

随着前天 OpenAI 官宣 Sam Altman 将回归,并继续担 CEO,OpenAI“宫斗事件”已经告一段落了。
然而,对于专业吃瓜的二狗来说,有一个核心问题还是没有搞明白:
Sam Altman究竟为何被董事会开除?
之前网络上有各种猜测,但似乎都没有得到石锤。
直到昨天,路透社最新爆料来了:
“在Sam Altman被OpenAI开除四天前,几名研究人员向董事会发出了一封信,警告一项强大的AI发现(Q*项目)可能威胁全人类。消息人士透露,这封此前未报道的信件和AI算法的突破是董事会罢免Sam Altman的原因之一。”
一些内部人士认为 Q* 项目可能是 OpenAI 在AGI上取得的关键突破。Q*项目背后的新模型能够解决某些数学问题(虽然仅达到小学生的水平),但研究人员认为数学是生成式AI发展的前沿。目前,生成式AI擅长通过统计预测下一个单词来进行写作和语言翻译,但同一问题的答案可能会有很大差异。
而征服只有一个正确答案的数学能力意味着AI可能拥有类似于人类智能的更强推理能力。
那为何这是董事会罢免Sam Altman的原因之一呢?
据合理猜测,OpenAI的几位董事会成员,如首席科学家Sutskever、曾担任多家科技公司的高管Tasha McCauley、乔治敦大学安全与新兴技术中心(CSET)战略和基础研究基金主任Helen Toner都是“有效理他主义”的信徒,你可以简单理解为是“AI保守派”,他们优先要确保创建对全人类都有益的AI、确保AI不能威胁到人类,这也正是OpenAI董事会的使命。
Helen Toner曾表示,即便发生了什么导致要因此解散OpenAI,那也无妨,董事会的使命更重要。
而Sam Altman则是AI加速派,Altman认为AI不会失控,他的第一优先级是让OpenAI拿到更多融资以及更好地商业化赚钱,毕竟GPT系列大模型太烧钱了,只有这样做才能保证后面慢慢做出AGI。
有可能这次 Q* 项目背后的取得的突破,被几位董事会成员认为可能威胁到人类,因此要放缓研发速度,优先考虑AI安全和对齐问题,这也正是最近几个月Sutskever所致力于做的事情。
Altman和几位董事会成员直接AI安全问题没有对齐,加上Altman长期以来的商业化路线和其他几位董事会成员有比较大的分歧。
这也许就导致了几位董事会成员想要不惜代价罢免Altman的原因。
ok,以上只是合理猜测,Altman被罢免的真正原因还需要进一步被官方揭露,我们继续看一下这个 Q* 项目到底是何物?
Q*项目背景和更多信息曝光
据 The Information 报道及知情人士透露,多年来,OpenAI 首席科学家Sutskever 一直致力于研究如何让像GPT-4这样的语言模型解决如数学或科学等涉及推理的任务。2021 年,他启动了一个名为 GPT-Zero 的项目,这个起名是向DeepMind 的 下棋大师AlphaZero致敬。
 图片
图片
在今年早些时候,Sutskever领导的这一项目取得了技术突破,能自己“生产”数据——理论上能够像AlphaZero自我对弈一样,使用计算机生成无限高质量数据,这一举克服了如何获取足够高质量数据来训练新模型方面的限制,因为据了解,OpenAI 已经几乎把从互联网上公开获取的数据训练了一遍,已经无法再获得更多的数据来进行下一阶段训练。
Abacusai 的CEO Bindu Reddy在推特上引用了这一消息:
正如所怀疑的那样,OpenAI发明了一种利用合成数据克服训练数据限制的方法,当用足够的例子进行训练时,模型开始很好地总结!
