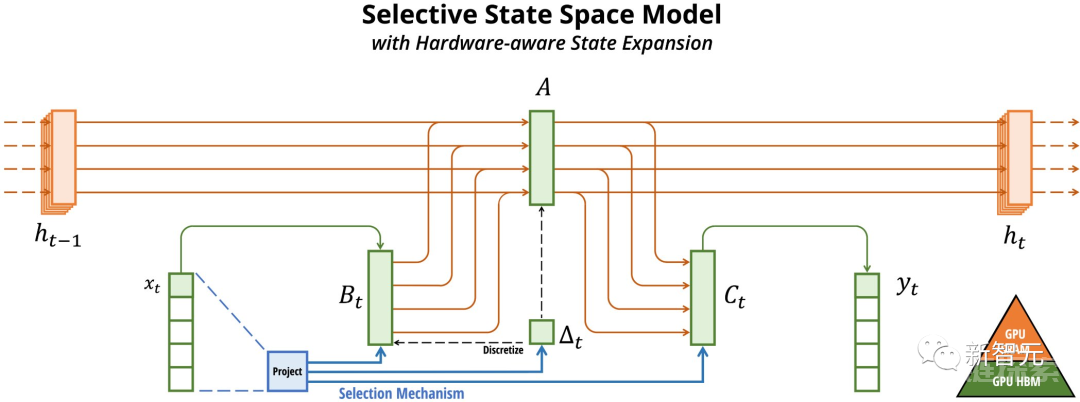
此外,scan实现比基本的PyTorch/JAX快30倍,当序列长度变长时,比二次FlashAttention还要快几个数量级。
而且,由于采用了固定大小的循环状态(没有KV缓存),Mamba的LM推理速度比Transformer快5倍。
从经验上看,两位作者取得的最重要的成果是在语言建模上,这也是以前的SSM所瞄准的领域(比如H3,也即Mamba的前身)。

论文地址:https://arxiv.org/abs/2212.14052
然而这时,自己的工作仍然不及Transformer。并且他表示,当时没有哪个模型能真正与精调后的Transformer相抗衡。

然而,惊喜忽然来了!
根据Chinchilla缩放定律进行预训练时,Mamba的表现忽然就优于一个非常强大的现代「Transformer++」模型(接近Llama模型)!
而在300B token上训练完成后,Mamba的性能,已经大大优于同类的开源模型。
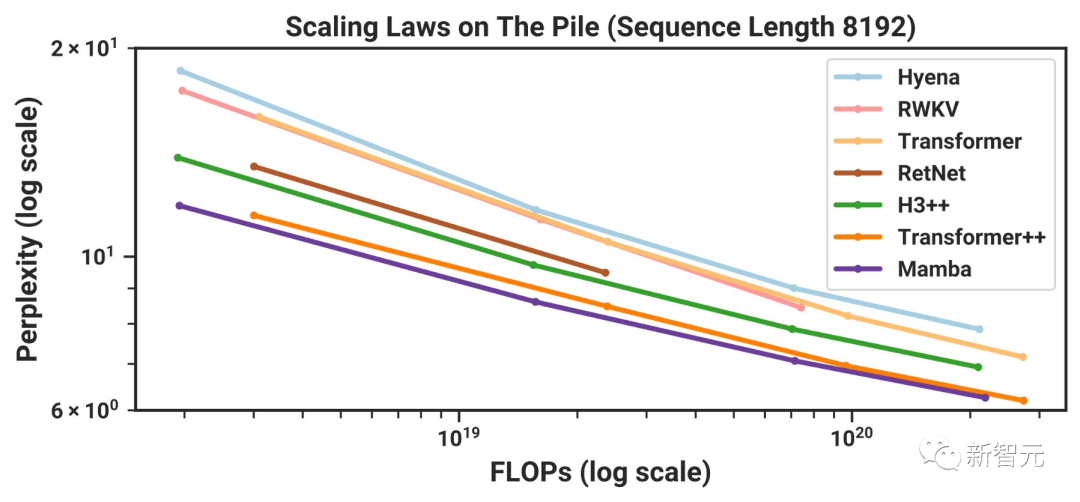
最后,作者总结道:硬件感知思维可以开启新的架构设计。
展望未来,这种新架构能否利用围绕Transformers构建的硬件/库?它将如何改变其他领域(基因组学、音频、视频)的序列扩展?
