

现如今,像ChatGPT、以及phind之类基于AI的聊天机器人,已经能够为我们生活的方方面面提供各种帮助了。但是,您可能并不总是希望由外部应用程序来处理您提出的问题以及敏感数据。尤其是在一些平台上,您与AI的互动,很可能会被后台人工监控,甚至被用于帮助训练其未来的模型。

对此,您自然而然地会想到下载大语言模型(LLM),并在自己的机器上运行。如此,外部公司就无法访问您的数据。同时,这也是尝试一些新的专业模型的快速试错方式。例如,Meta最近发布的针对编程领域的Code Llama 系列模型,以及针对文本到语音、以及语言翻译的SeamlessM4T。
“在本地运行LLM”这听起来可能有些复杂,但是只要您拥有合适的工具,就会变得出奇简单。由于许多模型对硬件的要求并不高,因此我在两个系统上进行了测试。它们分别是:配备了英特尔i9处理器、64GB内存和Nvidia GeForce 12GB GPU的戴尔PC,以及配备了M1芯片,但只有16GB内存的Mac。
需要注意的是,您可能需要花点时间研究、并关注开源模型的不断迭代,以发现一款能在自己桌面硬件上运行的、性能合适的模型。
1.使用GPT4All运行本地聊天机器人
GPT4All提供了Windows、macOS和Ubuntu版本桌面客户端的下载,以及在系统上运行不同模型的选项。总的说来,其设置并不复杂。
首次在打开GPT4All桌面应用时,您将看到约10个(截至本文撰写时)可下载到本地运行的模型选项,其中就包含了来自Meta AI的模型Llama-2-7B chat。如果您有API密钥的话,也可以设置OpenAI的GPT-3.5和GPT-4(如果您有访问权限的话)为非本地使用。
上图为GPT4All的模型下载界面部分。在我打开该应用时,事先下载的模型就自动出现了。
在设置好模型后,简洁易用的聊天机器人界面就出现了。说它便捷,是因为我们可以将聊天内容复制到剪贴板上,以生成回复。
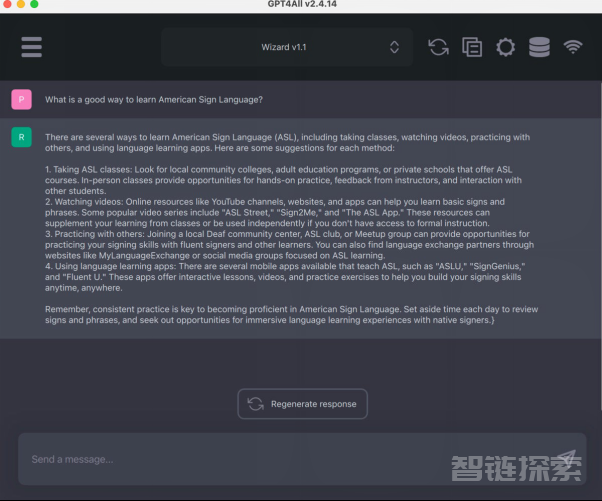
同时,它提供了一个新的测试版LocalDocs插件,方便您与自己的本地文档进行“聊天”。您可以在“设置”>“插件”选项卡中启用它。在此,您会看到一个 “LocalDocs Plugin (BETA) Settings”标题和一个在特定文件夹路径下创建集合的选项。当然,该插件仍在开发中,其相关文档声称,这是一个有趣的功能,并会随着开源模型功能的不断完善,而得到持续改进。
除了聊天机器人应用,GPT4All也绑定了Python、Node和命令行界面(CLI)。同时,GPT4All还有一个服务器模式,方便您可以通过结构类似OpenAI的HTTP API,与本地LLM进行交互。可见,其目标是让您只需修改几行代码,就能将本地LLM换成OpenAI的LLM。
2.命令行模式下的LLM
由Simon Willison提供的LLM是我见过的,这是在本地计算机上下载和使用开源LLM的最简单方法之一。虽然运行它需要安装Python,但您不需要接触任何Python代码。如果您使用的是Mac并安装了Homebrew的话,只需运行如下命令:
如果您使用的是Windows系统,请安装Python库,并输入:
LLM默认会使用OpenAI模型,但是您可以使用插件在本地运行其他模型。例如,如果您安装了GPT4All插件,就可以访问GPT4All中的其他本地模型。此外,llama还有MLC项目、MPT-30B、以及其他远程模型的插件。
