

摘要

本文探讨了如何利用大语言模型和AI视频生成模型来创建高度个性化和创意丰富的视频内容。文章详细介绍了从构思到实现的全过程,包括问题分析、目标设定、工具和模型选择,以及实际操作步骤。使用的技术和工具包括OpenAI的GPT-3.5-turbo、Hugging Face的zerscope_v2_576w模型,以及Langchain、PyTorch等辅助工具。
开篇
在科技日新月异的今天,人工智能不仅仅局限于数据分析或自动驾驶等领域,其在创意产业中的应用也越来越广泛。那么,能不能让大语言模型与AI视频生成模型联手,为我们带来高度个性化且极富创意的视频内容呢?本文将介绍如果通过输入几个关键词让大模型帮助我们生成创意视频。其中用到了OpenAI,Hugging face开源库,LangChain等技术或框架,通过手把手编写代码,查找资料的方式呈现完整的开发过程。
突发奇想
在浏览社交媒体时,我经常看到各种精彩绝伦的创意视频。每次看到这些,我都忍不住想:如果我也能制作出这样的作品,该有多好!但问题是,我作为一个码农对创意这件事一直不太自信。那么如何能够创建属于自己的创意视频呢?
突然,我想到了大语言模型和AI视频生成技术。大语言模型擅长生成文本,而AI视频生成模型则能从文本生成视频。那么,它们能否联手,帮助我填补这一创意缺口呢?
思路整理:明确目标,分解任务
在有了初步的想法后,下一步就是具体地整理思路,明确我们需要解决哪些问题。这样不仅能让我们有目标可行,还能为后续的行动计划提供明确的方向。以终为始,我们的目标就是让计算机帮我们自动生成创意视频,那么就可以分割为产生创意和生成视频两个环节。
问题一:创意缺乏,如何解决?
对于大多数码农来说,创意并不是我们的强项。但是好消息是,现在有大语言模型能够在这方面帮助我们。通过合理地设置提示(prompt)或者利用现有的模板,我们甚至能生成具体的创意脚本。
我的初步想法如下:
1. 查找合适的大语言模型,例如GPT-3.5-turbo。
2. 设计或找到有效的文本提示模板。
3. 进行多轮的文本生成实验,直到满意为止。
问题二:如何生成视频?
生成创意文本后,下一步就是将这些文本转化为视频。由于我们并不是专业的视频制作人员,因此找到一个现成的、用户友好的AI视频生成模型将会非常有帮助。
这也难不倒我,通过下面几步或许能够如愿以偿:
1. 搜寻开源的AI视频生成模型,到最大的模型库Hugging face上去找找一定会有收获。
2. 了解模型的输入要求和使用方式。
3. 实施初步的视频生成测试,如果需要,进行必要的调整。
首先,利用大语言模型解决创意问题;其次,利用AI视频生成模型将创意实现为具体的视频内容。这样一来,即便我们不是“创意大师”,也完全有能力制作出令人印象深刻的创意视频。
查找资料:武装自己的工具箱
通过对目标的分析,我们总结出两大问题,并且针对每个问题都有了基本的解决思路。接下来需要了解对应的工具,同时对工具,框架和库进行测试,从而验证我们的想法。
接着,我们对技术做了如下的选择:
大语言模型:OpenAI的GPT-3.5-turbo
OpenAI是在AI界非常有影响力的组织,其推出的GPT模型家族几乎成为了大语言模型的代名词。同时,与其他版本相比,GPT-3.5-turbo的token费用更加实惠,对于个人或小型项目来说非常适用。
这里,我计划使用GPT-3.5-turbo来生成创意文本。通过设置特定的提示和参数,我能够让模型产生具有高创意价值的文本内容。
AI视频模型:cerspense/zeroscope_v2_576w
在Hugging Face的平台上,这个模型因其高Star评级而受到了大量关注,这通常是社群对其有效性的一种认可。那么在这个平台上面如何找到我们需要的模型呢?
首先,登录平台,在首页选择“Tasks”。
在Tasks中列出所有Hugging face上模型能够执行的任务,并且Hugging face 已经对所有的模型进行了分类。我们找到“Text-to-Video”的分类,点击进入。