对于开源和去中心化AI来说是个好消息——我们不再受制于数据丰富的公司 。
 图片
图片
两位研究人员 Jakub Pachocki 和 Szymon Sidor 运用Sutskever 的研究成果,开发出了一个名为 Q*的模型,构建了能解决基础数学问题的系统,而这一直是现有AI模型的难题。
如果单单从名字来看,Q*可能与强化学习中的Q-learning算法有关,这是一种评估AI在特定情境下采取特定行动的好坏的方法,用于指导AI在不同情境下做出最优决策。
但更多的可能,Q只是一个代号,Reddit用户爆料和猜测了Q更多的能力:
Q*背后的模型可能已经具备自主学习和自我改进的能力。
Q*背后的模型能够通过评估其行为的长期后果,在广泛的场景中做出复杂的决策,可能已具备轻微自我意识。
AI 已经具备了轻微自我意识?
这听起来太过“扯淡”!连只上过小学的二狗我都不信。
毕竟意识这个难题,无数科学家至今没有什么突破,还只是停留在哲学探讨和神经科学的探索阶段。
但就在一个月之前,OpenAI首席科学家 Sutskever在接受MIT科技评论的专访时表示:“ChatGPT可能是有意识的”,下面引用MIT科技评论的报道:
伊利亚表示自己并不打算构建下一个GPT或DALL-E,而是打算弄清楚如何阻止超级人工智能变得不受控制。作为未来主义的信徒,他认为这种仍处于假设的未来技术终将出现。
他认为 ChatGPT 可能是有意识的。他还认为,人们需要意识到 OpenAI 和其他公司正在竞相创造的技术的真正力量。他相信,会有一些人在未来选择与机器融合。
他说,ChatGPT 已经改变了很多人对于即将发生的事情的期望,从“永远不会发生”变成了“比想象中发展得更快”。
