

OpenAI正忙着政变的时候,他们在硅谷最大的竞争对手Anthropic,则悄悄地搞了个大新闻——发布了支持200K上下文的Claude 2.1。

看得出来,Claude 2.1最大的升级就是将本就很强大的100K上下文能力,又提升了一倍!
200K的上下文不仅可以让用户更方便的处理更多的文档,而且模型出现幻觉的概率也缩小了2倍。同时,还支持系统提示词,以及小工具的使用等等。
而对于大多数普通用户来说,Claude最大的价值就是比GPT-4还强的上下文能力——可以很方便地把一些超过GPT-4上下文长度的长文档丢给Claude处理。
这样使得Claude不再是ChatGPT的下位选择,而成为了能力上和ChatGPT有所互补的另一个强大工具。
所以,Claude 2.1一发布,就网友上手实测,看看官方宣称的「200K」上下文能力到底有多强。

Claude 2.1 200K上下文大考:头尾最清楚,中间几乎记不住
本月初,当OpenAI发布了GPT-4 turbo的时候,技术大佬Greg Kamradt就对OpenAI的新模型进行了各方面的测试。
他把YC创始人Paul Graham文章的各个部位都添加了标记性的语句后喂给模型,然后来测试它读取这些语句的能力。
用几乎同样的方法,他对Claude 2.1也进行了上下文能力的压力测试。
2天时间全网阅读量超过110万
测试结果显示:
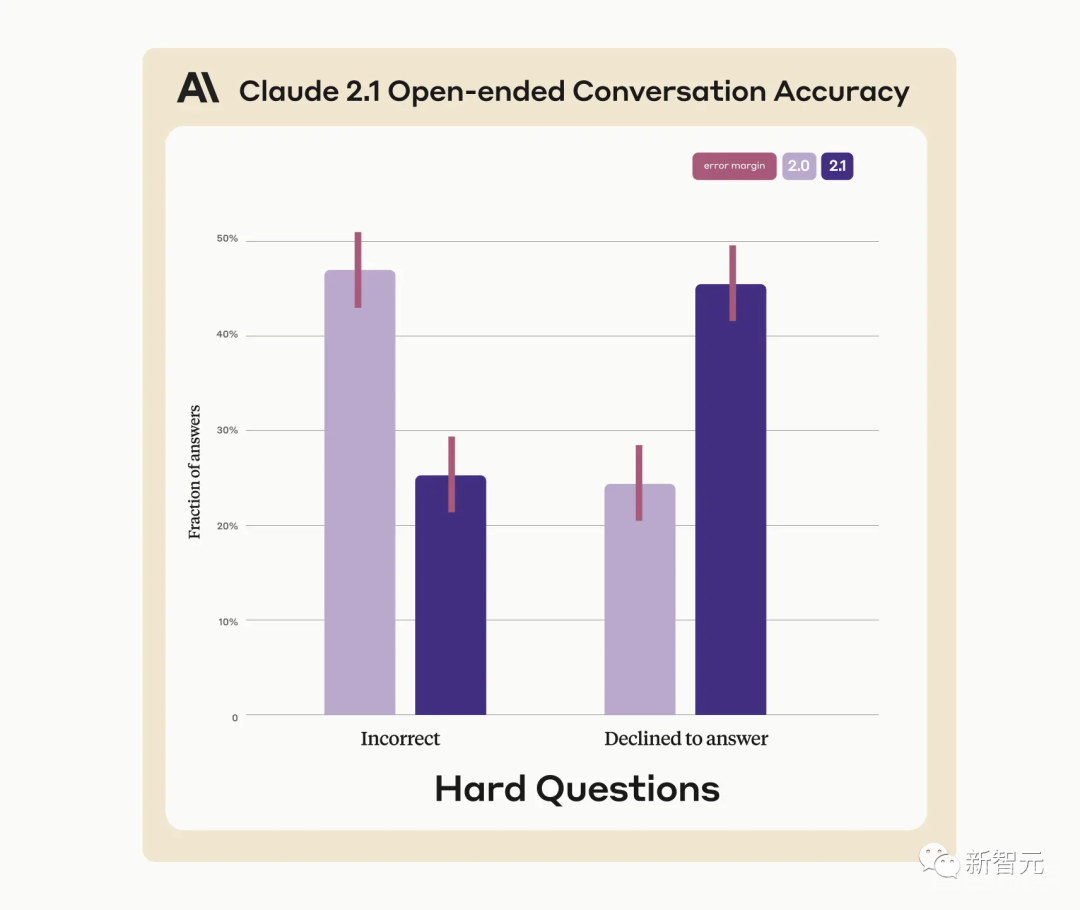
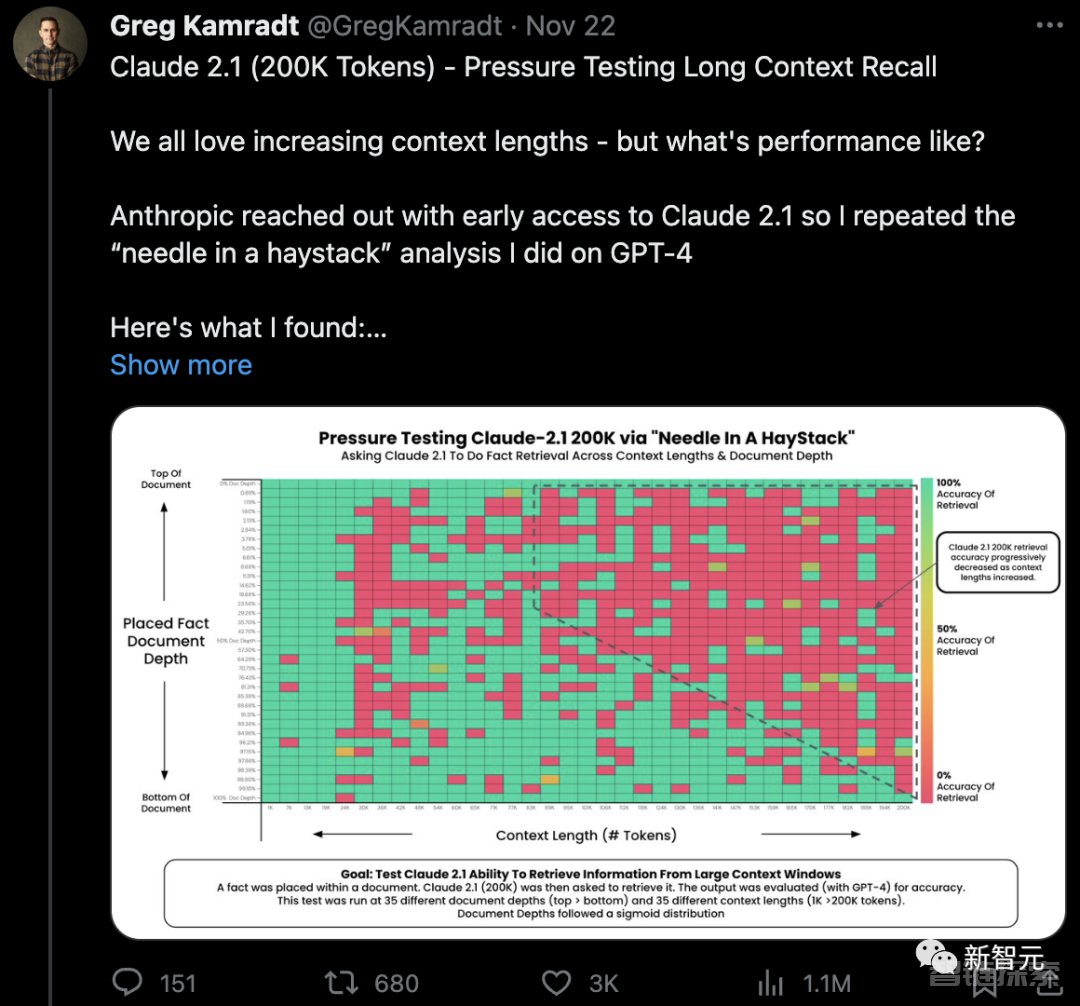
在官方标称的极限长度200K下,Claude 2.1确实有能力提取出标记性的语句。
位于文档开头的标记性内容,几乎都能被完整的获取到。
但和GPT-4 Turbo的情况类似,模型对文档开头内容的获取效果不如对文档底部内容的获取内容。