在进去的页面会对这类模型进行简单地介绍。它会告诉你将文本输入到模型,输出的结果就是视频。我们点击右边的“Browse Models”按钮浏览所有的模型。
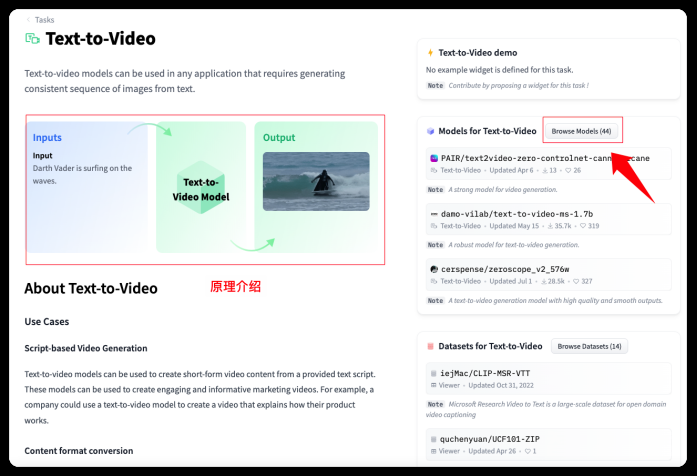
在展开的模型列表中,最上面的zeroscope_v2_576w 下载量有28.5K,看来用的人很多,而且星星数量也不少。
点击进入模型详情页,里面对模型进行了简单描述,并且提供了模型的使用方式。由于所有Hugging face上面托管的模型都可以免费使用,所以我们直接按照使用方法调用就好了。 具体的调用方法会在后面的代码描述中说明。
我看了看模型基本没有问题,于是敲定就是它了。将文本转化为视频内容的重任就交给它了。
辅助工具:Langchain, PyTorch, Diffusers
解决两个大模型工具的问题之后,我们还需要一些帮手。
Langchain:作为一个大模型的脚手架,Langchain的Prompt Template可以帮助我更有效地设置和优化模型的输入提示。
PyTorch:作为一个强大的机器学习库,PyTorch可以用于定制一些特定功能,让我更灵活地使用前两者。
Diffusers库:提供了诸如`DiffusionPipeline`和`DPMSolverMultistepScheduler`等工具,这些可以用于进一步优化视频生成过程。
Langchain主要用于优化大语言模型的输入和输出,PyTorch用于更高级的自定义和优化,而Diffusers库则可以用于进一步提升视频生成的质量。
通过选择工具和模型,我为自己构建了工具箱。每一项选择都是出于特定的考虑和需求,旨在解决我在创意视频生成过程中可能遇到的问题。这样,即使我不是一个“创意大师”,也有信心能制作出令人印象深刻的创意视频。
小心尝试:遇到的问题与调整
刚开始,我尝试用一些简单的关键字给到zeroscope_v2_576w模型,比如“小猫”,“科技感”,“奔跑”,来生成文本。然而,我很快发现这样做产生的创意还是不够丰富。语言的敏感性:英文输入的效果更好。这和我之前预想的差不多,通过简单的关键词生成视频可能还是不够。
通过如下代码,我搞定了创意文字的输出。
from langchain.llms import OpenAI from langchain import PromptTemplate llm = OpenAI(model_name="gpt-3.5-turbo") template = """ 我想让大模型根据文字生成创意视频,我本身没有什么思路, 会输入几个关键词,你根据这几个词生成具有创意的一句话(英文),在15token以内。 我把中文输入放到这里:{input},将你生成的这句话直接输出,由于我要用这句话直接生成视频,所以在输出的时候不要附加除了这句话之外的内容。 """ prompt = PromptTemplate( #接受用户输入 input_variables=["input"], #定义Prompt tempalte template=template, ) #这里是真正的用户输入 final_prompt = prompt.format(input='小猫 科技感 奔跑 ') response = llm(final_prompt) print (f"大语言模型的回应: {response}")1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.照例我们对代码进行简单介绍:
这段代码是用于生成创意视频概念的文本,具体通过与OpenAI的GPT-3.5-turbo大模型交互来实现。下面是代码各部分的解释:
1. 导入必要的模块:
- `from langchain.llms import OpenAI`: 导入Langchain库中的OpenAI模块,用于与GPT-3.5-turbo交互。
- `from langchain import PromptTemplate`: 导入Langchain的PromptTemplate类,用于构建和格式化模型的输入。
2. 初始化大模型:
- `llm = OpenAI(model_name="gpt-3.5-turbo")`: 初始化OpenAI的GPT-3.5-turbo模型。
3. 定义模板:
- `template = """..."""`: 定义一个字符串模板,用于生成与大模型交互的最终提示(prompt)。
4. 创建PromptTemplate对象:
- `prompt = PromptTemplate(...)`: 使用之前定义的字符串模板和输入变量来创建PromptTemplate对象。
5. 生成最终的提示:
- `final_prompt = prompt.format(input='小猫 科技感 奔跑 ')`: 格式化PromptTemplate对象,插入真正的用户输入。
6. 与大模型交互:
- `response = llm(final_prompt)`: 使用格式化后的提示与GPT-3.5-turbo模型进行交互,获取模型的输出。
7. 输出模型的响应:
- `print (f"大语言模型的回应: {response}")`: 打印模型生成的创意文本。
大语言模型的回应: "Technology-driven feline streaks across in a futuristic blur."1.
大模型的回应是上面这句英文,我反正没有看出有什么创意,不过还是需要进行测试的。