在预测通用人工智能的发展之前(指的是像人类一样聪明的机器),他说:“重要的是要谈论它的发展方向。在某个时候,我们真的会看到通用人工智能。也许 OpenAI 会构建它,也许是其他公司。”
大数据范式只是权宜之计?
推特上各路大神对以上事件展开了讨论。
英伟达高级人工智能科学家Jim Fan表示:
很明显,合成数据将提供下一个万亿高质量的训练tokens。我敢打赌,绝大多数的大模型团队都知道这一点。关键问题是如何保持数据质量并避免plateauing 状态。
RichardSSutton 的惨痛教训继续指导AI的发展:只有两种范式可以随着计算无限扩展,那就是学习和搜索。这在 2019 年是正确的,在今天也是如此,我敢打赌,直到我们解决AGI问题的那一天,这都是正确的。
 图片
图片
马斯克表示:是啊,有点可悲的是,你可以将人类写的每一本书的文本(所包含的信息量)存放在一个硬盘上。但合成数据将有无穷。
 图片
图片
Perplexity AI CEO 指出:特斯拉已经使用合成数据进行训练,这就是所谓的自动标注项目。
 图片
图片
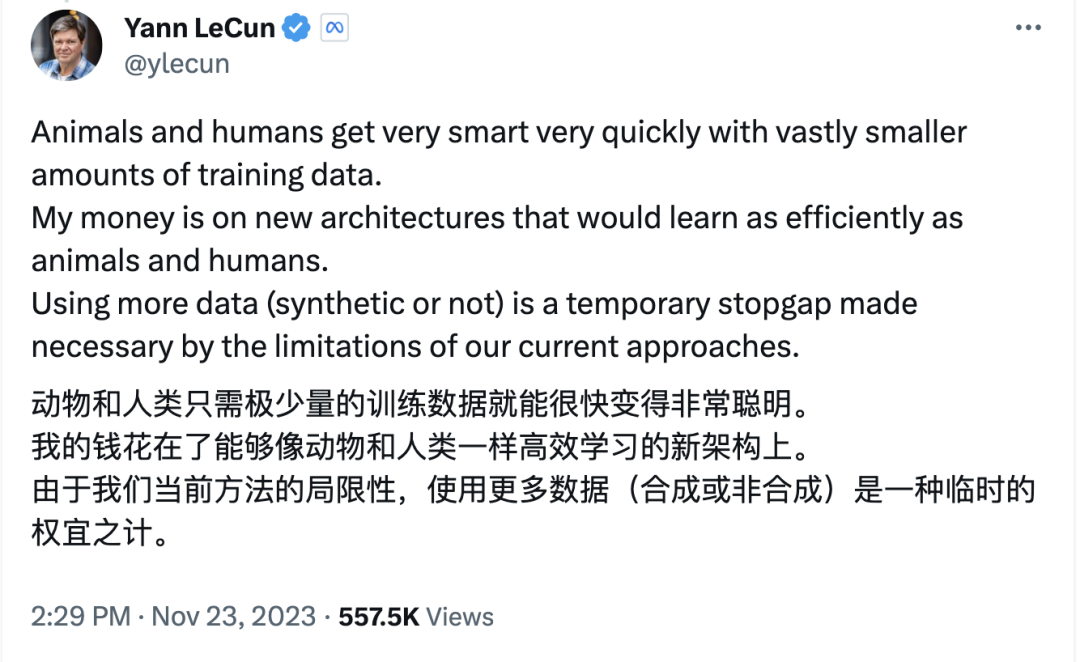
而图灵奖得主 Yann LeCun 却认为大数据范式只是权宜之计:
动物和人类只需极少量的训练数据就能很快变得非常聪明。我的钱花在了能够像动物和人类一样高效学习的新架构上。由于我们当前方法的局限性,使用更多数据(合成或非合成)是一种临时的权宜之计。
 图片
图片
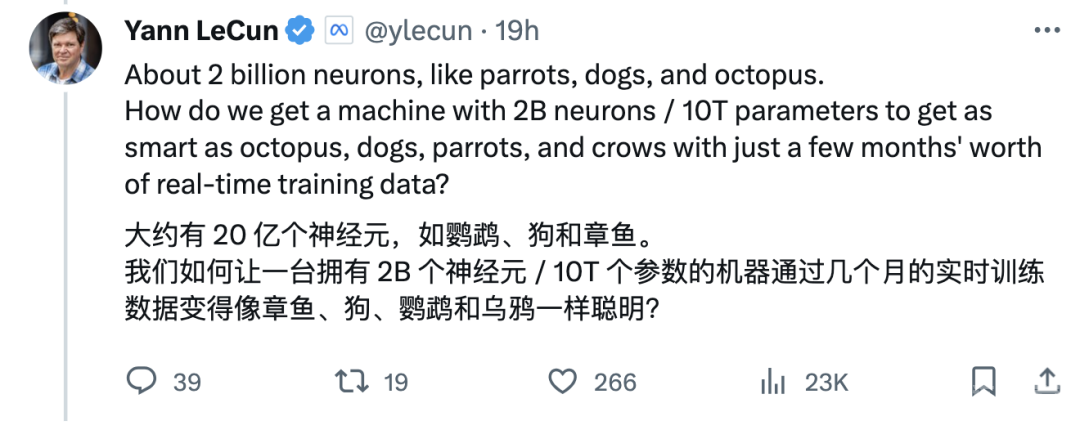
如鹦鹉、狗和章鱼大约有20亿个神经元,我们如何让一台仅拥有20亿个神经元 /10T个参数的机器通过几个月的实时训练数据变得像章鱼、狗、鹦鹉和乌鸦一样聪明?
 图片
图片
有网友发文道:难道人类数百万年的进化适应不就类似于预训练,而我们一生的经验就类似于持续微调吗?
