

大型语言模型(LLM)所使用的数据量和计算量都是前所未见的,这也使其有望从根本上改变我们与数字世界的交互方式。随着 LLM 被不断快速部署到生产环境中并不断扩展进化,可以预见这些模型将能在更多复杂精细的用例中提供服务,比如分析具备丰富知识的密集型文档、提供更加真实和有参与感的聊天机器人体验、在编程和设计等交互式创造过程中辅助人类用户等。
为了支持这种演进发展,模型需要的一大关键能力就是:高效处理长上下文输入。
到目前为止,具有稳健长上下文功能的 LLM 主要来自专有 LLM API,如 Anthropic 和 OpenAI 提供的 LLM 服务。现有的开源长上下文模型往往评估研究不足,而是主要通过语言建模损失和合成任务来衡量其长上下文能力,这样的评估无法全面展示模型在各种真实世界场景中的有效性。
不仅如此,这些模型往往还会忽视在标准短上下文任务中保持强大性能的必要性,要么就直接不评估,要么报告出现了性能下降情况。
近日,Meta 团队提出了一种新方法,宣称可以有效地扩展基础模型的上下文能力,并且用该方法构建的长上下文 LLM 的性能表现优于所有现有的开源 LLM。

论文:https://arxiv.org/abs/2309.16039
他们是通过对 LLaMA 2 检查点进行持续预训练来构建模型,这其中用到了另外 4000 亿个 token 构成的长训练序列。在训练的系列模型中,较小的 7B/13B 变体模型的训练使用了 32,768 token 长的序列,而 34B/70B 变体则使用了 16,384 token 长的序列。
评估方面,不同于之前已有模型的有限评估,Meta 的这个团队进行了更为全面的评估研究,涵盖语言建模、合成任务以及许多涉及长或短上下文任务真实世界基准任务。
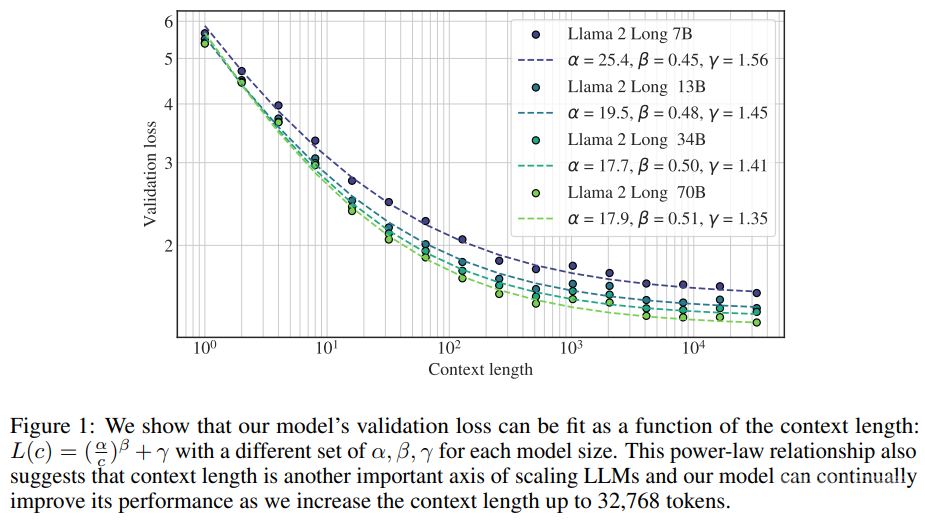
在语言建模任务上,新方法训练的模型在上下文长度方面表现出了明显的幂律缩放行为。如图 1 所示,这种缩放行为不仅表明新模型能够持续受益于更多上下文,也表明上下文长度是 LLM 扩展方面的一大重要轴线。