在输入prompt的部分我纠结了很久,GPT的模型有时候会输出一些不必要的“废话”,最后我强制它只输出创意句子才满足了我的要求。因为这里的response需要传给视频生成的模型,所以无关的信息是越少越好。
接下来的代码就是将response给我们的zeroscope_v2_576w 视频模型了。
# 导入PyTorch库,这是一个用于机器学习和深度学习的开源库 import torch # 从diffusers库中导入DiffusionPipeline和DPMSolverMultistepScheduler类 # DiffusionPipeline用于处理扩散流程,DPMSolverMultistepScheduler用于调度多步解算器 from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler # 从diffusers.utils模块中导入export_to_video函数,用于导出生成的视频帧 from diffusers.utils import export_to_video # 使用from_pretrained方法从预训练模型"cerspense/zeroscope_v2_576w"中加载DiffusionPipeline # 并设置数据类型为float16以减少内存使用和提高计算速度 pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_576w", torch_dtype=torch.float16) # 从当前管道的调度器配置中创建一个新的多步解算器调度器(DPMSolverMultistepScheduler) pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) # 启用CPU离线模型加载,在有限的GPU内存下运行更大的模型 pipe.enable_model_cpu_offload() # 设置输入提示 prompt = response # 使用管道进行推理,得到生成的视频帧 # num_inference_steps设置为40,表示使用40步进行推理。 # 扩散模型需要通过扩散:添加噪声,收缩:去除噪声,最终生成数据。 # height和width设置生成视频的分辨率 # num_frames设置生成视频的帧数 video_frames = pipe(prompt, num_inference_steps=40, height=320, width=576, num_frames=24).frames # 使用export_to_video函数导出生成的视频帧,保存为视频文件 video_path = export_to_video(video_frames) 1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.这段代码主要用于将大模型生成的创意文本转化为一段视频。代码涉及多个步骤和组件,下面是代码部分的解释:
导入必要库和模块
1.导入PyTorch库:PyTorch是一个用于机器学习和深度学习的开源库。
2.导入DiffusionPipeline和DPMSolverMultistepScheduler:这两个类分别用于处理扩散流程和调度多步解算器。
3.导入export_to_video函数:这个函数用于将生成的视频帧导出为一个视频文件。
4.加载预训练的DiffusionPipeline:使用`from_pretrained`方法加载预训练模型"cerspense/zeroscope_v2_576w"。
5.设置调度器:从当前管道的调度器配置中创建一个新的多步解算器调度器。
6.启用CPU离线模型加载:这一步可在有限的GPU内存下运行更大的模型。
7.设置输入提示:用大模型生成的文本(存储在变量`response`中)作为输入。
8.进行推理:使用DiffusionPipeline进行推理,生成视频帧。
- `num_inference_steps=40`:推理过程会经历40个步骤。
- `height=320, width=576`:设置生成视频的分辨率。
- `num_frames=24`:设置生成视频的帧数。
9.导出生成的视频帧:使用`export_to_video`函数将生成的视频帧保存为一个视频文件。
整体逻辑是:先初始化所需的各个组件和库,然后设置适当的参数和输入提示,最后执行推理和导出结果。
得到结果:终点也是新的起点
经过上面的一番折腾,我将文件生成到了video_path 这个目录中了。由于使用了co-lab的虚拟机实现了上面的代码。
Google Colaboratory(简称Colab)是一个基于云端的Jupyter Notebook环境,用于编写和执行Python代码。它为数据科学、机器学习、深度学习等领域的研究和教育提供了便利的平台。以下是一些关键特点和优势:
主要特点:
1.免费使用:Colab是一个免费的服务,你只需要有一个Google帐号即可使用。
2. 便捷的共享和协作:与Google Drive集成,方便文件的上传、下载和共享。也可以多人实时编辑同一个Notebook。
3. GPU支持:Colab提供免费的GPU资源,这对于执行复杂的机器学习或数据处理任务非常有用。
4. *简单易用:无需配置,只需打开一个Web浏览器就可以编写和执行代码,适合初学者和专家。
5. *丰富的库支持*:预安装了大量的Python库,无需手动安装就可以直接使用,如NumPy, Pandas, TensorFlow, PyTorch等。
我这里打印一下 video_path 所在的目录。
print(video_path)1.