为此,作者还发布了一系列模型的权重(参数量最高可达2.8B,在300B token上训练),以及快速推理代码。
项目地址:https://github.com/state-spaces/mamba
击败Transformer的架构,是怎样诞生的
现在的基础模型,几乎都是基于Transformer架构和其中最核心的注意力模块来构建的。
为了解决Transformer在处理长序列时的计算低效问题,学界开发了很多二次方时间复杂度的架构,比如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(SSM)。
然而,这些架构在处理语言时,表现并不如传统的注意力模型。
研究人员发现,这些模型的主要弱点在于它们难以进行基于内容的推理,并因此作出了几项改进:
首先,通过让SSM参数成为输入数据的函数,可以解决这类模型在处理离散数据类型时的不足。
这就使得模型能够根据当前的token在序列长度的维度上选择性地传播或遗忘信息。
其次,尽管这样的调整使得模型无法使用高效的卷积,但研究人员设计了一种适应硬件的并行算法,并在循环模式下实现它。
研究人员将这种选择性的SSM集成进了一个简化的端到端神经网络架构中,这种架构不需要注意力机制,甚至也不需要MLP(多层感知器)模块,这就是研究人员提出的Mamba。
Mamba在快速推理方面表现出色(比Transformers高5倍的处理速度),并且随着序列长度的增加,其性能线性增长,在处理长达百万长度的序列时表现更佳。
作为一个通用的序列处理模型,Mamba在语言、音频和基因组学等多个领域都获得了最先进的性能表现。
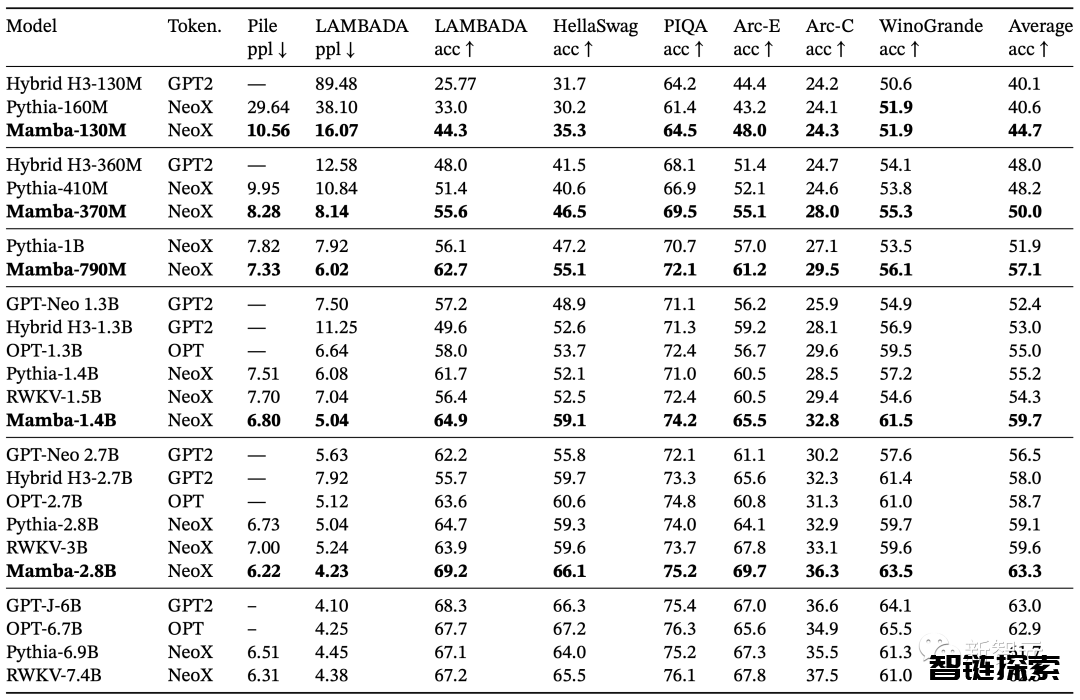
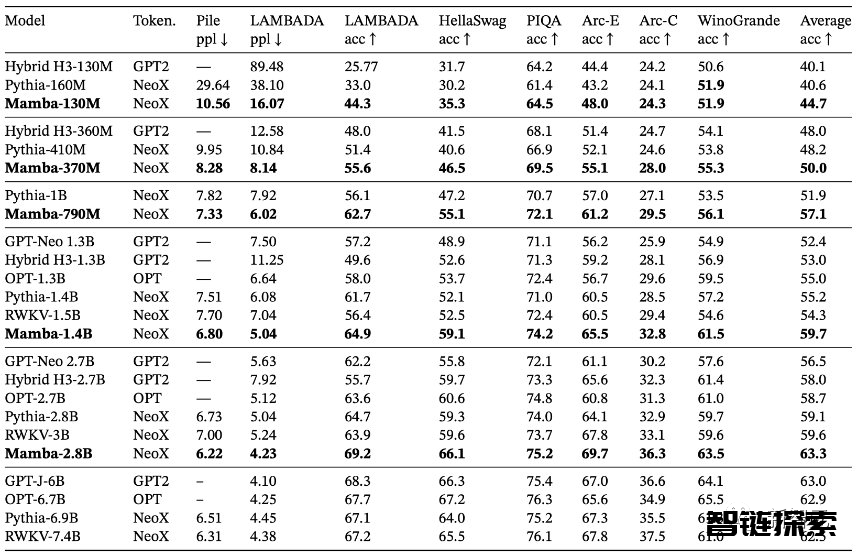
在语言建模方面,Mamba-3B模型在预训练和后续评估中性能达了两倍参数量的Transformers模型性能。
通过实证研究,研究人员验证了Mamba在作为基础模型(FM)的核心框架方面的巨大潜力。
这种潜力不仅体现在预训练的质量上,还表现在特定领域任务的性能上,涵盖了多种模态和环境:
- 合成任务