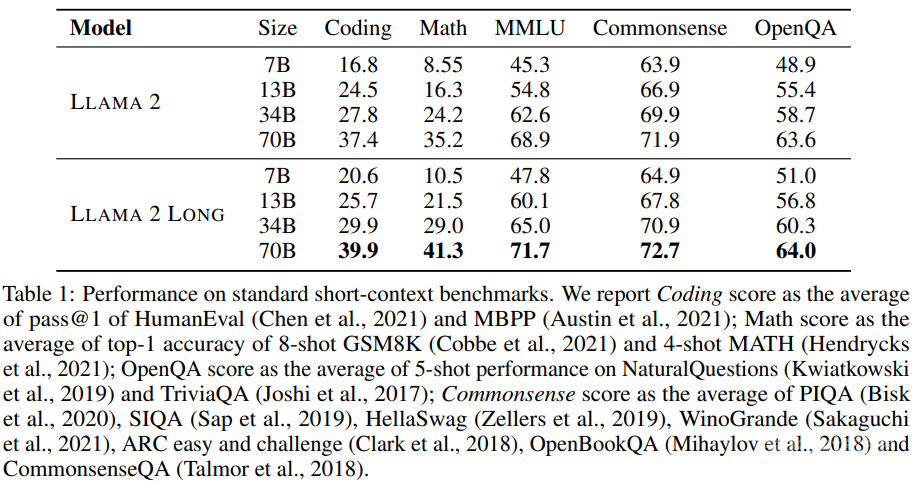
通过对比新模型与基准 LLaMA 2 在研究基准上的表现,研究者观察到新模型在长上下文任务上有明显优势,在短上下文任务上也有适度提升,尤其是在编程、数学和知识类任务基准上。
他们还探索了一种简单且有成本效益的指令微调方法,可在没有任何人工标注数据的情况下对经过持续预训练的长模型进行微调。他们基于此方法得到的聊天模型在一系列长上下文基准任务(包括问答、摘要和多文档聚合)上的整体表现胜过 gpt-3.5-turbo-16k。
方法
持续预训练
由于注意力计算会随序列长度增大呈二次增长,因此当使用更长的序列进行训练时,计算开销也会显著增大。解决这一难题正是本研究的主要目标。
研究者假设:对短上下文模型进行持续预训练可让该模型具备上下文能力。然后他们通过实验验证了这一猜测。
在实验中,他们保持原始 LLaMA 2 的架构基本不变,仅对位置编码进行了必要的修改,以便其能将注意力覆盖更长的序列。此外,他们还选择不使用稀疏注意力,因为 LLaMA 2 70B 模型的维度为 h=8192,而只有当序列长度超过 49,152 (6h) 个 token 时,注意力矩阵计算和值聚合的成本才会成为计算瓶颈。
位置编码。通过 7B 模型的早期实验,研究者发现了 LLaMA 2 的位置编码(PE)的一大关键局限 —— 其有碍注意力模块聚合相聚较远的 token 的信息。为了解决这个问题,使模型能处理长上下文建模,研究者对 RoPE 位置编码方法进行了少量但必要的修改,即减小旋转角度(由基频 b 这个超参数控制),其作用是降低 RoPE 对远距离 token 的衰减效应。研究者通过实验展现了这种简单方法在扩展 LLaMA 上下文长度方面的有效性,并还给出了理论解释。
数据混合。基于使用修改版位置编码的模型,研究者还进一步探索了不同数据混合方法对提升长上下文能力的作用,其中涉及的方法包括调整 LLaMA 2 的预训练数据的比例和添加新的长文本数据。研究者发现:对于长文本的持续预训练而言,数据的质量往往比文本的长度更重要。
