

H100再次在MLPerf中刷新了记录!
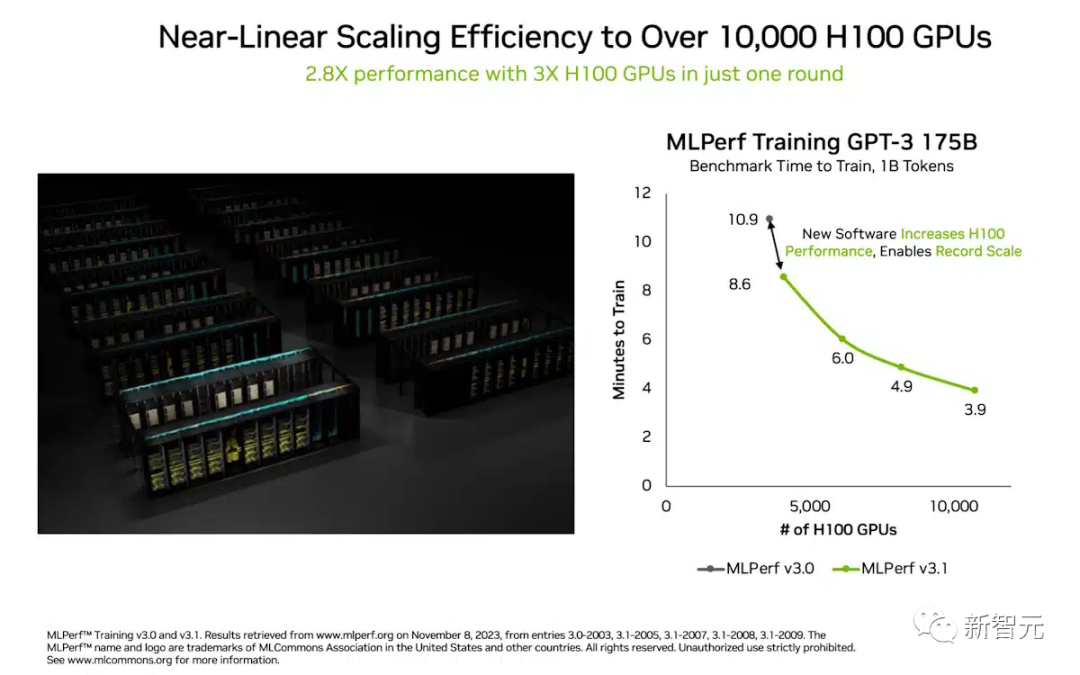
英伟达超算NVIDIA Eos在GPT-3模型的基准测试中,只用了3.9分钟就完成了训练。
这比6月份的刷新记录的成绩——10.9分钟,提升了近3倍。
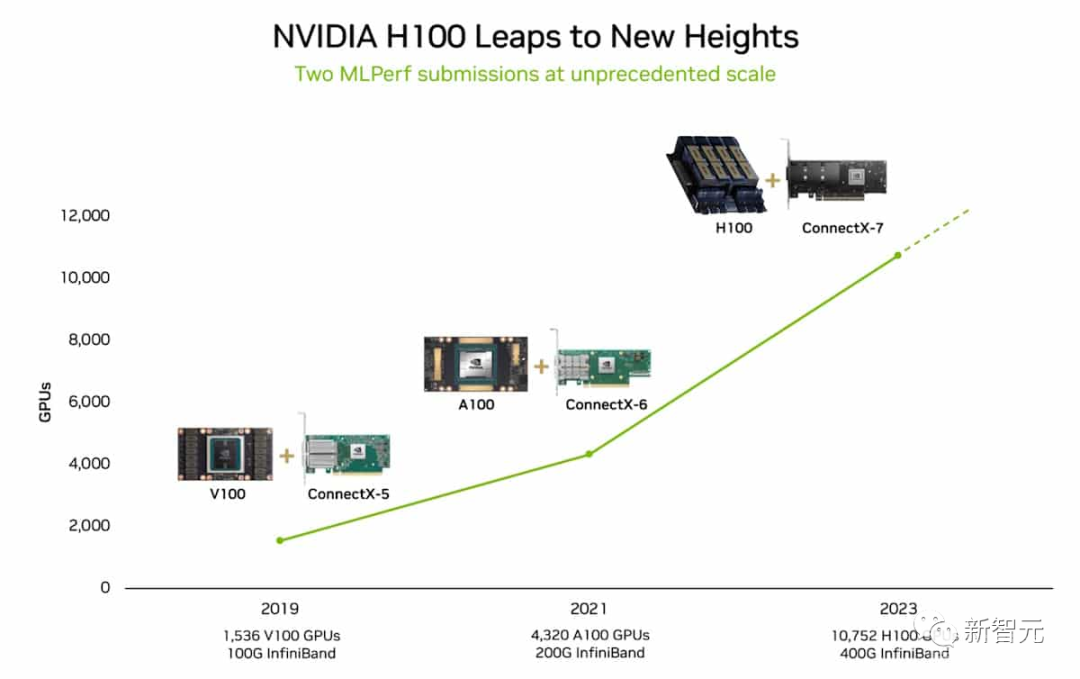
Eos使用了多达10,752个H100和NVIDIA Quantum-2 InfiniBand网络互连。
通过推算,Eos现在可以在短短8天内进行训练,比之前使用512个A100 GPU的先进系统快73倍。
在本轮新的生成式AI测试中,1,024个NVIDIA Hopper架构GPU在2.5分钟内完成了基于Stable Diffusion文本到图像模型的训练基准测试,为这一新工作负载设定了高标准。