在重要的合成任务中,如复制和归纳等,Mamba不仅能轻松解决,还能推断出无限长(>100万个token)的解决方案。
- 音频和基因组学
在音频波形和DNA序列建模方面,Mamba的表现优于SaShiMi、Hyena和Transformers等先前的SOTA模型,无论是在预训练质量还是下游指标方面(例如,在具有挑战性的语音生成数据集上,FID降低了一半以上)。
在这两种情况下,它的性能随着上下文长度的增加而提高,最高可达百万长度的序列。
- 语言建模
Mamba是首个线性时间序列模型,无论是在预训练复杂度还是在下游任务评估中,都能实现Transformer级别的性能。
将模型规模扩大到10亿参数后,研究人员证明Mamba的性能超过了Llama等大量基线模型。
Mamba语言模型与同体量的Transformer相比,具有5倍的生成吞吐量,而且Mamba-3B的质量与两倍于其规模的Transformer相当(与Pythia-3B相比,常识推理的平均值高出4分,甚至超过了Pythia-7B)。
选择性状态空间模型
研究人员利用合成任务的直觉来激发他们的选择机制,然后解释如何将该机制合并到状态空间模型中。由此产生的时变SSM无法使用卷积,这对如何有效地计算它们提出了技术挑战。
研究人员通过利用现代硬件上的内存层次结构的硬件感知算法克服了这个问题。然后,研究人员描述了一个简单的SSM架构,没有注意力机制,甚至没有MLP模块。最后,研究人员讨论选择机制的一些附加属性。
动机:选择作为压缩手段
研究人员认为序列建模的一个基本问题是将上下文压缩成更小的状态。他们从这个角度来看待流行序列模型的权衡(tradeoffs)。
例如,注意力在某些方面非常有效,但是在另一些方面又很低效,因为它完全不压缩上下文。从这一点可以看出,自回归推理需要显式存储整个上下文(即KV缓存),这直接导致Transformers的线性时间推理和二次时间训练缓慢。
另一方面,循环模型是高效的,因为他状态是有限的,这意味着推理时间是恒定的,并且训练的时间也将会是线性的。
然而,注意力的有效性受到这种状态压缩上下文的程度的限制。
为了理解这一原理,研究人员重点关注两个合成任务的运行示例(如下图2)。
