

在时间序列问题中,有一种类型的时间序列不是等频采样的,即每组相邻两个观测值的时间间隔不一样。时间序列表示学习在等频采样的时间序列中已经进行了比较多的研究,但是在这种不规则采样的时间序列中研究比较少,并且这类时间序列的建模方式和等频采样中的建模方式有比较大的差别。
今天介绍的这篇文章,在不规则采样的时间序列问题中,探索了表示学习的应用方法,借鉴了NLP中的相关经验,在下游任务上取得了比较显著的效果。
 图片
图片
论文标题:PAITS: Pretraining and Augmentation for Irregularly-Sampled Time Series
下载地址:https://arxiv.org/pdf/2308.13703v1.pdf
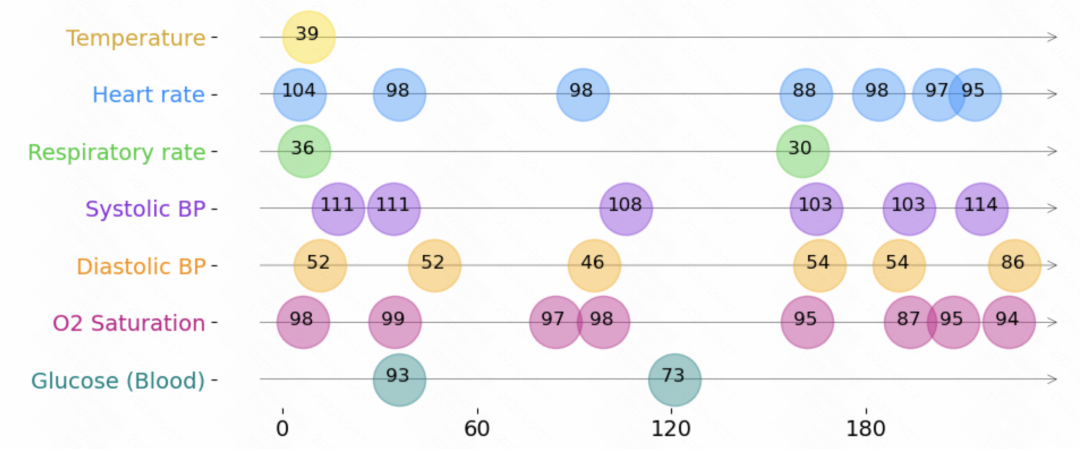
1、不规则时间序列数据定义
如下图是不规则时间序列数据的一个表示形式。每个时间序列由一组triplet组成,每个triple包括time、value、feature三个字段,分别表示时间序列中每个元素的采样时间、数值、其他特征。每个序列的信息除了刚才的triplet外,还包括其他不随时间变化的静态特征,以及每个时间序列的label。