与此同时,外媒曝光了英伟达为应对新规而打造的全新「特供版」芯片——H20、L20和L2。
系统扩展效率飙升93%
最新的结果部分是由于使用了有史以来应用于MLPerf基准测试的最多加速器。
10,752个H100 GPU远远超过了6月份AI训练的规模,当时英伟达使用了3,584个Hopper GPU。

GPU数量扩展3倍,性能扩展了2.8倍,效率达到93%,这在一定程度上要归功于软件优化。
高效扩展是生成式AI的关键要求,因为LLM每年都在以一个数量级的速度增长。
最新结果显示,即使是世界上最大的数据中心,英伟达也有能力应对这一前所未有的挑战。
这一成就归功于加速器、系统和软件创新的全栈平台,Eos和Microsoft Azure在最近一轮测试中都使用了该平台。
Eos和Azure在各自的提交中都采用了10,752个H100。它们的表现相差不到2%,展示了英伟达AI在数据中心和公有云部署中的高效性。

英伟达依靠Eos完成了各种关键任务。
它有助于推进NVIDIA DLSS和ChipNeMo等计划,后者是帮助设计下一代GPU的生成式AI工具。

9项基准测试,刷新记录
除了在生成式AI方面取得进步,英伟达在这一轮测试中还刷新了几项新的记录。
比如,在训练推荐系统模型的测试中,H100 GPU比上一轮快了1.6倍。在计算机视觉模型RetinaNet的测试中,性能提高了1.8倍。
这些性能提升来源于软件和硬件规模扩充的优化结合。
英伟达再次成为唯一一家完成了所有MLPerf测试的公司。H100在9项基准测试中展示了最快的性能和最大的扩展性。