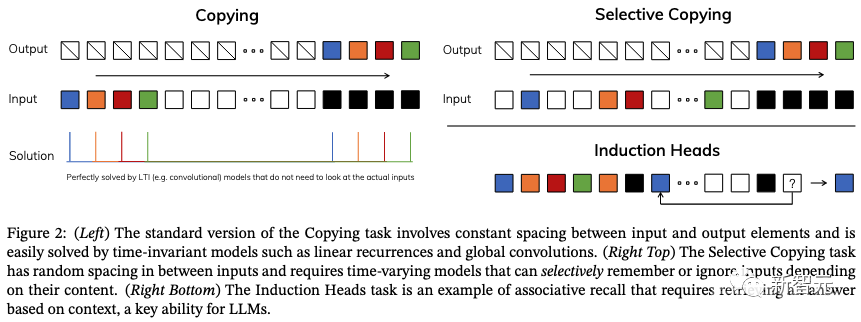
选择性复制(Selective Copying)任务通过改变要记忆的标记的位置来修改流行的复制任务。它需要内容感知推理才能记住相关标记(彩色)并过滤掉不相关标记(白色)。
归纳头(Induction Heads)任务是一种众所周知的机制,以前的研究假设它可以解释LLM的大多数情境学习能力。它需要上下文感知推理来知道何时在适当的上下文(黑色)中产生正确的输出。
这些任务揭示了LTI模型的失效模式。从循环的角度来看,它们的恒定动态(例如(2)中的(A,B)转换)不能让它们从上下文中选择正确的信息,或者影响沿输入相关的序列传递的隐藏状态方式。
从卷积的角度来看,众所周知,全局卷积可以解决普通复制任务,因为它只需要时间感知,但由于缺乏内容意识,它们在选择性复制任务上有困难(如上图)。
更具体地说,输入到输出之间的间距是变化的,并且不能通过静态卷积核进行建模。
总之,序列模型的效率与有效性权衡的特征在于它们压缩状态的程度:高效模型的状态必须要小,而模型效果好必须要求这个小状态要包含上下文中所有必要信息的状态。
而相反,研究人员构建的序列模型的基本原则是选择性:或者是关注或过滤输入到序列状态的上下文感知能力。
特别是,选择机制控制信息如何沿着序列维度传播或交互。
通过选择改进SSM将选择机制纳入模型的一种方法是:让影响序列交互的参数(例如 RNN 的循环动态或 CNN 的卷积核)依赖于输入。

算法1和2说明了研究者使用的主要选择机制。
主要区别在于简单地使输入的几个参数Δ、B、C成为函数,以及整个张量形状的相关更改。
需要注意,这些参数现在具有长度维度 ,这意味着模型已从时不变(time-invariant)改为时变(time-varying)。
这就失去了与卷积的等价性,并影响了其效率。
简化的SSM架构
与结构化SSM一样,选择性SSM是独立的序列转换,可以「灵活地合并到神经网络中」。
H3架构是最著名的SSM架构的基础,该架构通常由受线性注意力启发的块与 MLP(多层感知器)块交织组成。研究人员通过将这两个组同质堆叠件合并为一个组件来简化这一架构(如下图)。
