

摘要
本文探讨了如何利用大型语言模型和LangChain库来分析和抽取用户评论中的关键信息。文章首先描述了运营团队面临的挑战,即如何从大量的用户评论中获取有价值的数据。然后,介绍了使用LangChain的extraction chain和tagging chain来解决这一问题的具体步骤和代码实现。最后,文章还探讨了如何通过雷达图可视化用户反馈,以更直观地了解用户对产品或服务的感受。
开篇
你有没有遇到过这样的场景?公司的运营团队需要通过用户评论来了解一个新产品在市场上的接受程度,以便更好地制定未来的运营策略。爬取用户评论虽然容易但是抽取和分析数据却是个难题。
在大型语言模型之前,数据分析依赖于基础统计、手工标签和简单机器学习模型。这些方法不仅耗时耗力,还需要专业工具和复杂的规则维护。因此,分析大规模或非结构化数据往往效果有限。处理用户评论这样非结构化的数据,为大型语言模型的应用提供了广阔的舞台。
需求背景
在当前的商业环境下,用户评论已经成为了衡量产品或服务质量的重要指标。运营团队经常需要依赖这些信息来调整产品特性或优化营销策略。但是,如何从大量的用户评论中提取有用信息,然后将这些信息转化为可行的战略,仍然是一个挑战。
我们拿一些用户评论的例子分析一下,我们从网络爬取了一些用户的评论信息,从信息上可以看出用户针对手机产品的一些特性进行了评论,包括摄像头,屏幕,性能等。在评论内容中还带有一些用户的个人感情,例如:客服给力,非常满意等等。
最直接的想法就是从这些评论中把关于商品的部分抽取出来,看看大家对我们的产品认可程度如何。
抽取产品信息
既然目标是了解用户对产品的看法,就先从产品下手。关于信息抽取, LangChain集成了OpenAI的extraction 功能,并且将其封装成了一个Chain如下。
这里对这个类稍微做一下解释。
通过create_extraction_chain创建一个chain,用来信息的抽取,输入的参数如下:
Schema:这是一个字典,描述了需要从文本中提取哪些实体。
Llm:语言模型实例。
Prompt:提示模板,用于生成模型输入。
Verbose:是否在控制台打印中间日志。
返回值是一个 Chain 对象,该对象可以用于从文本中提取信息。
在参数中schema很重要,我们需要定义抽取信息的属性值。
程序设计
有了基本思路,查找了功能实现以后,我们可以根据这个功能设计一下应用程序。如下图所示,用户请求的时候会将用户评论的信息给到应用程序。应用程序利用LangChain中extraction chain 调用大模型抽取用户评论中关于商品信息的描述,在抽取过程中它会依赖schema文件,这个文件会定义哪些商品属性需要进行抽取。
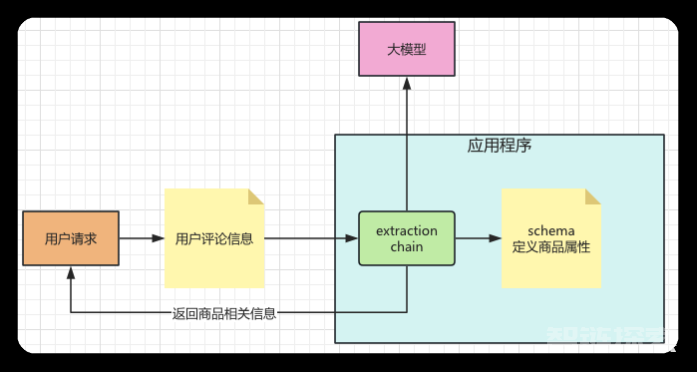