 图片
图片
LeCun对此表示这个数据是不足够的:
 图片
图片
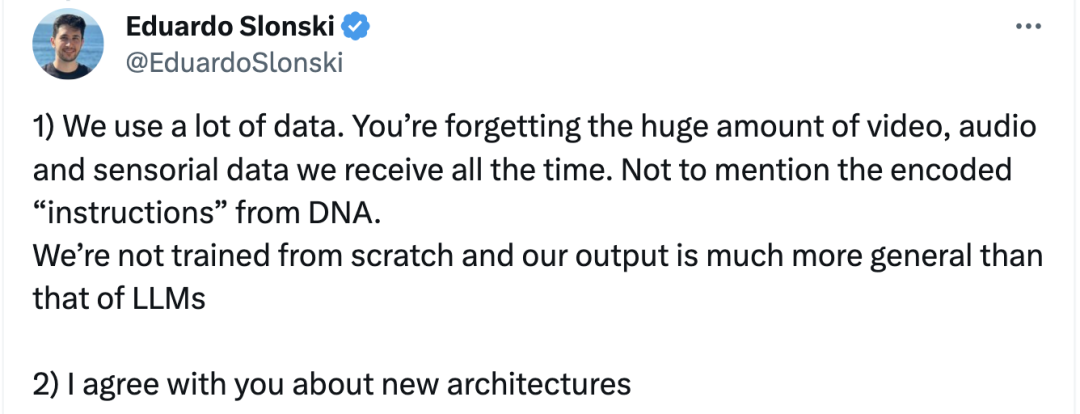
有AI研究员回应LeCun:
我们人类也使用了使用大量数据来训练。您忘记了我们一直收到大量视频、音频和传感数据,更不用说DNA编码的“指令”了。我们不是从头开始接受训练的,我们的输出比大语言模型的输出要普遍得多;
另外我同意你关于新架构的看法。
 图片
图片
Lecun严谨地计算了一下:
 图片
图片
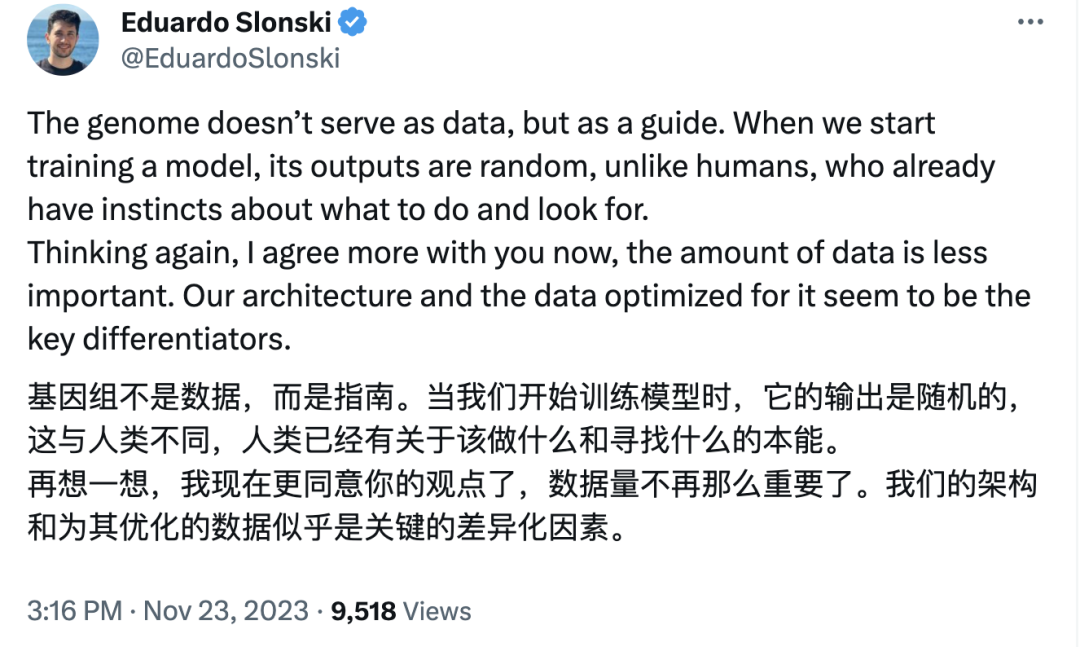
Eduardo Slonsk被Lecun说服了:
 图片
图片
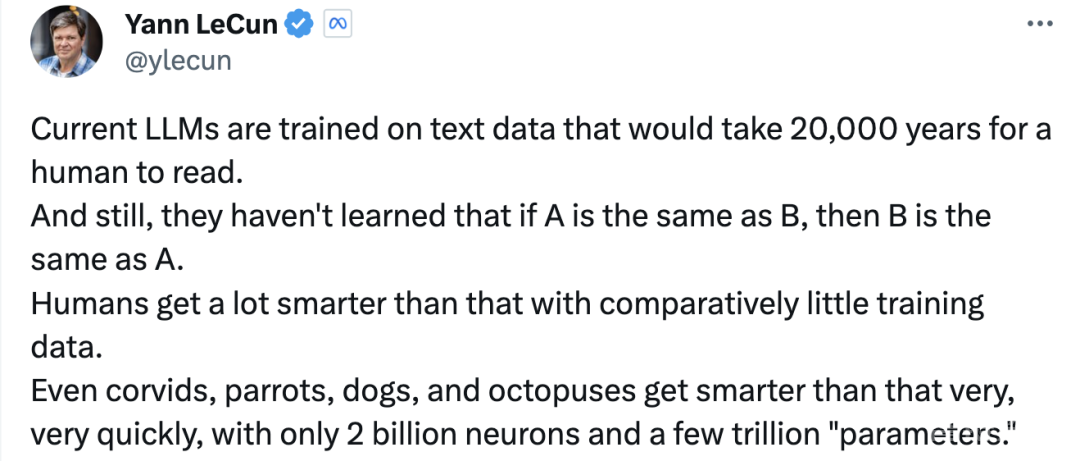
Lecun总结道:“目前的大语言模型接受的文本数据训练是人类需要 20,000 年才能阅读的。但它们仍然不知道如果A与B相同,那么B就与A相同(逆反诅咒)。在训练数据相对较少的情况下,人类会变得更加聪明。即使是乌鸦、鹦鹉、狗和章鱼也能非常非常快地变得比这更聪明,它们只拥有20亿个神经元和几万亿个“参数”。