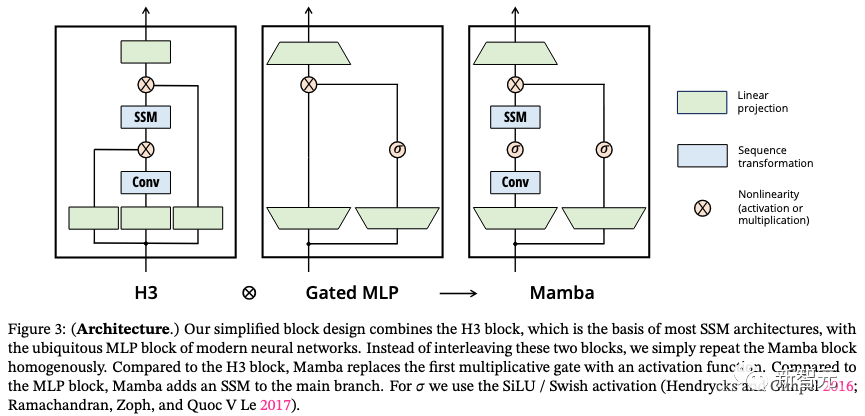
之所以这么处理是受到门控注意力单元(GAU)的启发。该架构涉及通过可控扩展因子来扩展模型维度。对于每个块,大多数参数(3ED^2)位于线性投影中,而内部SSM贡献较少。SSM参数的数量相比起来要小的多。
研究人员重复了这个块,与标准标准化和残差连接交织,形成Mamba架构。
在实验中,始终将x设为E=2,并使用块的两个堆栈来匹配Transformer交错MHA(多头注意力)和MLP块的122个参数。
研究人员使用SiLU / Swish激活函数,其动机是使门控 MLP 成为流行的「SwiGLU」变体 。最后,研究人员还使用了一个可选的归一化层,动机是RetNet在类似位置使用归一层。
选择机制是一个更广泛的概念,可以以不同的方式应用,例如更传统的RNN或CNN、不同的参数(例如算法2中的 A),或使用不同的变换。
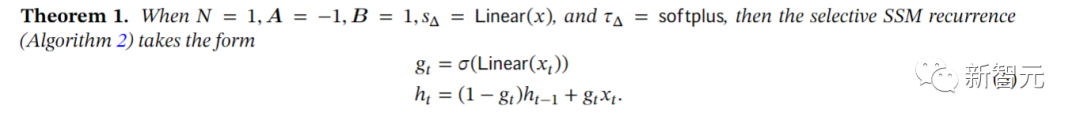
实证评估
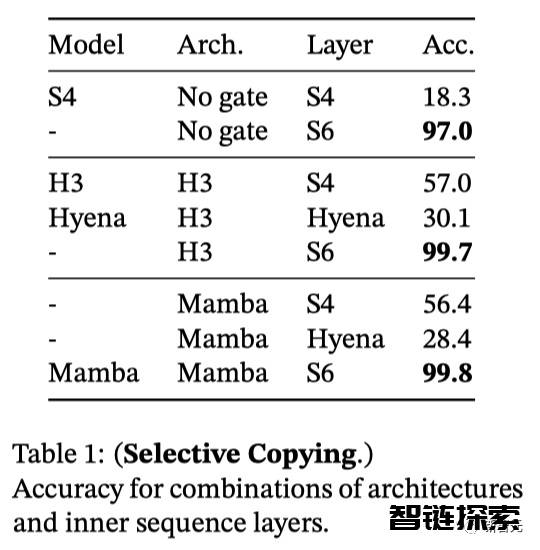
合成任务:选择性复制
复制任务是用来测试序列模型,特别是循环模型记忆能力的经典合成任务。
LTI SSM(线性递归和全局卷积)可以通过只关注时间而不是推理数据轻松地解决这个任务。例如,构建一个长度完全正确的卷积核(图2)。
对此,选择性复制任务则可以通过随机改变token的间距,来阻止这种走捷径的方法。
表1显示,H3和Mamba等门控架构只能部分提升性能,而选择机制(即将S4改进为S6)则可以轻松解决这一问题,尤其是与更强大的架构相结合时。
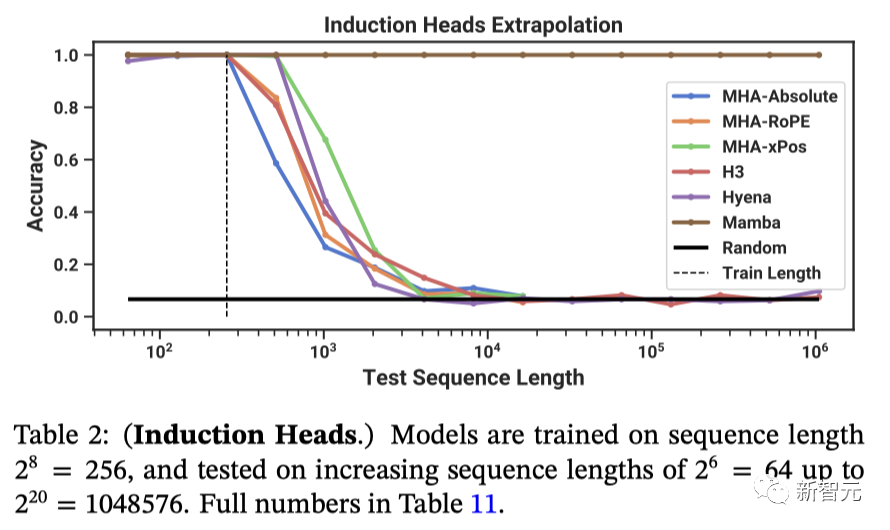
合成任务:归纳头
归纳头是一个从机械可解释性的角度出发相对简单的任务,却意外地能够预测大语言模型(LLMs)的上下文学习能力。
这项任务要求模型进行关联性回忆和复制动作:比如,模型之前在一个序列中遇到过「Harry Potter」这样的词组,那么当「Harry」再次出现在同一个序列时,模型应能够通过回顾历史信息并预测出「Potter」。
