

中途迷失、模型偷懒、上下文越长大模型越笨……
体验过LLM的人,多少都会对文本输入长度带来的限制有所感触:
想和大模型讨论一些稍长的内容,就需要拆分输入,而前面输入的要点,很快就会被大模型忘记。
实际上,这些都是典型的大语言模型对话缺陷。就像先天有注意力缺陷的儿童,难以专注看完一本新书。而缺陷的关键,在于模型缺乏长文本处理能力。
如今,这个局面已经被打破了!
就在近日,由贾佳亚团队联合MIT发布的新技术和新模型,悄然登上各大开源网站的热榜:
Hugging Face热榜第一、Papers With Code热度第一,Github全部Python项目热度第五、Github Stars一周内破千,Twitter上的相关技术帖子浏览量近18万......

论文地址:https://arxiv.org/abs/2309.12307
代码和Demo地址:https://github.com/dvlab-research/LongLoRA
GitHub Stars已达1.3k

Twitter上的相关技术帖子浏览量近18万
这项名为LongLoRA的技术实用但却简单得令人惊讶:
只需两行代码、一台8卡A100机器,便可将7B模型的文本长度拓展到100k tokens,70B模型的文本长度拓展到32k tokens。
同时,该研究团队还发布了首个拥有70B参数量的长文本对话大语言模型LongAlpaca。
全球首个70B长文本大语言模型发布
LongLoRA的提出,让全球大语言模型的对话缺陷第一次得到解决,自此,几十页的论文、几百页的报告、鸿篇巨制不再成为大模型盲区。
对此,有专业人士激动地表示,LongLoRA是大语言模型迷宫中的希望之灯!
它代表着业界对长文本大语言模型的重新思考和关注,有效扩展了大语言模型的上下文窗口,允许模型考虑和处理较长的文本序列,是大语言模型的革新性发明。

除了技术革新外,大语言模型处理长文本问题的一大难点还在于缺少公开的长文本对话数据。
为此,研究团队特意收集了9k条长文本问答语料对,包含针对名著、论文、深度报道甚至财务报表的各类问答。
光会回答长问题还不够,该团队又挑选了3k的短问答语料与9K的长问答语料混合训练,让长文本大模型同时具备短文本对话能力。这个完整的数据集被称为LongAlpaca-12k,目前已经开源。
在LongAlpaca-12k数据集基础上,研究团队对不同参数大小7B、13B、70B进行了训练和评测,开源模型包括LongAlpaca-7B、LongAlpaca-13B和LongAlpaca-70B。
看小说、改论文、指点经济堪称全能王
话不多说,盲选几个demo,一起看看应用了LongLoRA技术叠加12K问答语料的大模型LongAlpaca效果。

让系统新读一篇论文,并根据ICLR的审查指南,对其提出修改意见,从而提升该论文的接收率:
LongAlpaca的意见是:通过更精确地阐明新颖性,提供更严格和更有对比性的实验结果(包括具体的数据集和指标)、更广泛的应用和未来发展方向,重点呈现关键贡献和影响,论文被接受的机会将得到提高。

现在,让系统读两篇新的不同的论文,让LongAlpaca概括ICLR和CVPR两个会议之间的风格区别:
LongAlpaca总结认为,CVPR论文倾向更具结构性和实验性的风格,专注于实用性和技术性。而ICLR的论文风格更加灵活,侧重关键的理论分析和数学推导,而非标准格式。
可以看出,经过训练的LongAlpaca模型已经可以很轻松地接受新的长篇学术论文,在学术相关问题的回答上相当精准。
接下来,再看看LongAlpaca模型在颇高阅读和理解门槛的经济领域的解读表现。


根据国际货币基金组织从2012年到2023年的全球经济展望的概述合集,对经济形势进行逐年总结以及对未来经济趋势进行预测:
LongAlpaca告诉我们,2023年全球经济形势不明朗,跟2022年相比,增长预计放缓;未来几年,全球经济扩张速度偏温和并将低于预期,而地缘政治紧张、金融市场波动等大的挑战依然存在,需通过多边合作和结构性改革小心应对。
此外,LongAlpaca还可以读新的长篇小说,读完后对内容进行分析。
下面选取的对比模型是13B参数的LongAlpaca和Llama2,且看各自表现。

名著《西游记》中,为什么孙悟空在大闹天宫时很厉害,但取经路上却屡屡受挫?
LongAlpaca给出了5点原因,大概可总结为:「孙悟空的不成熟、强大的对手、力量的限制、敌人的欺骗、最初缺少同伴等因素导致了他在旅途中的失败。但随着时间推移,他获得了智慧、经验和战友,使他最终战胜了最强大的敌人。」
而Llama2并没有给出正确答案:「虽然他确实大闹天宫,但说他代表着不败的力量并不一定准确。事实上,他最终在西游记中被强大的唐三藏打败。」