这些加速为用户训练大模型或用NeMo等框架自定义模型以满足业务需求,带来了更快上市时间、更低成本和节省能源。
这一轮测试中,包括华硕、戴尔技术、富士通、技嘉、联想、QCT和超微等11家系统制造商在提交结果中使用了NVIDIA AI平台。
特供版H20、L20和L2性能曝光
在过去几年中,美国对高性能硬件出口实施了非常严格的限制。
尤其是在2023年11月生效的新规,更是要求所有达到一定总处理性能和/或性能密度的硬件都必须获得出口许可。
据最新泄露的文件和四位熟悉内情的人士透露,为了遵守美国的出口管制,英伟达已经推出了三款全新的「中国定制版」芯片——HGX H20、L20 PCle 和 L2 PCle GPU。
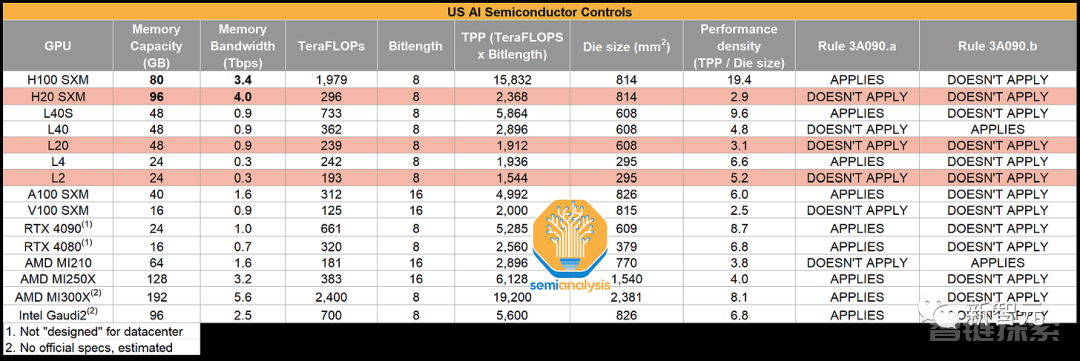