表2显示,Mamba模型,或者更准确地说是它的选择性SSM层,由于能够选择性地记住相关的token,同时忽略中间其他的token,因此能够完美地完成任务。
并且,它还能完美地泛化到百万长度的序列,也就是训练期间遇到的长度的4000倍。相比之下,其他方法的泛化能力都无法超过2倍。
语言建模
研究人员将Mamba与标准的Transformer架构(即GPT-3架构),以及目前最先进的Transformer(Transformer++)进行了对比。
后者基于PaLM和LLaMa架构,其特点包括旋转嵌入(rotary embedding)、SwiGLU MLP、使用RMSNorm替换LayerNorm、取消线性偏置,并采用更高的学习率。
图4显示,在从≈1.25亿到≈13亿的参数规模中,Mamba是首个在性能上媲美最强Transformer架构(Transformer++)的无注意力模型。
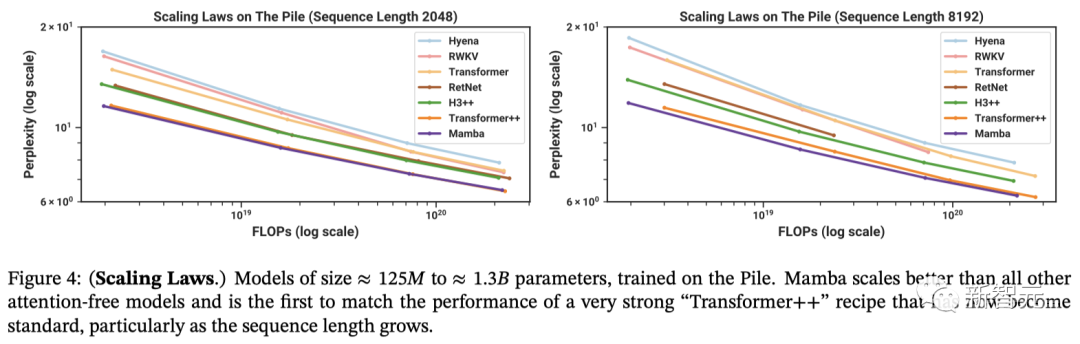
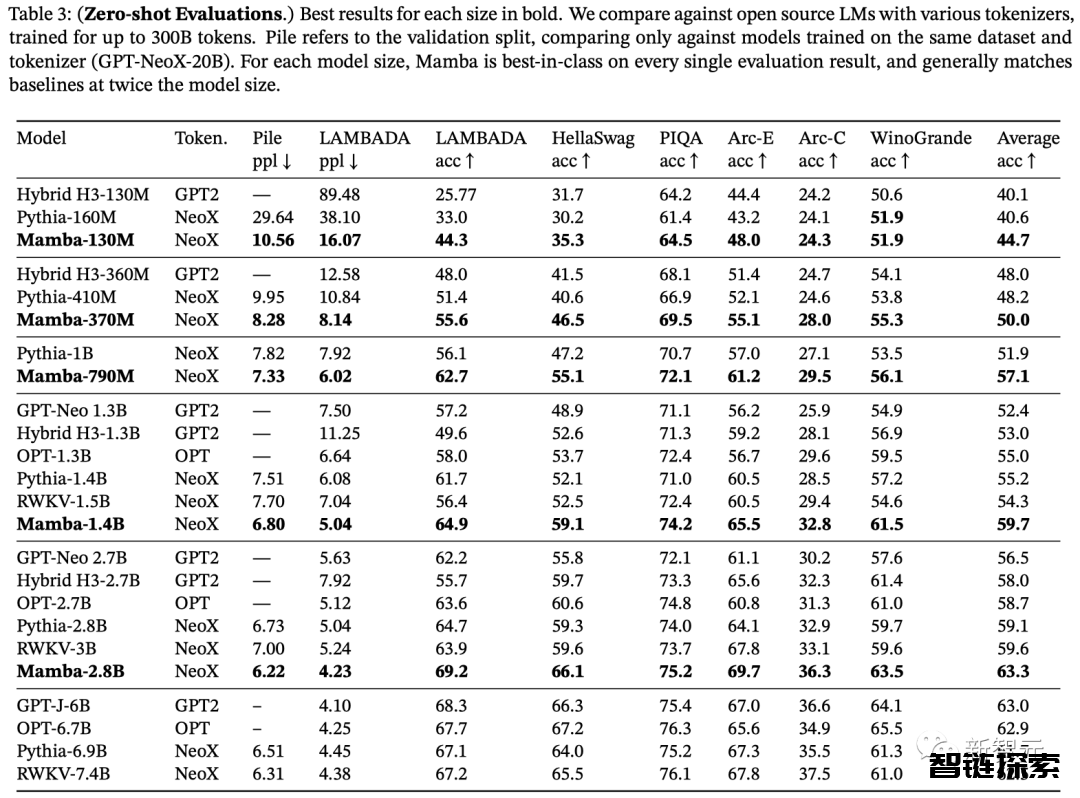
表3展示了Mamba在一系列下游zero-shot评估任务中的表现。
其中,Mamba在训练时使用了与Pythia和RWKV相同的tokenizer、数据集和训练长度(300B token)。
需要注意的是,Mamba和Pythia训练时的上下文长度为2048,而RWKV为1024。
DNA建模
随着大语言模型的成功,人们开始探索将基础模型的范式应用于基因组学。
DNA由具有特定词汇表的离散符号序列组成,还需要长程依赖关系来建模,因此被比作语言。
研究者将Mamba作为预训练和微调的FM骨干进行了研究,研究背景与最近DNA长序列模型的研究相同。
在预训练方面,研究者基本上按照标准的因果语言建模(下一个token预测)设置。
在数据集方面,基本沿用了鬣狗DNA的设置,它使用了HG38数据集进行预训练,该数据集由单个人类基因组组成,在训练分割中包含约45亿个token(DNA碱基对)。
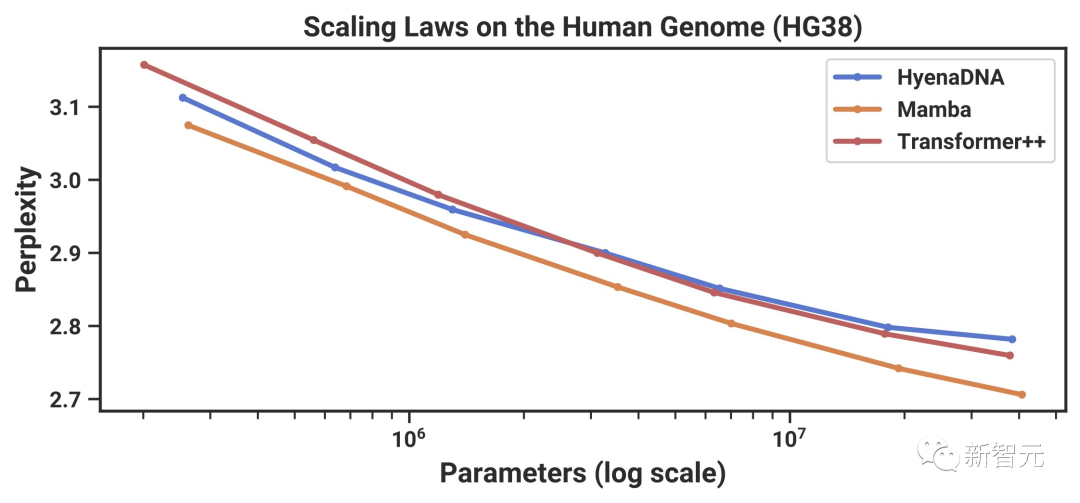