 图片
图片
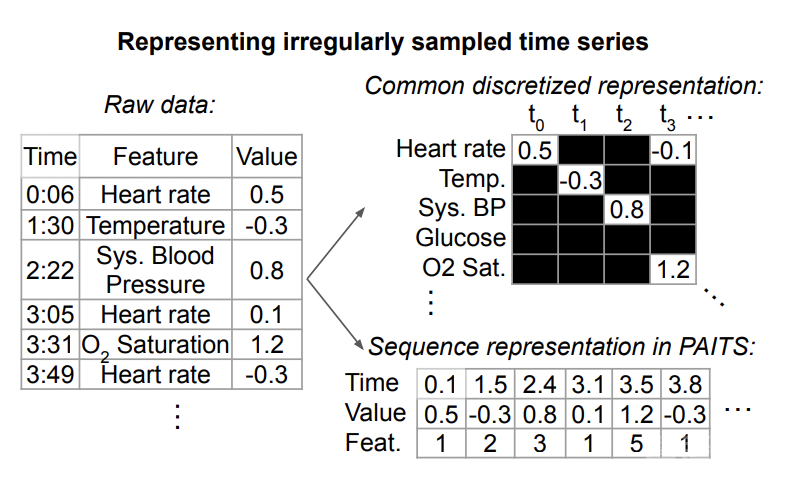
一般这种不规则时间序列建模方法,常见的结构是将上述triple数据分别embedding后,拼接到一起,输入到transformer等模型中,这种方式将每个时刻的信息,以及每个时刻的时间表征融合到一起输入到模型,进行后续任务的预测。
 图片
图片
在本文的任务中,使用的数据既包括这些有label的数据外,还包括无label的数据,用于做无监督预训练。
2、方法概览
本文的预训练方法借鉴了NLP中的经验,主要包括两个方面。
预训练任务的设计:针对不规则时间序列,设计合适的预训练任务,让模型从无监督数据中学到良好表征。文中主要提出了基于预测的预训练任务和基于重构的预训练任务。
数据增强方式设计:文中设计了用于无监督学习的数据增强方式,包括添加噪声、增加随机mask等方式。
此外,文中还提出了一种针对不同分布数据集,如何探索最优无监督学习方式的算法。
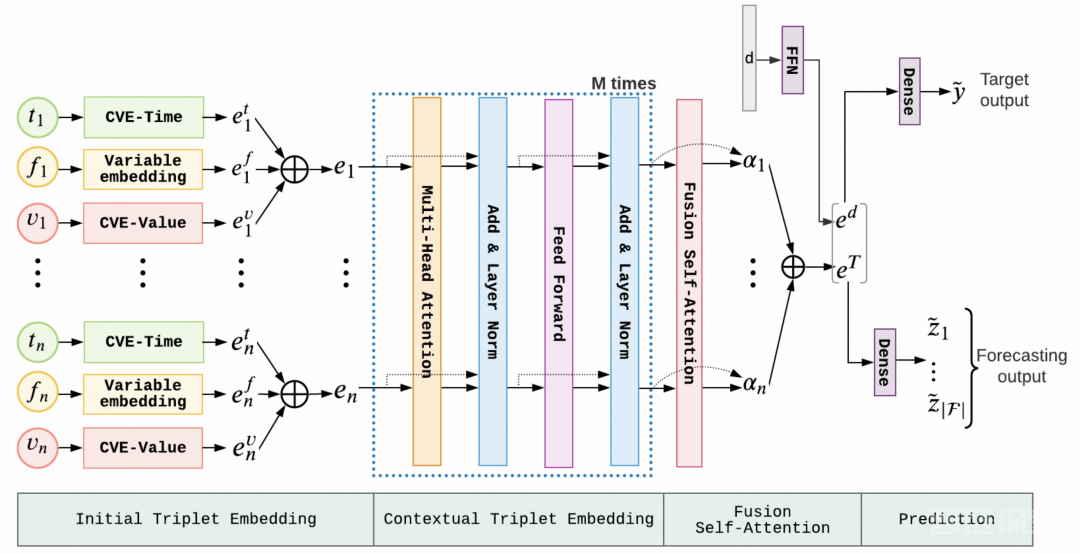