发现在tmp 目录下,我下载视频并且打开播放。看看这猫叫一个抽象,是因为奔跑的原因吗?前腿去哪里了?

是提示词不精准吗?于是,我调整提示词如下,让gpt-3.5-turbo知道我是给视频大模型提供生成句子的。
我想让大模型根据文字生成创意视频,生成视频的模型我使用的是Hugging face上的zeroscope_v2_576w,我希望你给出的提示词它能够理解。
我本身没有什么思路, 会输入几个关键词,你根据这几个词生成具有创意的一句话(英文),在15token以内。
我把中文输入放到这里:{input},将你生成的这句话直接输出,由于我要用这句话直接生成视频,所以在输出的时候不要附加除了这句话之外的内容。
于是,我得到下面这段创意文字。
A futuristic, tech-savvy cat swiftly dashes through time.1.
希望,能够得到好效果,于是我怀着忐忑的心情又生成了一次视频。

这次看上去更像一只猫了,还有蓝色的“围脖”,这就是科技感吗?
最终,我虽然生成了一个包含“小猫”、“科技感”和“奔跑”等元素的创意视频,但还需要不断的进行调整才能达到我的预期。所以,这只是一个开始。未来,我还计划进一步优化方法,并尝试更多不同类型的创意内容。
总结
通过整合不同的AI技术和工具,即便不是“创意大师”,我们也能生成富有创意和个性的视频内容。在实验过程中,我们遇到了一些问题,例如语言敏感性和输入效果,但通过不断调整和优化,最终实现了目标。这不仅为那些在创意产业中想要做出一番贡献但又缺乏信心的人提供了一条可能的路径,也展示了AI在创意领域的巨大潜力。通过合理地组合和应用这些先进的技术,我们完全有能力突破传统的限制,创造出更加惊艳和个性化的作品。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。




还没有评论,来说两句吧...