结果如图5(左)显示,Mamba的预训练困惑度随着模型规模的增大而平稳提高,并且Mamba的扩展能力优于 HvenaDNA和Transformer++。
例如,在最大模型规模≈40M参数时,曲线显示,Mamba可以用少3到4倍的参数,与Transformer++和HvenaDNA模型相媲美。
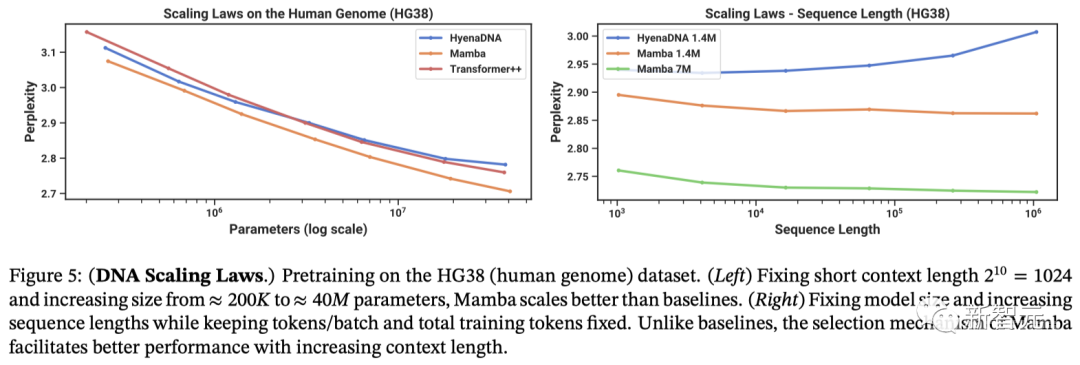
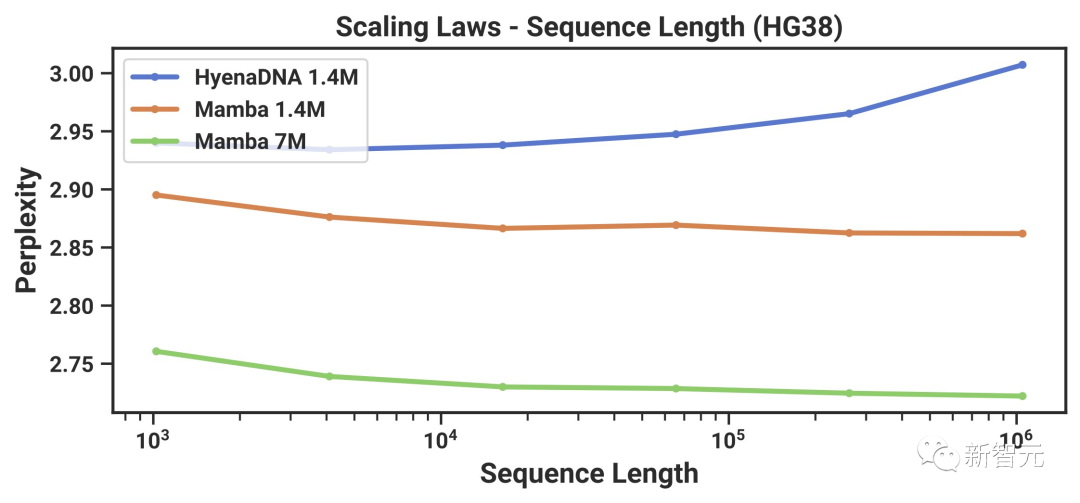
另外,图5(右)显示,Mamba能够利用更长的上下文,甚至长达1M的极长序列,并且其预训练困惑度会随着上下文的增加而提高。
另一方面,鬣狗DNA模型会随着序列长度的增加而变差。
从卷积的角度看,一个非常长的卷积核正在聚合一个长序列上的所有信息。
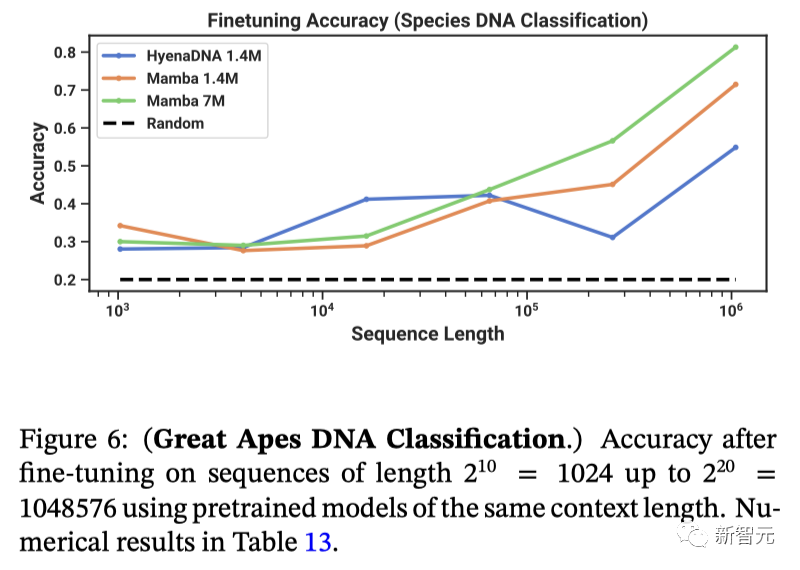
图6是类人猿DNA的分类,显示了使用相同上下文长度的预训练模型对长度2^10到2^20的序列进行微调后的准确度。
音频建模与生成
在音频波形处理领域,主要对比的是SaShiMi架构。该模型包括:
1. 一个U-Net主干,通过两个阶段的池化操作,其中每个阶段都将模型的维度D增加一倍,池化因子为p,
2. 每个阶段都交替使用S4和MLP模块。
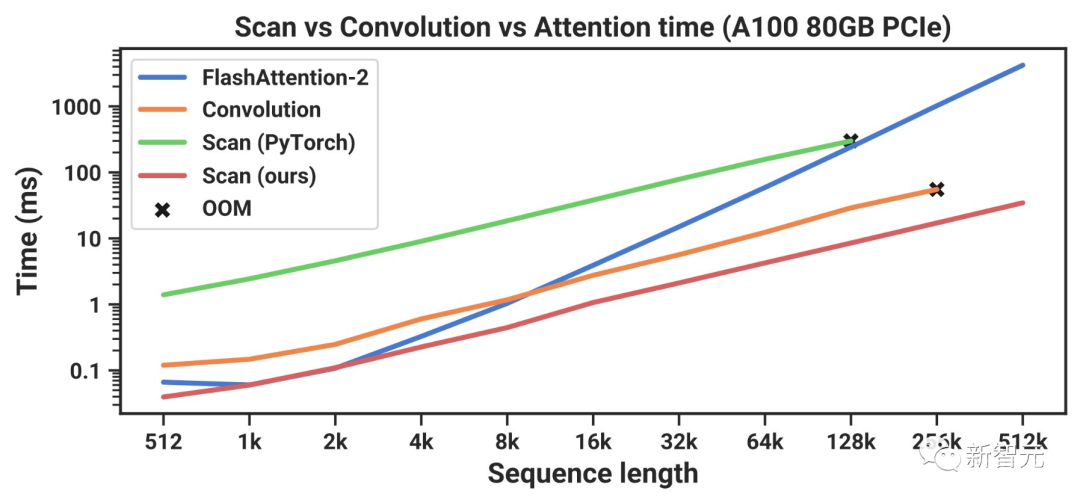
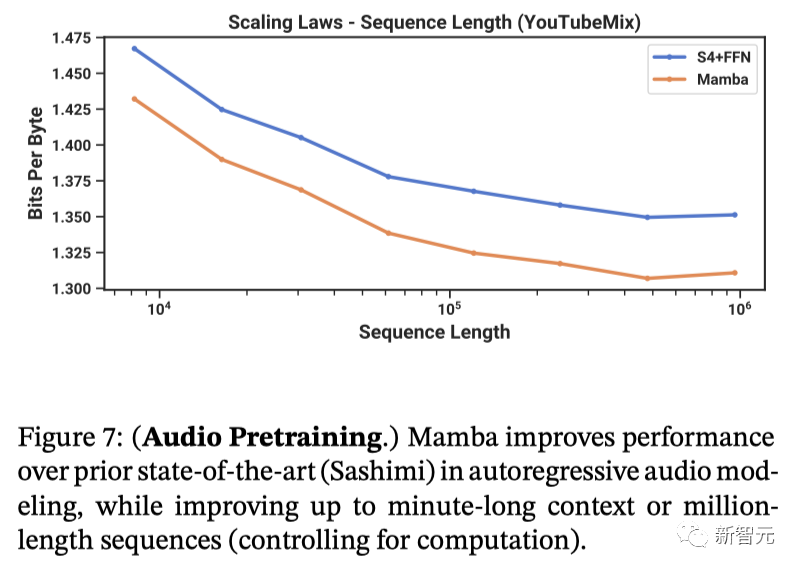
针对长上下文的自回归式预训练,研究人员采用了标准钢琴音乐数据集——YouTubeMix进行评估。数据集包含了4小时的独奏钢琴音乐,采样率为16000Hz。
图7展示了在保持计算量不变的情况下,训练序列长度从8192(2^13)增加到≈1000000(2^20)时的效果。
无论是Mamba还是SaShiMi(S4+MLP)基线模型,表现都随着上下文长度的增加而稳步提升。其中,Mamba在整个过程中都更胜一筹,而且序列越长优势越明显。
在自回归语音生成方面,则使用基准语音生成数据集SC09进行评估。它由时长1秒的语音片段组成,采样频率为16000 Hz,包含数字「0」到「9」,特征多变。