3、预训练任务设计
本文提出了两种不规则时间序列上的预训练任务,分别是Forecasting pretraining和Reconstruction pretraining。
在Forecasting pretraining中,对于时间序列中的每个特征,根据某个大小的时间窗口前序序列,预测它的取值。这里的特征指的是triplet中的feature。由于每种feature在一个时间窗口中可能出现多次,或者不会出现,因此文中采用了这个feature第一次出现的值作为label进行预训练。这其中输入的数据包括原始序列,以及增强后的时间序列。
在Reconstruction pretraining中,首先对于一个原始的时间序列,通过某种数据增强方式生成一个增强后的序列,然后用增强后的序列作为输入,经过Encoder生成表示向量,再输入到一个Decoder中还原原始的时间序列。文中通过一个mask来指导需要还原哪些部分的序列,如果这个mask都为1就是还原整个序列。
在得到预训练参数后,可以直接应用于下游的finetune任务,整个的pretrain-finetune流程如下图所示。
 图片
图片
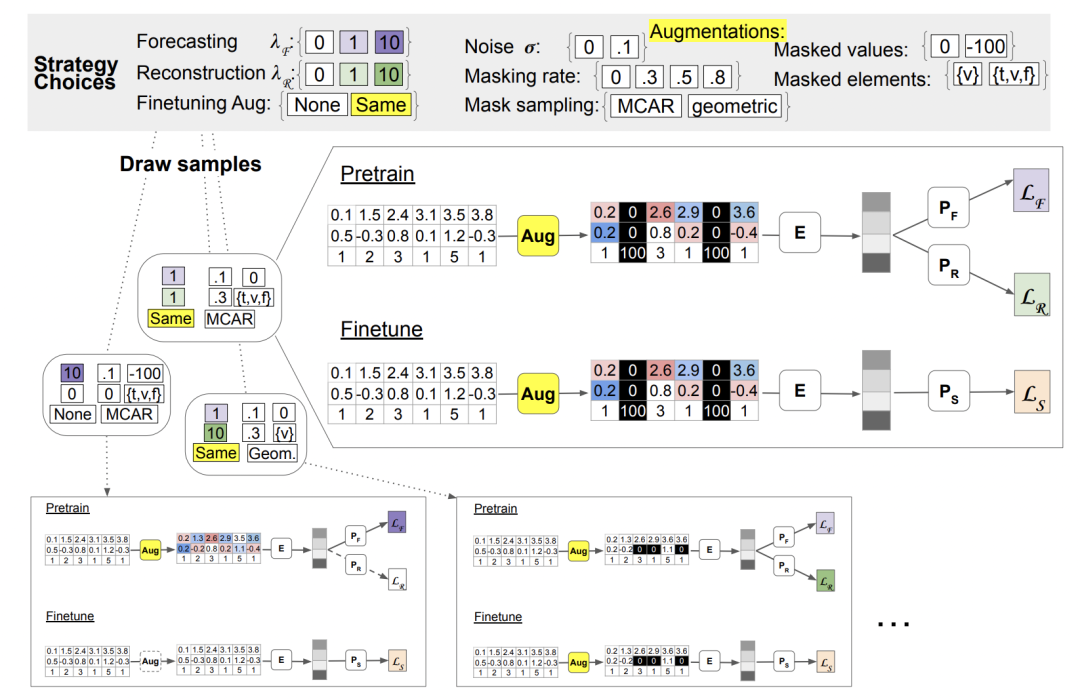
4、数据增强方式设计
文中设计了两种数据增强方式,一种是增加noise,一种是随机mask。
增加noise的方式,对原来序列的value或者time增加高斯噪声,计算方式如下:
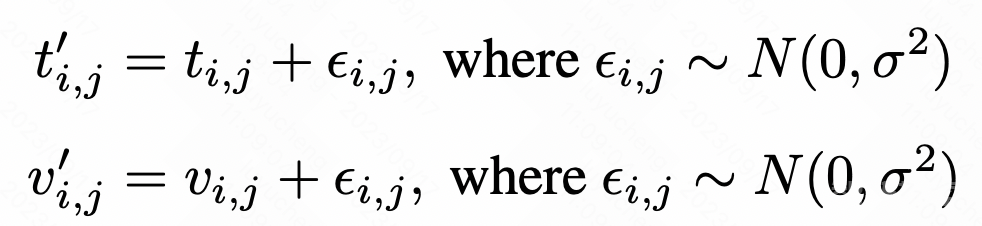 图片
图片
随机mask的方式借鉴了NLP中的思路,通过随机选择time、feature、value等元素进行随机mask和替换,构造增强后的时间序列。
下图展示了上述两种类型数据增强方法的效果:
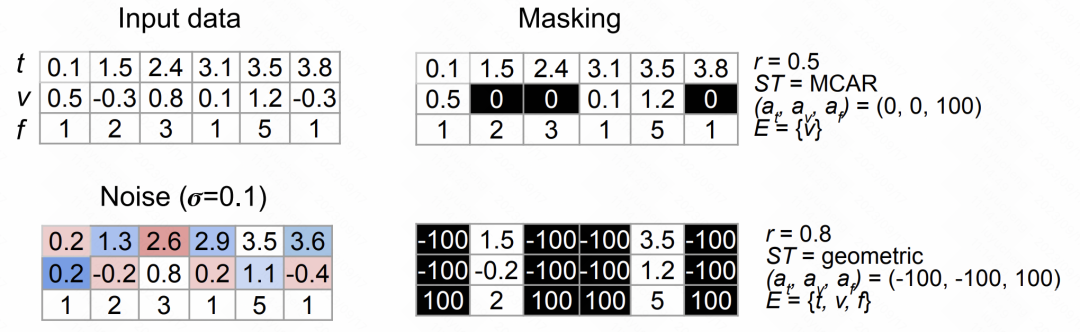 图片
图片
此外,文中将数据增强、预训练方式等进行不同组合,针对不同的时间序列数据,从这些组合中search到最优的预训练方法。
5、实验结果
文中在多个数据集上进行了实验,对比了多种预训练方法在不同数据集上的效果,可以看到文中提出的预训练方式在大多数数据集上都取得了比较显著的效果提升。
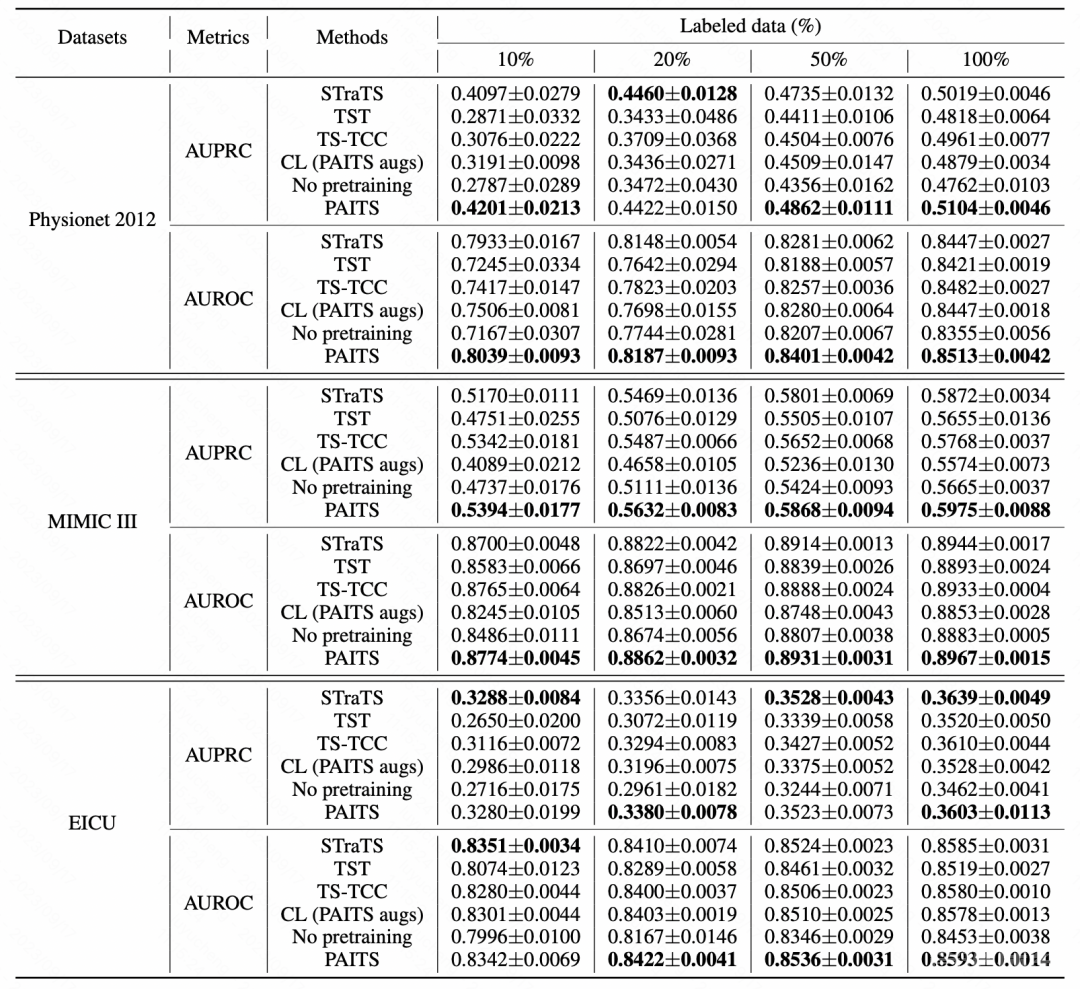




还没有评论,来说两句吧...