其中,HGX H20配有高达96GB的HBM3显存,以及4TB/s的带宽,并且基于全新的Hopper架构。
与H100的50MB二级缓存相比,H20还拥有更大的60MB二级缓存。
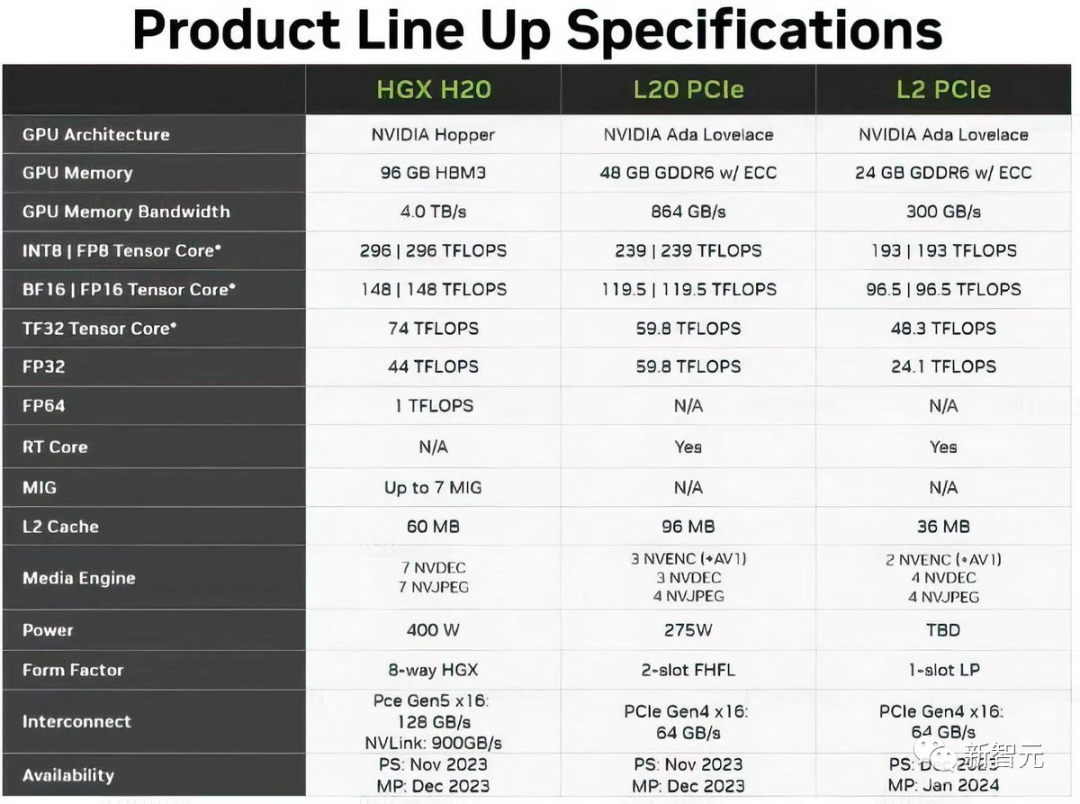
然而在性能方面,HGX H20只能提供FP64精度1 TFLOPS(H100为34 TFLOPS)和FP16/BF16精度148 TFLOPS(H100为1,979 TFLOPS)的算力。
由此,功耗也从700W降到了400W。
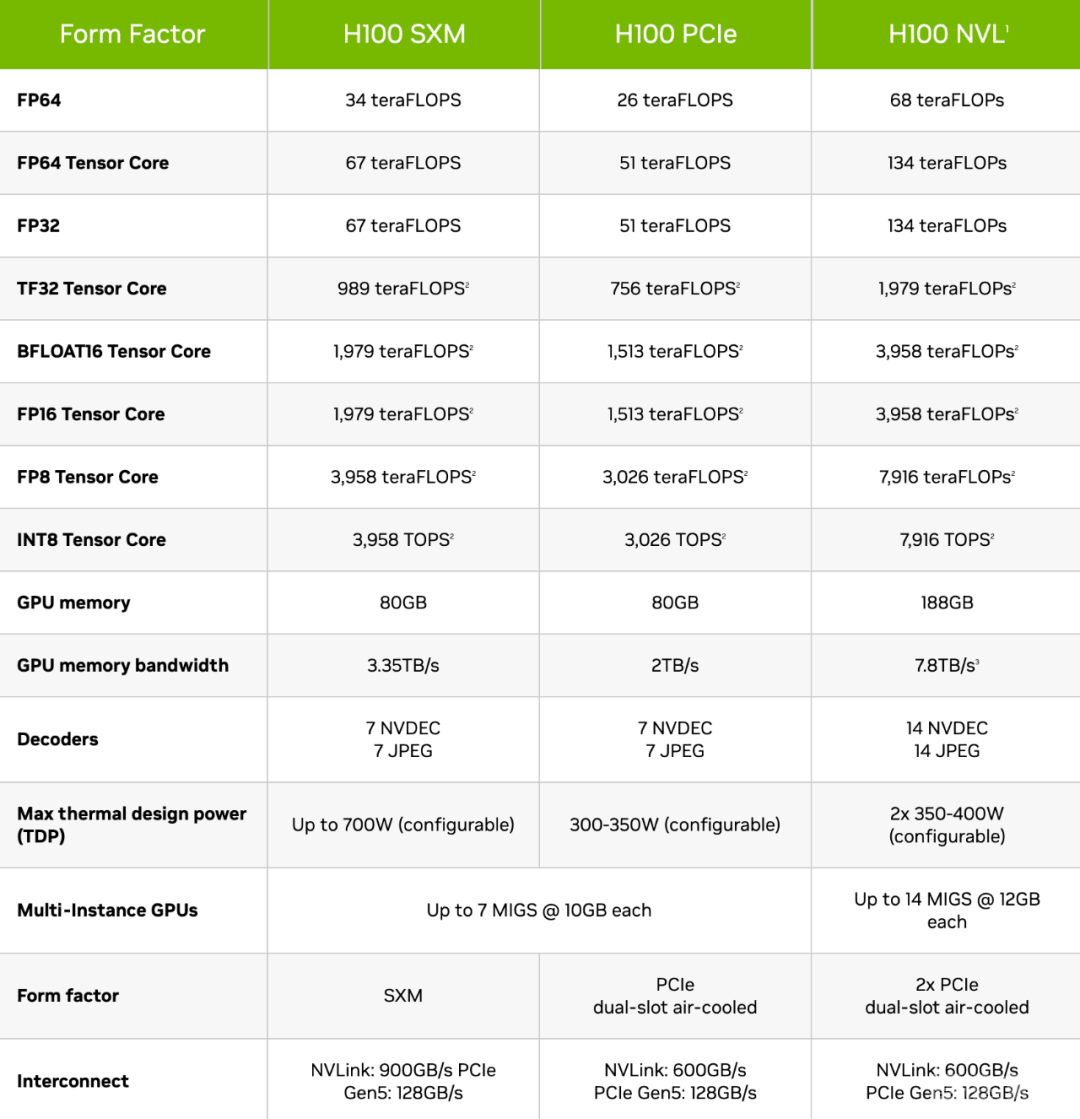
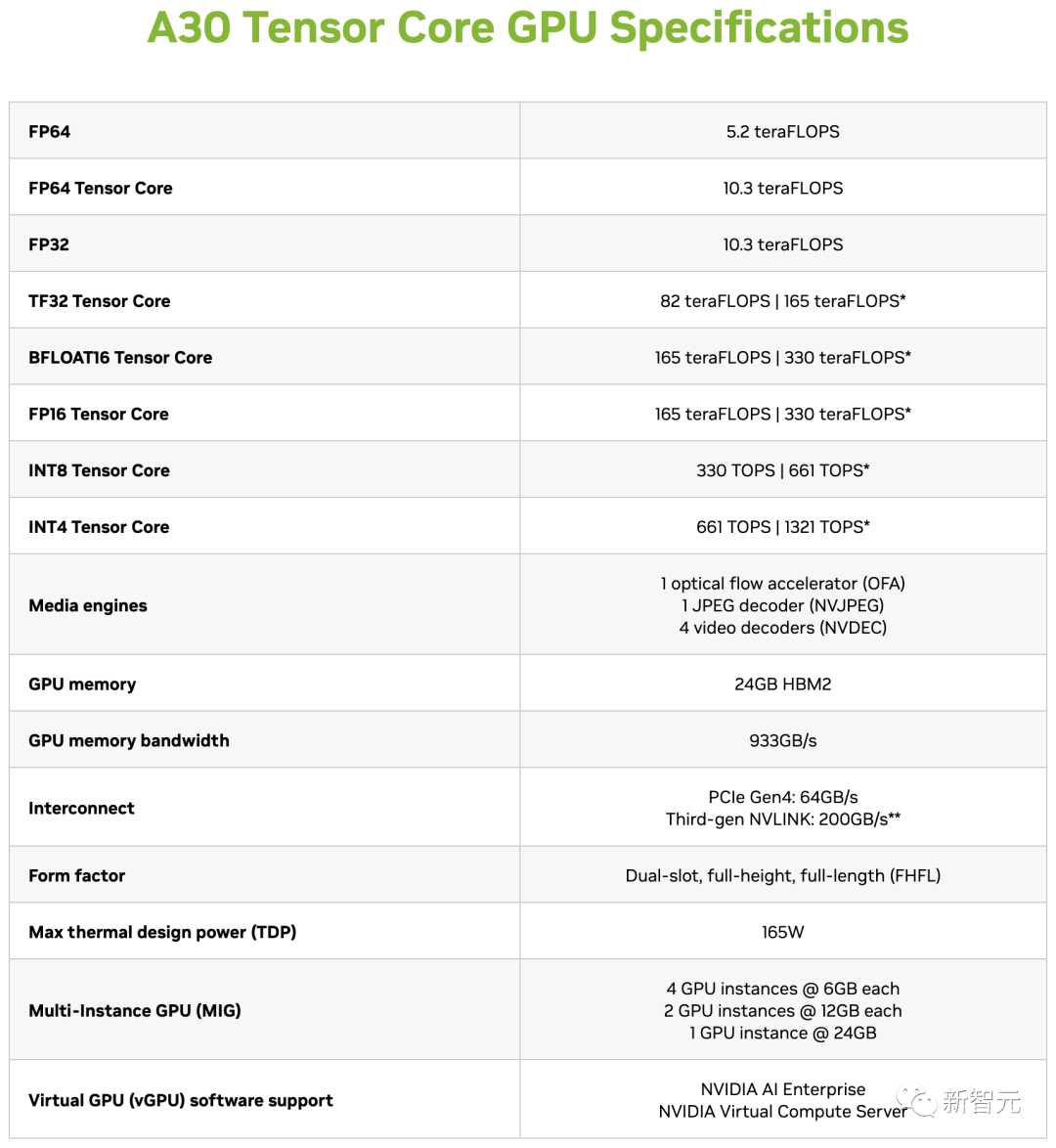