优化细节。那么他们究竟是如何实现持续预训练的呢?据介绍,他们在对 LLaMA 2 检查点模型进行持续预训练时,会在保证 LLaMA 2 中每批数据同等 token 量时不断增大序列长度。所有模型都使用总计 4000 亿个 token 训练了 10 万步。使用 Dao et al. (2022) 提出的 FlashAttention,当增大序列长度时,GPU 内存开销几乎可以忽略不计;研究者观察到,对于 70B 模型,当序列长度从 4096 增至 16384 时,速度下降了大约 17%。对于 7B/13B 模型,他们使用的学习率为 2e^−5,并使用了余弦学习率计划,预热步骤为 2000 步。对于更大的 34B/70B 模型,该团队发现设置更小的学习率(1e^-5 )很重要,这样才能让验证损失单调递减。
指令微调
为 LLM 对齐任务收集人类演示和偏好标签是一个繁琐而昂贵的过程。对于长上下文任务,这一挑战和成本更为突出,因为这些任务通常涉及复杂的信息流和专业知识,例如处理信息密集的法律 / 科学文档 —— 即使对于熟练的标注者来说,这些标注任务也不简单。事实上,大多数现有的开源指令数据集都主要由短样本组成。
针对这一问题,Meta 的这个研究团队发现了一种简单且低成本的方法,其能利用已经构建好的大规模和多样化的短 prompt 数据集,并使其很好地适用于长上下文基准任务。
具体来说,他们取用了 LLaMA 2 Chat 使用的 RLHF 数据集,并使用 LLaMA 2 Chat 自身合成的自指示(self-instruct)长数据对其进行了增强。研究者表示,他们希望模型可以借此通过大量 RLHF 数据学习多样化的技能组合并通过自指示数据将所学知识迁移至长上下文场景。
这个数据生成过程重点关注的是问答格式的任务:先从预训练预料库的一个长文档开始,从中随机选出一块文本,然后通过 prompt 让 LLaMA 2 Chat 基于该文本块中的信息写出成对的问答。研究者收集了不同 prompt 的长形式和短形式答案。