由于LangChain中extraction chain的功能支持openai的模型,因此我们选择GPT-3.5的版本。接着就是如何定义Schema的问题了。 schema中定义的是商品属性信息,如果运营小妹来提这个需求一定是越多越好,不过通过对用户评论的分析,和运营小妹一顿周旋之后,我们把schema的属性定义如下:
主要在电池,摄像头,屏幕,手感,流畅度,外观和品牌上。
商品信息抽取:代码实现
有了业务需求加设计思路,就可以撸代码了。为了方便给大家展示,这里的用户评论信息,我们放到了inp变量中保存,一般而言应该是从网络爬取之后保存到本地文件或者是数据库中。然后,再读取使用,我们这里简化了过程,将关注点放到如何使用大模型和LangChain上面。
代码不复杂,这里简单解释一下:
1. 定义提取模式(Schema): 使用一个名为 `schema` 的字典来定义我们希望从用户评论中提取哪些信息。这里包括用户名、电池、摄像头等多个维度。
2. 初始化自然语言模型: 创建一个名为 `llm` 的 `ChatOpenAI` 对象,这是 GPT-3.5-turbo 模型的一个封装。这个对象将负责后续的文本生成和理解。
3. 创建信息提取链: 使用 `create_extraction_chain` 函数,结合之前定义的 `schema` 和初始化的模型 `llm`,生成一个信息提取链,存储为 `chain` 变量。
4. 运行信息提取: 最后,使用 `chain.run(inp)` 方法运行这个信息提取链,它将分析输入的用户评论(存储在 `inp` 变量中)并将结果保存在 `results` 变量中。
Results的输出结果如下:
看!简单四步搞定数据分析,运营小妹看了直拍手,不过仔细看看,用户的情感似乎没有在输出中体现出来。
需求变更
能够获取商品的信息固然是不错,但是如果能够将用户的情感信息也一并抽取出来就完美了,既然运营小妹有需求,程序员就有办法。
实际上用户的情感,是对产品和服务而言的,综合“借鉴”了其他系统的用户服务满意表,得出如下维度是我们需要关注的:满意度,商品质量,性价比,用户体验,客户服务,推荐意愿,功能完整性,交付速度,可靠性,可行话需求满足度。一般对这些服务都会进行评分,什么 “非常满意”,“满意”,“一般”等等,分了很多级别。这种功能好像extraction chain 就不能实现了,不要紧程序员有办法,通过对langchainapi的翻找,找到了tagging chain这个类。
代码还是老套路,我们依旧需要定义shcema,告诉大模型我们要抽取的数据类型。
程序再设计
有了需求思路,也能够通过技术实现,接着我们把设计稍微调整一下。如下图所示,和extraction chain组件一样,我们加入了tagging chain组件,他们之间是平行关系,都需要接受用户传入的用户评论信息,同时利用schema定义的属性,调用大模型完成信息的抽取。
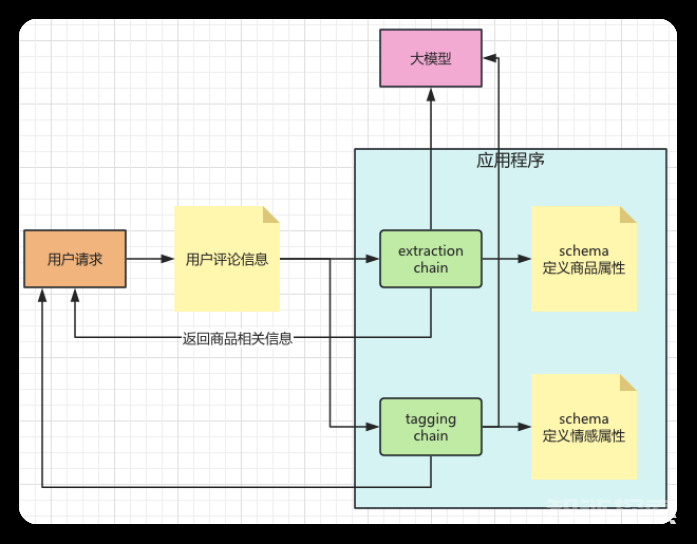
情感信息抽取:代码实现
程序设计比较简单,程序员小哥离胜利更进一步了。快点开始撸代码吧,今天下班还有约会!