表4展示了Mamba-UNet与一系列基准模型的自动评估结果,其中包括WaveNet、SampleRNN、WaveGAN、DiffWave以及SaShiMi。
可以看到,小规模的Mamba模型在性能上就已经超越了那些更大、采用了最先进的基于GAN和扩散技术的模型。而同等参数规模的Mamba模型,在保真度方面的表现更是大幅领先。
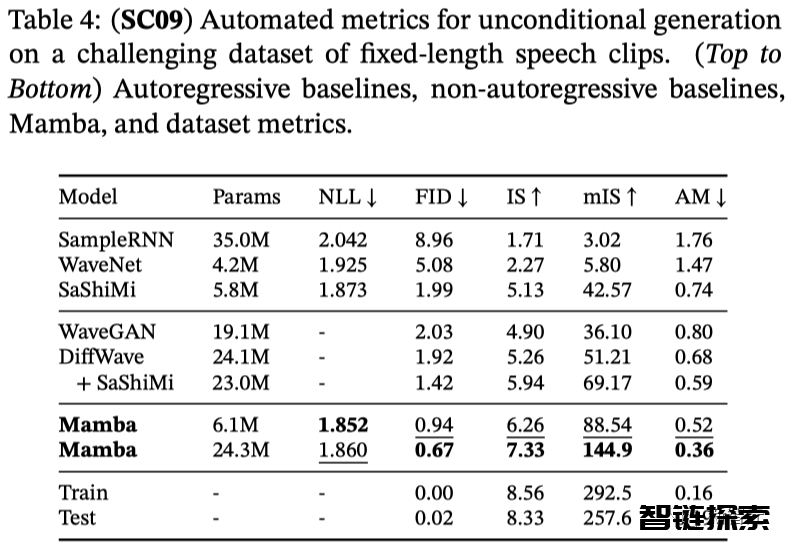
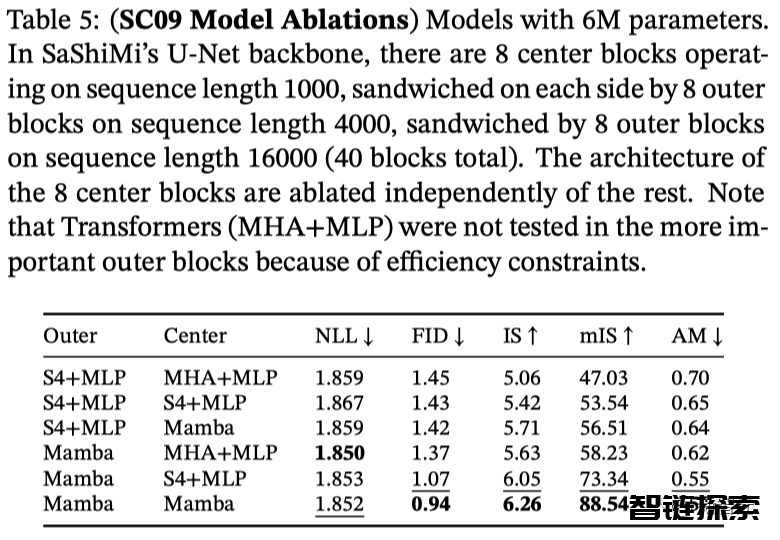
表5采用的是小规模Mamba模型,并探究了在外部和中心阶段不同架构的组合效果。
研究发现,无论在外部块还是中心块,Mamba模型的表现都优于S4+MLP架构,而在中心块的性能排名为Mamba > S4+MLP > MHA+MLP。
速度和显存基准测试
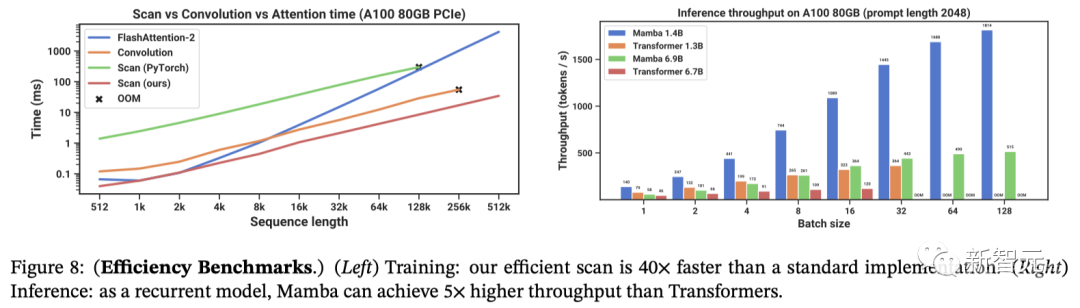
图8展示了scan操作(状态扩展N = 16)速度,以及Mamba端到端推理吞吐量的基准测试。
结果显示,当序列长度超过2k时,高效的SSM scan比目前最优秀的注意力机制——FlashAttention-2还要快。而且,比起PyTorch标准的scan实现,速度提升更是高达20到40倍。
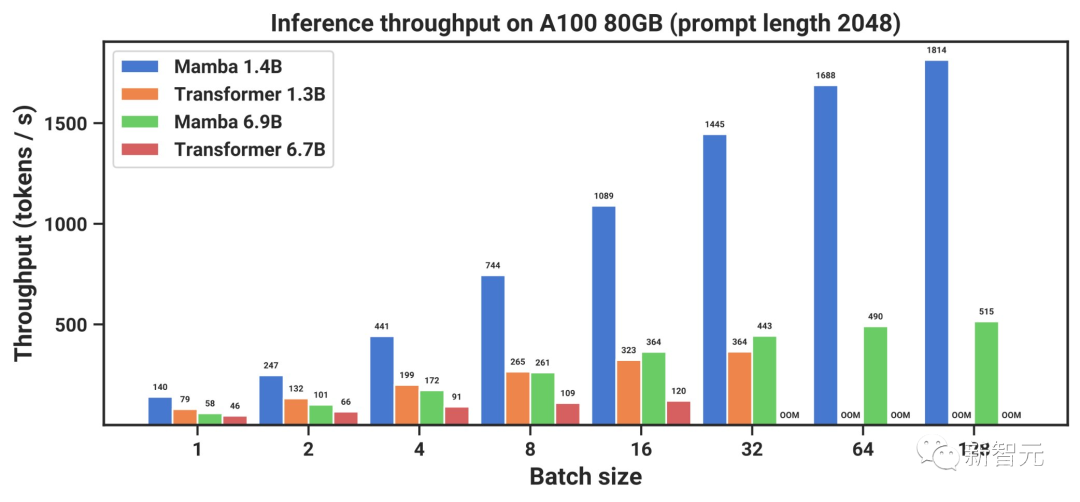
由于没有键值(KV)缓存,因此Mamba可以支持更大的批处理大小,从而使推理吞吐量比同等规模Transformer高了4到5倍。
举个例子,一个未经训练的69亿参数的Mamba(Mamba-6.9B),在推理处理能力上可以超过仅有13亿参数、规模小5倍的Transformer模型。
与大多数深度序列模型一样,显存使用量与激活张量的大小成正比。表15显示,Mamba的显存需求与经过优化的Transformer相当。

125M模型在单张A100 80GB GPU上训练时显存的需求
在论文最后,作者表示,选择性状态空间模型在为不同领域构建基础模的广泛应用性,太令人兴奋了。
种种实验结果表明,Mamba很有可能成为通用序列模型的主流框架,甚至有潜力跟Transformer一搏。




还没有评论,来说两句吧...