之后还有一个自批判(self-critique)步骤,即通过 prompt 让 LLaMA 2 Chat 验证模型生成的答案。给定生成的问答对,研究者使用原始长文档(已截断以适应模型的最大上下文长度)作为上下文来构建一个训练实例。
对于短指令数据,研究者会将它们连接成 16,384 token 长的序列。对于长指令数据,他们会在右侧添加填充 token,以便模型可以单独处理每个长实例,而无需截断。
虽然标准的指令微调只在输出 token 上计算损失,但该团队发现,如果也在长输入 prompt 上计算语言建模损失,也能获得特别的好处,因为这能为下游任务带来稳定持续的提升。
主要结果
评估预训练后的模型
表 1 聚合给出了在标准的短上下文基准任务上的性能表现。
在短上下文任务上,如表 2 所示,使用新方法得到的模型在 MMLU 和 GSM8k 上优于 GPT-3.5。
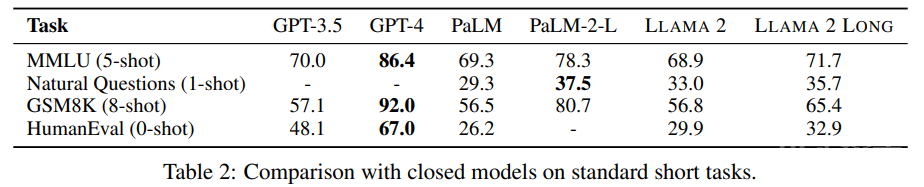
在长上下文任务上,如表 3 所示,新模型整体上表现更优。在 7B 规模的模型上,只有 Together-7B-32k 取得了与新模型相当的表现。
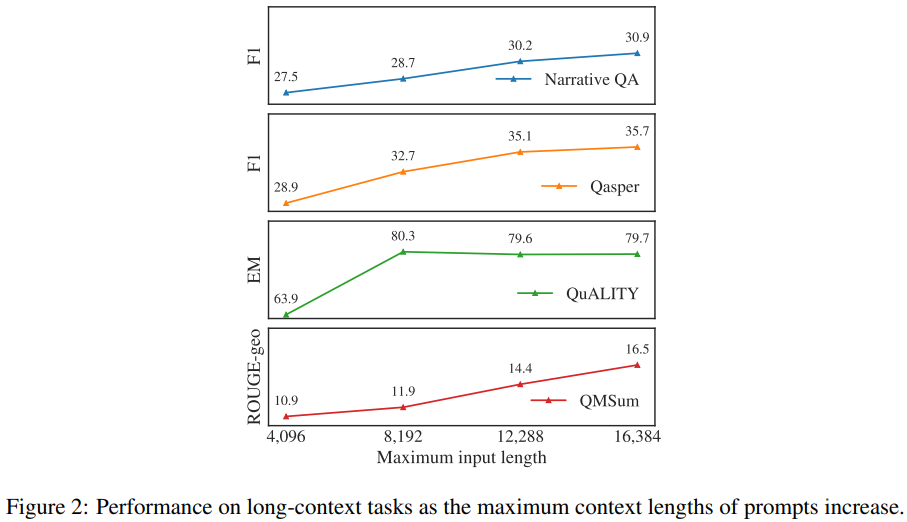
有效利用上下文。为了验证新模型确实能有效使用增大的上下文窗口,从图 2 可以看到,在每个长任务上的结果都会随上下文长度的增长而单调提升。研究者还发现,新模型的语言建模损失与上下文长度之间存在一种幂律加常数的缩放关系(见图 1),这说明:
在语言建模任务上,随着上下文长度增长,一直到 32,768 token 长的文本,新模型的性能都会持续提升,尽管后面的提升幅度会不断变小。
更大的模型能更有效地利用上下文,这从那些曲线的 β 值可以看出。
指令微调结果
如表 4 所示,在不使用任何人类标注的长上下文数据的情况下,新训练的 70B 规模的聊天模型在 10 项任务中的 7 项上都优于 gpt-3.5-turbo-16k。
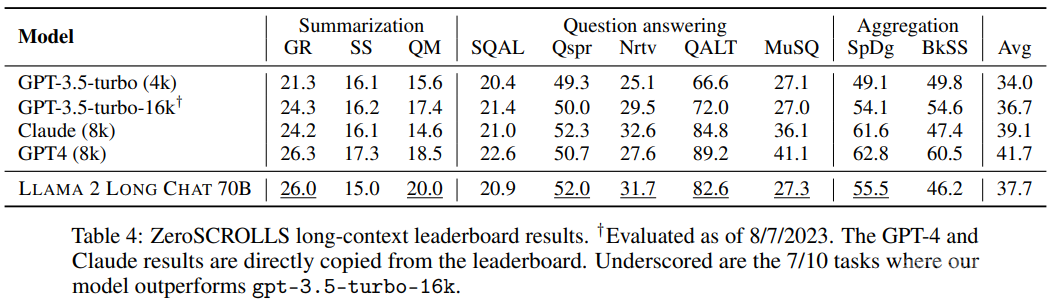
人类评估