这一次让系统新读一次《三体》,然后问第一部中,叶文洁为什么要联系外星人,而后期又为什么后悔?
LongAlpaca认为,叶文洁最初接触外星人是出于理想主义和复仇,但随着时间的推移,她对人类的看法发生了变化,意识到自己可能给全人类带来的危险,她的悔恨与日俱增。回答得十分清晰。
而Llama2的回答则是,「通过与外星人的互动,她希望能更深入地了解宇宙的本质,以及自己在宇宙中的位置。叶文洁逐渐意识到,外星人和他们的技术并不能解决她的问题。」回答笼统,之后开始对小说整体进行评论,答非所问。
从模型给出的答案可发现,一些模型如Llama2[2]可能在预训练过程中见过相关小说,但如果在提问时进行仅根据小说题目进行短文本提问的话,回答并不理想。
两个模型的回答对比,高下立见。LongAlpaca改学术论文、点评全球经济大势和读小说,都是一把好手,完胜Llama2。
两行代码和三个关键结论
Llama2可以说是AI社区内最强大的开源大模型之一,行业位置领先,LongAlpaca居然可以完胜。其背后的LongLoRA技术成功引起网友们的注意,到底是怎么做到的?
原来大语言模型对长文本处理过程中,计算量的主要开销集中在自注意力机制(self-attention),其开销随着文本长度成平方次地增加。
针对这个问题,研究团队提出LongLoRA技术,并用分组和偏移的方式来对全局自注意力机制进行模拟。
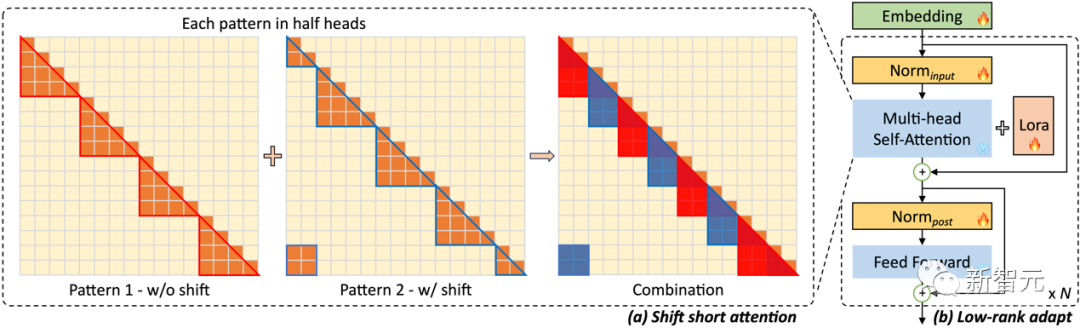
简单来说,就是将长文本对应的tokens拆分成不同的组,在每组内部做自注意力计算,而分组的方式在不同注意力头(attention head)上有所偏移。
这样的方式既可以大幅度节约计算量,又可以维持全局感受野的传递。
而且,这个实现方法也非常简洁,仅两行代码即可完成!

除此之外,LongLoRA还探索了低秩训练的方式。
原有的低秩训练方式,如LoRA[5],无法在文本长度迁移上取得良好的效果。
而LongLoRA在低秩训练的基础上,引入嵌入层(Embedding layer和 Normalization layers)进行微调,从而达到可以和全参数微调(Full fine-tune)逼近的效果。
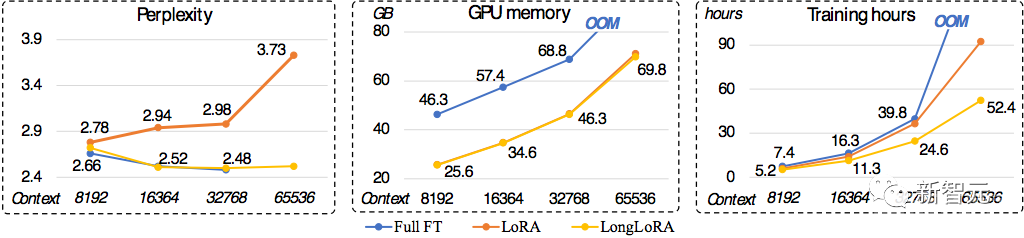
进行不同长度文本扩展和训练时,LongLoRA、LoRA和全参数微调不同技术的具体效果如何,可以参考三个维度表现:
在Perplexity-困惑度上,原有LoRA方法的性能在不断恶化,而LongLoRA和全参数微调都能在各种文本长度下维持很好的效果;
在显存消耗上,相比于全参数微调,LongLoRA和原有LoRA都有大幅度的节省。例如,对于8k长度的模型训练,相比于全参数微调,LongLoRA将显存消耗从46.3GB降低到25.6GB。
在训练时间上,对于64k长度的模型训练,相比于常规LoRA,LongLoRA将训练时间从90~100小时左右降低到52.4小时,而全参数微调超过1000小时。
极简的训练方法、极少的计算资源和时间消耗,以及极佳的准确性,令LongLoRA大规模推广成为可能。
目前,相关技术与模型已全部开源,感兴趣的用户们可以自己部署感受。
值得一提的是,这是贾佳亚团队继8月9日发布的「可以分割一切」的多模态大模型LISA后的又一力作。
相距不过短短两个月,不得不说,这研究速度和能力跟LongLoRA一样惊人。




还没有评论,来说两句吧...