从90K长度开始,模型对文档底部标记性内容的获取能力就开始下降了。
从图中我们能看到,与GPT-4 128K测试结果相比,Claude 2.1 200K上下文长度,仅仅只是「在200K长度的文章中能读取到信息」。
而GPT-4 128K的情况是「在128K长度后出现明显下降」。

如果按照GPT-4 128K的质量标准,可能Claude 2.1大概只能宣称90K的上下文长度。
按照测试大神Greg说法,的这些测试结果表明:
用户在需要专门设计提示词,或者进行多次测试来衡量上下文检索的准确性。
应用开发者不能直接假设在这些上下文范围内的信息都能被检索到。
更少上下文长度的内容一般来说就代表着更高的检索能力,如果对检索质量要求比较高,就尽量减少喂给模型的上下文长度。
关键信息的位置很重要,开头结尾的信息更容易被记住。
而他也进一步解释了自己做这个对比测试的原因:
他不是为了黑Anthropic,他们的产品真的很棒,正在为所有人构建强大的AI工具。
他作为LLM从业人员,需要对模型的工作原理,优势和局限性有更多的了解和理解。
这些测试肯定也有不周到的地方,但可以帮中使用模型的用户更好的构建基于模型的服务,或者更加有效地使用模型能力。
而在做测试的过程中他还发现了一些细节:
模型能够回忆出的标记事实量很重要,模型在执行多个事实检索任务或综合推理步骤时会降低回忆事实的体量。
更改提示词,问题,以及要回忆的事实和背景上下文都会影响回忆的质量。
Anthropic团队在测试过程中也提供了很多帮助和建议,但这次测试调用API还是花了作者本人1016美元(每100万token的成本为8美元)。
自掏200刀,首测GPT-4 128K
在这个月初,OpenAI在开发者大会上发布GPT-4 Turbo时,也宣称扩大了上下文能力到128K。
当时,Greg Kamradt直接自掏200刀测了一波(单次输入128K token的成本为1.28美元)。
从趋势来看,和这次Anthropic的结果差不多:
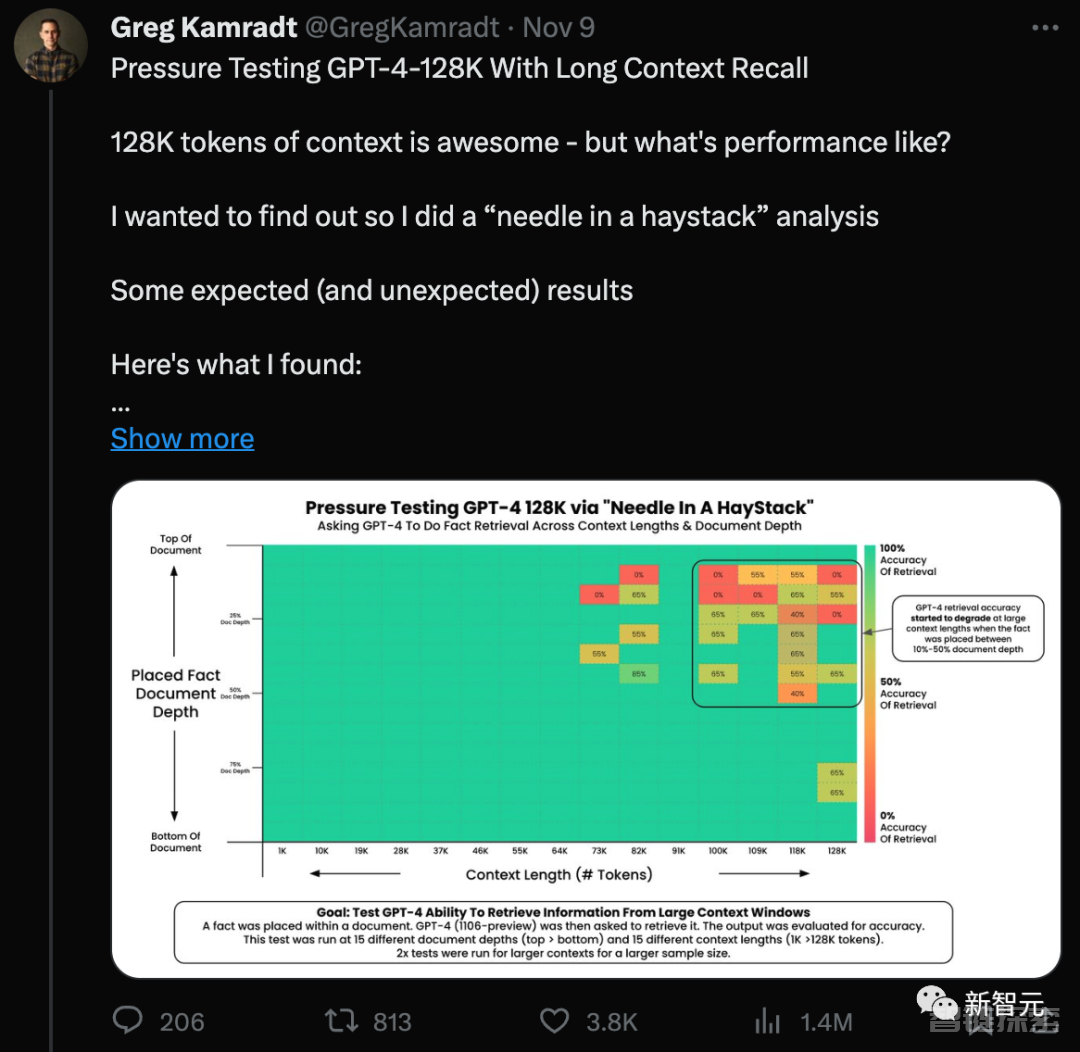
当上下文超过73K token时,GPT-4 的记忆性能开始下降。
如果需要回忆的事实位于文档的7%到50%深度之间,回忆效果通常较差。
如果事实位于文档开头,无论上下文长度如何,通常都能被成功回忆出来。
而整个测试的详细步骤包括:
利用Paul Graham的文章作为「背景」token。用了他的218篇文章,轻松达到200K token(重复使用了一些文章)。
在文档的不同深度插入一个随机陈述,称述的事实是:「在旧金山最棒的活动是在阳光灿烂的日子里,在多洛雷斯公园享用三明治。」
让GPT-4仅依靠提供的上下文来回答这个问题。
使用另一个模型(同样是 GPT-4)和@LangChainAI 的评估方法来评价GPT-4的回答。
针对15种不同的文档深度(从文档顶部的0%到底部的 100%)和15种不同的上下文长度(从1K token到128K token),重复上述步骤。




还没有评论,来说两句吧...