通过计算每个相比较的示例结果的平均值,可以看出实验中新模型的标准胜率优于其它每个模型;图 3 给出了最终得分以及 95% 的置信区间。
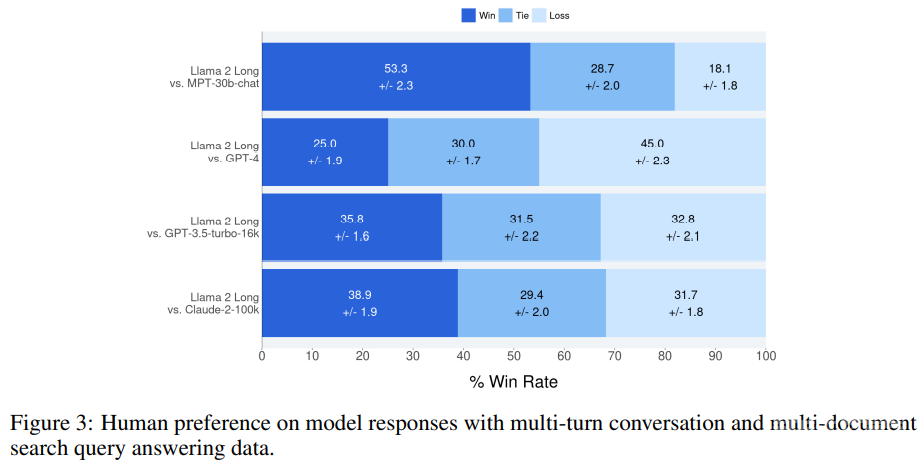
在指令数据很少的情况下,新方法所得模型的表现可与 MPT-30B-chat、GPT-3.5-turbo-16k 和 Claude-2 媲美。
分析
图 4 展示了基频(base frequency)变化的影响。
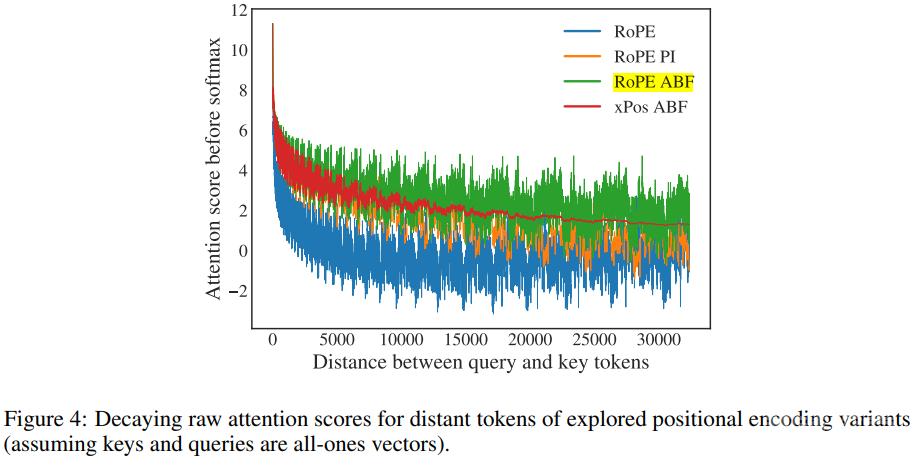
基于这些评估,整体上看,新提出的 RoPE ABF(基频调整版 RoPE)优于相比较的所有其它方法。
表 7 则通过 7B 模型实验展示了所使用的数据混合方法对长上下文任务带来的提升。
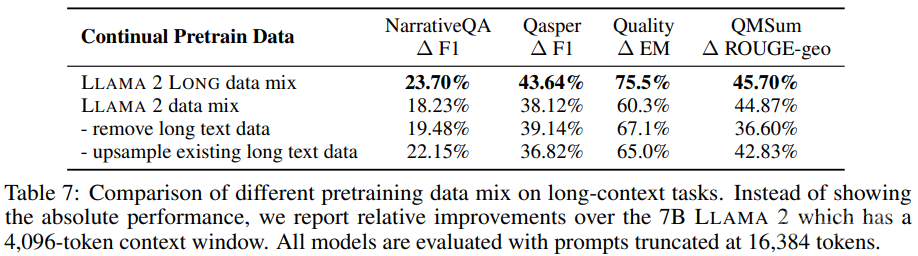
研究者还发现新的数据混合方法在很多情况下还能带来很大的提升,尤其是对于 MMLU 等知识密集型任务,如表 8 所示。
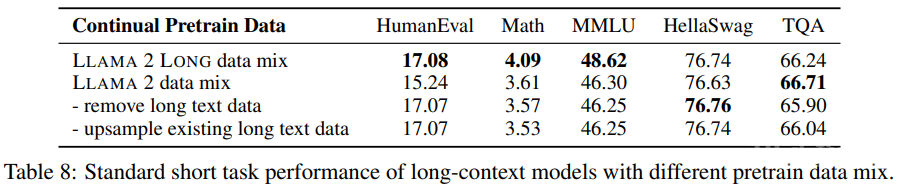
这些结果表明,即使使用非常有限的长数据,也可以有效地训练长上下文 LLM。而且研究者表示,相比于 LLaMA 2 所使用的预训练数据,该团队所使用的数据的优势在于数据本身的质量,而不是长度分布上的差异。
而表 9 表明,通过指令微调这种简单技巧,可让模型更加稳定地应对输入和输出长度不平衡的情况,从而在大多数测试任务中取得显著改进。
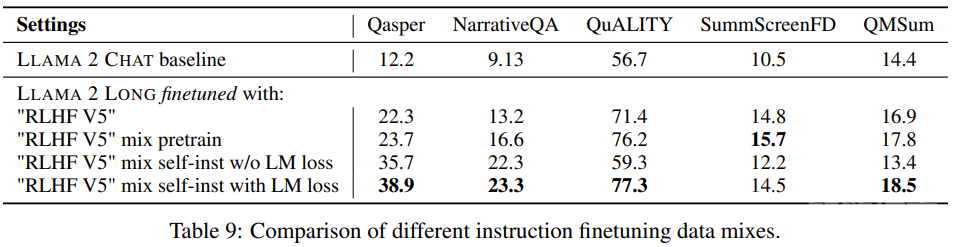
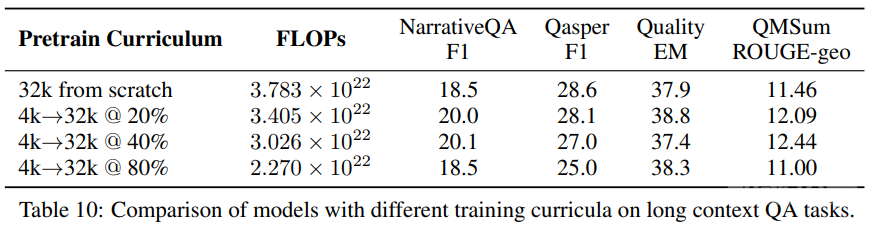
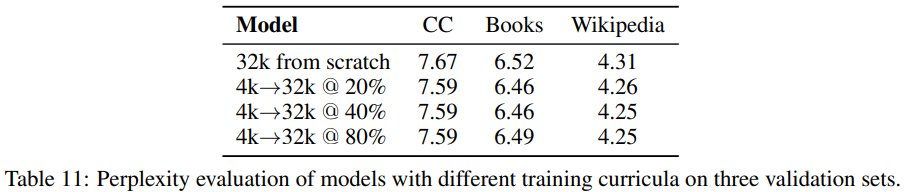
表 10 和 11 则表明对短上下文模型持续预训练可在几乎无损于性能表现的同时轻松节省约 40% 的 FLOPs。
AI 安全
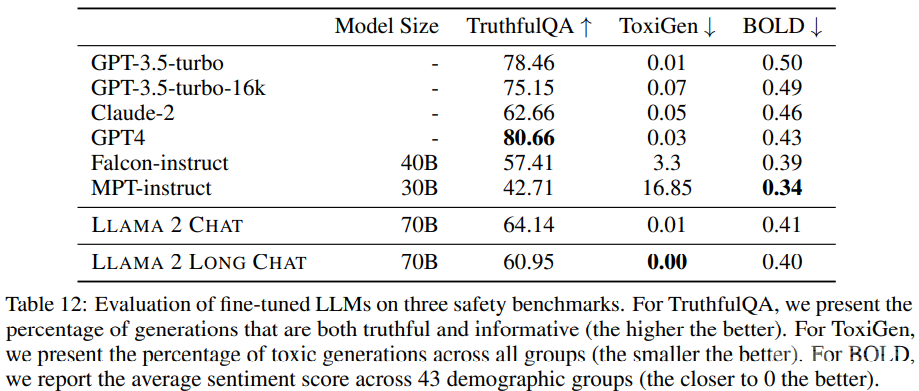