有趣的是,基于安培架构并配备24GB HBM2的入门级A30 GPU,在FP64和FP16/BF16精度下,都要比HGX H20快不少。
至于L20和L2 PCIe GPU,则是基于阉割后的AD102和AD104核心,对应的是与L40和L40S相同的市场。
更直观地,RTX 4090采用的便是AD102的变体,而4070和4070Ti则是基于AD104的变体。
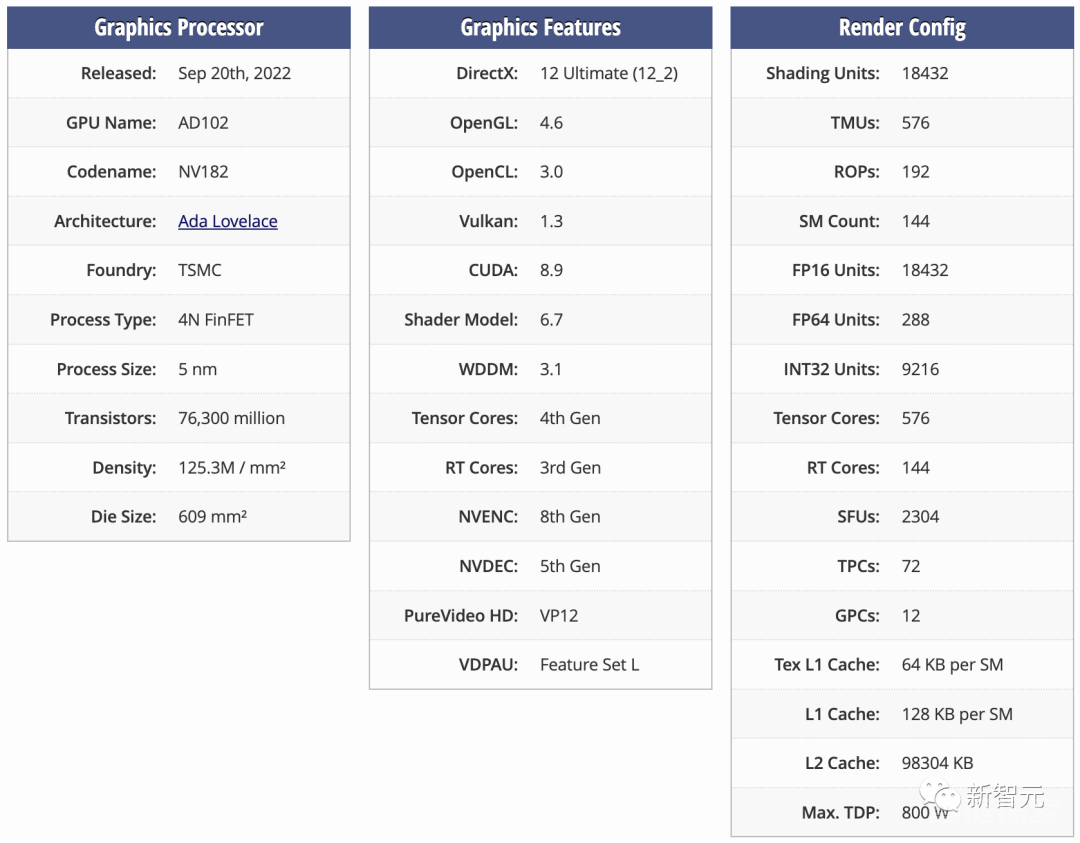
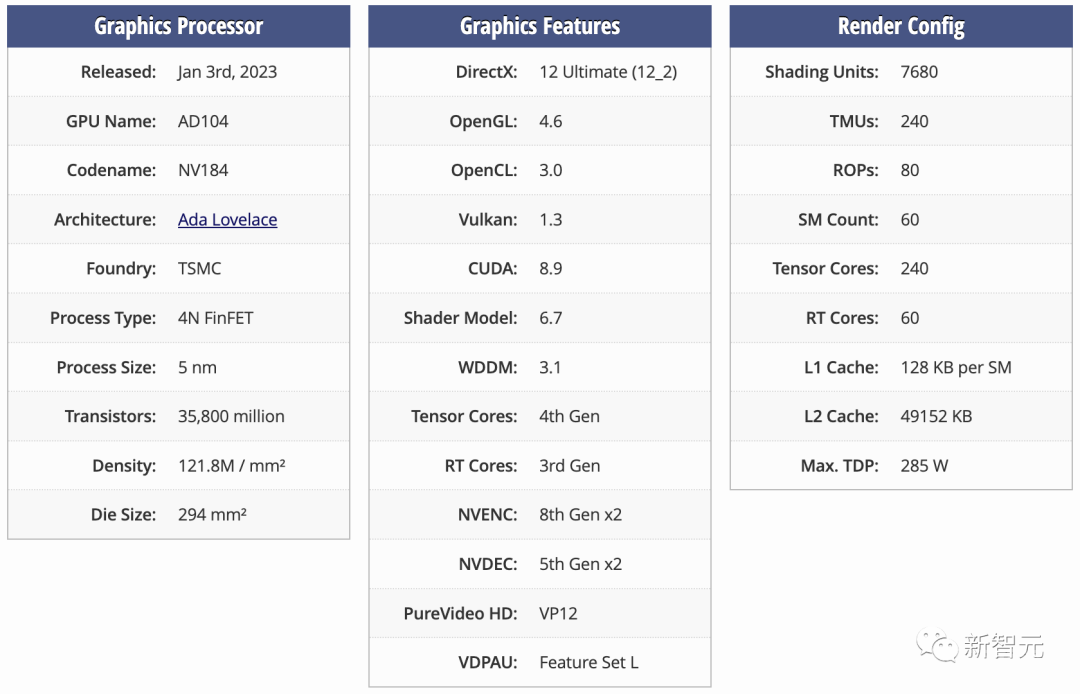
除此之外,为了遵守新规,HGX H20、L20 PCle和L2 PCle GPU不仅性能是残血的,而且还只配备了残血版的NVLink连接。




还没有评论,来说两句吧...