请使用llm install model-name的格式,在命令行安装插件。例如:
接着,您可以使用命令llm models list,查看所有可用的远程或已安装的模型。如下列表所示,其中还包含了每个型号的简要信息。
您可以通过使用以下语法,向本地LLM发送查询请求:
接着,我向它提出了一个类似ChatGPT的问题,但并没有发出单独的命令来下载模型:
值得一提的是,如果本地系统中不存在GPT4All模型的话,LLM工具会在运行查询之前,自动为您下载。而且,在下载模型的过程中,您会在终端上看到如下的进度条。

模型给出的笑话是:“程序员为什么要关掉电脑?因为他想看看电脑是否还在工作!”这证明交互已成功进行。如果您觉得该结果不尽如人意的话,那是因为模型本身、或是用户提示信息不足,而并非LLM工具。
同时,您也可以在LLM中为模型设置别名,以便用更简短的名称来对其进行引用:
完成后,您可以通过输入:llm aliases,来查看所有可用的别名。
相比之下,用于Meta Llama模型的LLM插件需要比GPT4All更多的设置。您可以通过链接https://github.com/simonw/llm-llama-cpp,在LLM插件的GitHub库阅读详情。值得注意的是,通用的llama-2-7b-chat虽然能够在我的Mac上运行,但是它与GPT4All模型相比,运行更慢。
当然,LLM还具有其他功能,例如:参数标志可以让您从之前的聊天处继续进行,以及在Python脚本中使用。9月初,该应用获得了生成式文本嵌入工具,即文本含义的数字表示,可用于相关文档的搜索。您可以通过访问LLM网站,了解更多相关信息。
3.Mac上的Llama模型:Ollama
Ollama是一种比LLM更容易下载和运行模型的方法,但它的局限性也更大。目前,它有macOS和Linux版本,其Windows版本即将被推出。
如上图所示,通过几步点击即可完成安装。虽然Ollama是一个命令行工具,但它也只有一个语法命令:ollama run model-name。与LLM类似,如果系统中还没有所需的模型,它将自动进行下载。
您可以在https://ollama.ai/library网站上,查看到可用模型的列表。截至本文撰写之时,其中已包含了:通用Llama 2、Code Llama、DeepSE针对某些编程任务进行过微调的CodeUp,以及针对医学问答进行过微调的medllama2等,多个基于Llama的模型版本。
Ollama在GitHub代码库中的 README列出了各种型号与规格,并建议“若要运行3B型号,至少需要8GB内存;若要运行7B型号,至少需要16GB内存;若要运行13B型号,至少需要32GB内存”。在我的16GB内存Mac上,7B Code Llama的运行速度就特别快。在专业方面,它可以回答有关bash/zshshell命令,以及Python和JavaScript等编程语言的问题。
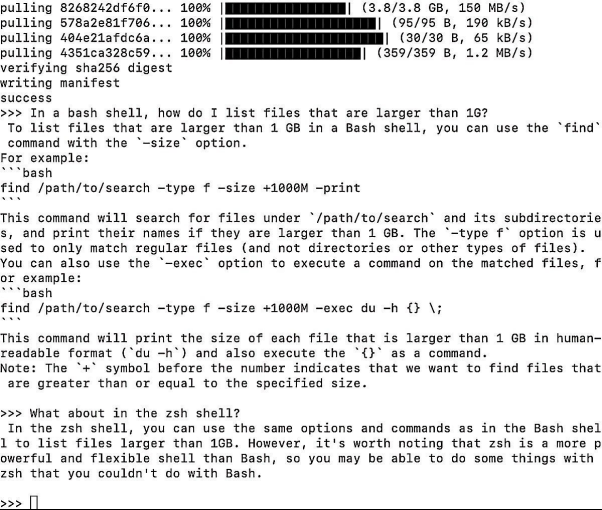
上图展示了在Ollama终端窗口中运行Code Llama的效果。例如,对于一个R代码问题:“请为一个ggplot2条形图编写 R 代码,其中条形图的颜色为钢蓝色"。许多较大的模型都无法完整回答,而Code Llama虽然是该系列中最小的模型,但是其回答相当出色。其交付出的代码基本正确,只是其中有两行代码中多了两个小括号,这在集成开发环境(IDE)中很容易被发现。