在 AI 安全方面,研究者观察到,与 LLaMA 2 Chat 相比,经过指令微调的模型整体上能维持相近的安全性能;而且与 Falcon-instruct 和 MPT-instruct 等其它开源 LLM 相比,经过指令微调的模型会更安全且偏见也更少。
华人作者介绍
Wenhan Xiong
Wenhan Xiong 现为 Meta Generative AI 研究科学家,他本科毕业于中国科技大学,博士毕业于加州大学圣巴巴拉分校。他的研究致力于打造能完成复杂、专业的长文本大语言模型,参与了包括 Code Llama 在内的多个研究项目,博士期间他专注构建开放问答系统和检索增强的自然语言处理。

个人主页:https://xwhan.github.io/
Jingyu Liu
Jingyu Liu 现为苏黎世联邦理工学院硕士研究生,本科毕业于纽约大学计算机系,此前在 Meta Generative AI 做大语言模型的研究,他参与了包括 Code Llama 在内的多个研究项目。

谷歌学术:https://scholar.google.com/citations?user=jidrykQAAAAJ&hl=en
Hejia Zhang
Hejia Zhang 现为 Meta Generative AI 组高级研究科学家,主要研究 Meta 基础大模型、AI Agent,及其在 Meta 产品线中的应用,此前曾在 Meta 推荐系统和人工智能组进行自然语言处理相关研究。她本科毕业于莱斯大学(电子工程和应用数学双学位),博士毕业于普林斯顿大学(电子工程和神经科学联合学位)。

谷歌学术:https://scholar.google.com/citations?user=bI0cfykAAAAJ&hl=en
Rui Hou
Rui Hou 现为 Meta GenAI 研究科学家,主要研究生成式 AI 技术以及相关的生产应用。他于 2020 年 4 月入职 Meta,此前曾在丰田研究院等机构实习。
他本科毕业于同济大学,硕士(智能系统和计算机科学双学位)和博士(智能系统)均毕业于密歇根大学。