代码依旧是熟悉的配方,显然小哥已经轻车熟路了。
1.导入依赖库:导入了 `ChatOpenAI`、`ChatPromptTemplate`、`create_tagging_chain` 和 `create_tagging_chain_pydantic` 等所需库和函数。
2.定义标记模式(Schema):使用 `schema` 变量定义了需要从用户评论中标记的信息,这里包括了满意度、产品质量、性价比等多个维度。
3.初始化自然语言模型:创建了一个名为 `llm` 的 `ChatOpenAI` 对象,用于后续的文本生成和理解任务。
4.创建标记链:使用 `create_tagging_chain` 函数和之前定义的 `schema` 及初始化的 `llm` 对象,生成了一个信息标记链,存储为 `chain` 变量。
5.获取用户评论:从 `inp` 变量中提取单个用户的评论,并存储在 `user_comments` 列表中。
6.初始化结果存储:创建了一个名为 `tagged_results` 的空字典,用于保存每个用户的标记结果。
7.循环标记用户评论:遍历每个用户的评论,使用 `chain.run()` 方法运行标记链,然后将标记结果保存到 `tagged_results` 字典中。
8.输出标记结果:最后,遍历 `tagged_results` 字典,将每个用户的标记结果格式化为字符串并输出。
输出内容如下:
从内容上虽然可以看到每个用户对产品和服务的态度,但是运营小妹提出了要求,需要进行一些统计帮助运营进行用户的区分。例如:非常满意的用户占比是多少,感觉产品质量优秀的用户占比等等。
这难不倒小哥,继续加代码:
输出如下:
看看需求轻松搞定,看来可以按时下班了。
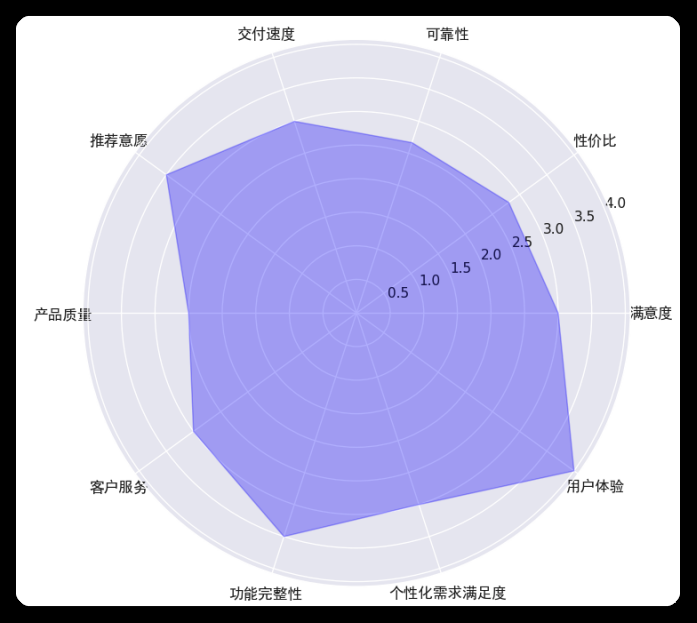
生成评论数据的雷达图
运营小妹见程序员小哥这么快完成了功能,觉得没有难度于是提出,是否能够将用户的反馈数据通过雷达图的方式展示。程序员小哥,突然“由喜转悲”心中一万个草泥马在奔腾,不过精心一想,雷达图不同的顶点代表不同的情感维度,每个用户的反馈按照等级给一个分数,然后将分数平均以后得到的值就可以代表某个维度的最终显示值了。这么一想瞬间通透了,代码呼之欲出:
虽然代码简单,但是小哥担心大家不懂,还是“画蛇添足”地给出了解释。
1.导入依赖库:导入了 Pandas、Matplotlib 和 NumPy 等库,以及一些字体设置的工具。
2.从字典到 DataFrame:使用 `pd.DataFrame.from_dict()` 将 `tagged_results` 字典转化为 Pandas DataFrame,这样更便于后续的数据处理。
3.定义标签到数值的映射:创建了一个名为 `mapping` 的字典,用于将用户反馈的标签(如 "非常满意"、"满意" 等)映射到数值。
4.标签转换为数值:遍历 DataFrame 的每一列,使用 `map()` 函数将所有的标签转换为对应的数值。
5.计算平均得分:对 DataFrame 的每一列(即每一个属性)计算平均得分,并保存在 `averages` 变量中。
6.雷达图准备:设置雷达图的各个顶点标签(即 `attributes`),并计算每个顶点对应的角度。
7.角度和平均得分:计算每个属性对应的角度,并确保雷达图是一个封闭的形状。同时,对 `averages` 列表进行操作以确保雷达图的封闭。
8.设置字体:使用 `FontProperties` 来设置字体,确保中文能够正确显示。
9.绘制雷达图:使用 Matplotlib 的 `subplot` 和其他函数来绘制雷达图。设置了图的大小、颜色、透明度等。
10.设置标题和标签:最后,添加了标题并设置了各个轴的标签。
雷达图展示结果:
总结
运用大型语言模型和LangChain库,我们不仅可以高效地从用户评论中抽取产品相关信息,还可以获取到用户的情感反馈。这一整套方案大大简化了传统的数据分析过程,减少了人工标签和复杂规则维护的需要。通过进一步的数据可视化,运营团队可以更容易地理解用户需求和感受,从而更精准地调整产品特性和营销策略。这不仅提高了数据分析的准确性,也极大地提升了工作效率。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。




还没有评论,来说两句吧...