Ollama还有一些附加功能,包括:与LangChain的集成(https://www.infoworld.com/article/3705097/a-brief-guide-to-langchain-for-software-developers.html)和与PrivateGPT一起运行的功能。当然,如果您不去查看其GitHub软件库的教程页面(https://github.com/jmorganca/ollama/blob/main/docs/tutorials.md)的话,这些功能可能并不明显。
4.与自己的文件聊天:h2oGPT
深耕自动化机器学习领域多年的H2O.ai,已进入了聊天LLM赛道。其h2oGPT聊天桌面应用测试版,非常易于新手的安装与使用。
为了熟悉其界面,您可以访问https://gpt.h2o.ai/网站上的演示版本(注意,并非本地系统的LLM)。而为了获取其本地版本,您需要克隆其GitHub库,创建并激活Python虚拟环境,然后运行README文件中的五行代码。根据文档的相关介绍,运行结果会给您提供“有限的文档Q/A功能”和Meta的Llama模型。
在运行了如下代码后,您就可以在http://localhost:7860处下载Llama模型版本和应用了。
无需添加自己的文件,您就可以将该应用当作普通聊天机器人使用。当然,您也可以上传一些文件,根据文件内容进行提问。其兼容的文件格式包括:PDF、Excel、CSV、Word、text、以及markdown等。上图展示的是本地LLaMa模型根据VS Code文档,来回答问题的截图。
h2oGPT测试程序在我的16GB Mac上运行良好,不过它不如带有付费GPT-4的ChatGPT。此外,如下图所示,h2oGPT的用户界面也提供了一个专家(Expert)选项卡,为专业用户提供了大量配置、以及改进结果的选项。
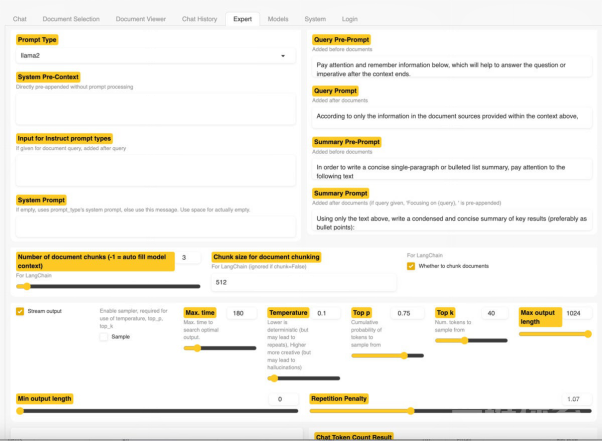
如果您希望对应用有更多的控制,并能够选择更多的模型,那么可以下载完整版的应用。其README提供了在Windows、macOS和Linux上安装的不同说明。当然,您也要顾及有限的硬件。事实证明,我现有的GPU,不足以运行一个相当大的模型。
5.能与数据进行简单但缓慢聊天的PrivateGPT
PrivateGPT可以让您使用自然语言查询自己的文档,并获得生成式AI的响应。该应用的文档可以包括几十种不同的格式。其README能够保证“100%的私密,任何数据都不会离开您的运行环境。您可以在没有互联网连接的情况下,输入文档并提出问题。”
PrivateGPT会通过脚本来接收数据文件,将其分割成不同的块,以创建“嵌入”(即:文本含义的数字表示),并将这些嵌入存储在本地的Chrome向量中。当您提出问题时,应用就会搜索相关文档,将其发送给LLM,以生成答案。