谷歌学术:https://scholar.google.com/citations?user=PKHKqX0AAAAJ&hl=en
Angela Fan
Angela Fan 是 Meta AI Research Paris 的研究科学家,主要研究机器翻译。此前她曾在南锡 INRIA 和巴黎 FAIR 攻读博士学位,主要研究文本生成。在此之前,她是一名研究工程师,并在哈佛大学获得了统计学学士学位。

个人主页:https://ai.meta.com/people/angela-fan/
Han Fang
Han Fang 现为 Meta Generative AI 组高级经理,负责 AI agent 以及 LLAMA 在 meta 的应用开发,此前曾在 meta 推荐系统和人工智能组任职。他本科毕业于中山大学,博士毕业于纽约州立大学石溪分校应用数学与统计专业。

个人主页:https://ai.meta.com/people/han-fang/
Sinong Wang
Sinong Wang 现为 Meta 高级主任科学家,Meta Generative AI 组技术负责人。目前领导 Meta 基础大模型和 AI agent 开发,以及在 meta 产品线中的应用。此前他在 Meta AI 致力于自然语言处理、transformer 架构、(语言 / 图像)多模态研究。他博士毕业于俄亥俄州立大学电气与计算机工程专业,并多次获得 ACM/IEEE 最佳论文奖。

个人主页:https://sites.google.com/site/snongwang/
Hao Ma
Hao Ma 现为 Meta Generative AI 组总监,负责大模型和语音基础模型研究和在产品当中的应用,曾在 Meta discovery 组负责开发下一代 AI 推荐系统和 AI 安全系统。此前曾在微软研究院担任研究经理,负责知识图谱在 bing 当中的开发。他博士毕业于香港中文大学计算机专业,并多次获得 ACM test-of-time award.

个人主页:https://www.haoma.io/




还没有评论,来说两句吧...