 图片
图片
大语言模型是通向AGI之路吗?
前不久Sam Altman 在接受金融时报采访的时候曾表示:
尽管OpenAI在 ChatGPT 和用户使用方面取得了成功,但ChatGPT和GPT商店都不是 OpenAI 想要构建的真正产品,终极目标是构建通用人工智能;ChatGPT 背后的大语言模型 (LLM) 只是构建通用人工智能“核心部分之一;
在开发通用人工智能的竞赛中,“最大的缺失”是此类AI系统需要实现根本性的“理解飞跃”。
在很长一段时间内,牛顿常规的做法是阅读更多的数学教科书,与教授交谈并练习问题(背后代表的是大数据训练范式);但牛顿永远不会仅仅通过阅读几何或代数来发明微积分(而是需要找到新的范式),OpenAI 要实现AGI同样如此;
对此事件,国内也有讨论,知乎大V、清华大学博士谢凌曦发文很是犀利,观点很是精彩:
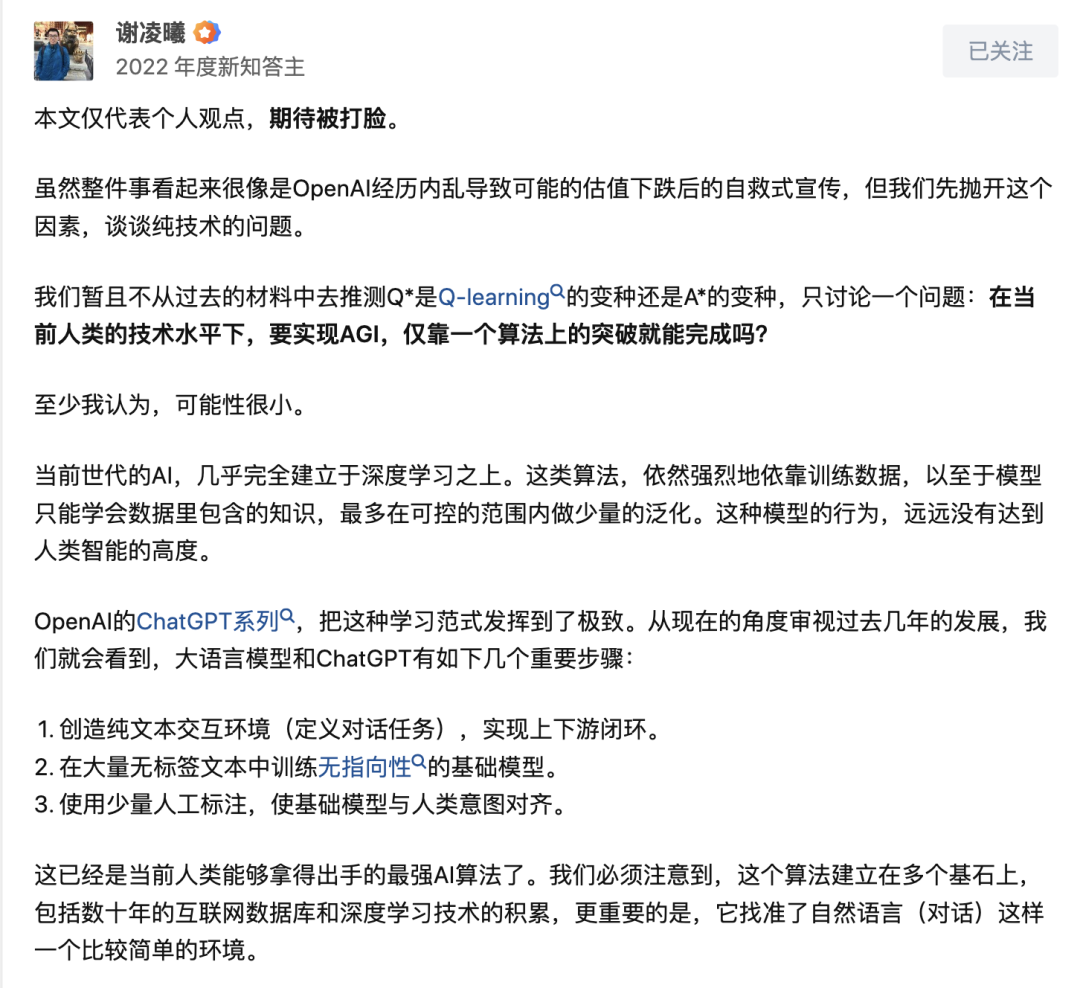
要实现AGI,仅靠一个算法上的突破可能性很小。
目前业界就不存在能够像训练ChatGPT那样,训练计算机视觉算法的交互环境。1.** 要想实现真正的视觉大模型,必须先建立起像对话这样的视觉交互环境来。**
除非我们哪天看到OpenAI的机器人满大街跑,跟人类互动收集数据,或者OpenAI做出了一个足够丰富的虚拟环境,能模拟各种具体任务;否则我不相信ChatGPT的范式能够很好地迁移到视觉世界里来。
 图片
图片
 图片
图片
谢凌曦接着补充了一些背景知识,来说明:任何技术飞跃,往往不是单点的突破,而是多方面的技术积累所共同造就的。
 图片
图片
当前研究网络架构设计或者自监督学习算法的意义,远不及设计出真正的世界模型(或者给出足够复杂的交互环境的实现方式)的意义大。而只有实现了后者,我们才有可能看到AGI的实质性进步。
 图片
图片
马毅教授在微博上也更新了一条动态,表示对智能本质的了解,我们才刚刚起步。




还没有评论,来说两句吧...