如果您熟悉Python、以及如何建立Python项目的话,您可以通过链接--https://github.com/imartinez/privateGPT,克隆一套完整的PrivateGPT库,并在本地运行之。当然,如果您对Python不甚了解,则可以参考Iván Martínez在一次研讨会上建立的简化版项目,它的设置要简单得多。其README 文件包含了详细的说明。虽然该库自带的source_documents文件夹中包含了大量Penpot(译者注:一款面向跨域团队的开源设计和原型制作工具)文档,但是您完全可以将其删除掉,并添加自己的文档。
不过,PrivateGPT的文档也警告道,它并不适合用于生产环境。毕竟一旦它在本地运行时,速度相对较慢。
6.本地LLM的更多途径
其实,在本地运行LLM的方法不止上述五种。不过其他桌面级应用往往需要从头开始编写脚本,并存在着不同程度的设置复杂性。
例如:PrivateGPT的衍生产品--LocalGPT就包含了更多的型号选项,并提供了详细说明和操作视频。虽然人们对其安装和设置的简单程度众说纷纭,但是它与PrivateGPT一样,在对应的文档中也警告了“仅在CPU环境中运行速度会很慢”。
我试用过的另一款桌面应用是LM Studio。它不但提供了简单易用的聊天界面,而且给用户更多的模型选择自主权。其中,Hugging Face Hub是LM Studio中模型的主要来源,它拥有大量可供下载的模型。
如下图所示,LM Studio会提供一个漂亮、简洁的界面。不过截至本文撰写时,其用户界面尚不能提供LLM的内置选项,以运行用户自己的数据。
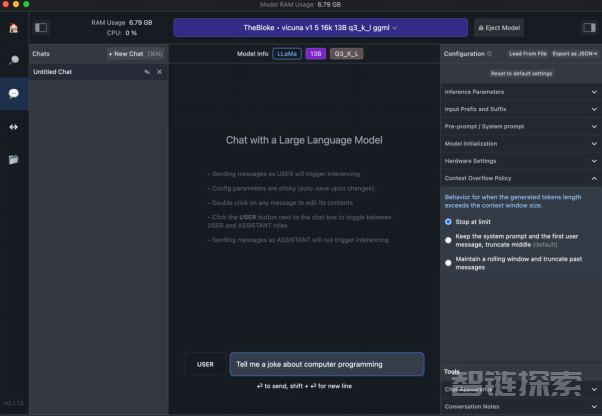
正如其参考文档提到的,它带有一个内置的服务器,可以“作为OpenAI API的直接替代”,因此那些通过API调用OpenAI模型所编写出的代码,将能够在您所选择的本地模型上运行。
由于LM Studio的代码并非由GitHub所提供,因此它也会与h2oGPT一样,在Windows上安装时,会弹出:“这是一款未经验证的应用”的警告。
除了通过h2oGPT等应用,利用预建模(pre-built model)的下载界面,您也可以直接从Hugging Face处下载并运行各种模型。这是一个人工智能平台和社区,其中包含了许多 LLM。此外,Hugging Face还提供了一些关于如何在本地安装和运行可用模型的文档,具体请参考--https://huggingface.co/docs/transformers/installation。
而另一种流行的方法是在LangChain中下载并在本地使用LLM。这是一个用于创建端到端生成式AI应用的框架。您既可以通过链接--https://www.infoworld.com/article/3705097/a-brief-guide-to-langchain-for-software-developers.html,了解LangChain的基础知识;又可以通过https://python.langchain.com/docs/integrations/llms/huggingface_pipelines,查看有关Hugging Face本地管道的相关内容。
此外,OpenLLM也是另一个强大的独立平台,可以帮助开发者将基于LLM的应用部署到生产环境中。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:5 easy ways to run an LLM locally,作者:Sharon Machlis




还没有评论,来说两句吧...