

一起来开个脑洞,如果诸葛亮穿越到《水浒传》的世界,他会成为谁?武松、宋江、还是吴用?这看似是一道文学题,但我们可以用数学方法来求解:诸葛亮 + 水浒传 - 三国演义 = ?
文字本身无法直接运算,但是如果把文字转换成数字向量,就可以进行计算了。而这个过程,叫做“向量嵌入”。

为什么要做Embedding?
因为具有语义意义的数据(如文本或图像),人类可以分辨它们的相关程度,但是无法量化,更不能直接计算。例如,对于一组词“诸葛亮、刘备、关羽、篮球、排球、羽毛球”,我们可能会把“诸葛亮、刘备、关羽”分成一组,“篮球、排球、羽毛球”分成另外一组。但如果进一步提问,“诸葛亮”是和“刘备”更相关,还是和“关羽”更相关呢?这很难回答。「而把这些信息转换为向量后,相关程度就可以通过它们在向量空间中的距离量化。」甚至于,我们可以做 诸葛亮 + 水浒传 - 三国演义 = ? 这样的脑洞数学题。
一、文字转为向量
要将文字转换为向量,首先是词向量模型,其中最具代表性的就是word2vec模型。该模型通过大量语料库训练,捕捉词汇之间的语义关系,使得相关的词在向量空间中距离更近。
1. word2vec的工作原理
(1) 词汇表准备:首先,构建一个包含所有可能单词的词汇表,并为每个词随机赋予一个初始向量。
(2) 模型训练:通过两种主要方法训练模型——CBOW(Continuous Bag-of-Words)和 Skip-Gram。
CBOW 方法:利用上下文(周围的词)预测目标词。例如,在句子“我爱吃火锅”中,已知上下文“我爱”和“火锅”,模型会计算中间词的概率分布,如“吃”的概率是90%,“喝”的概率是7%,“玩”的概率是3%。然后使用损失函数评估预测概率与实际概率的差异,并通过反向传播算法调整词向量模型的参数,使得损失函数最小化。
Skip-Gram 方法:相反,通过目标词预测它的上下文。例如,在句子“我爱吃火锅”中,已知目标词“吃”,模型会预测其上下文词,如“我”和“冰淇淋”。
2. 训练过程
我们可以将训练词向量模型的过程比作教育孩子学习语言。最初,词向量模型就像一个刚出生的孩子,对词语的理解是模糊的。随着父母在各种场景下不断与孩子交流并进行纠正,孩子的理解也逐渐清晰了,举个例子:
父母可能会说:“天黑了,我们要...”
孩子回答:“睡觉。”
如果答错了,父母会纠正:“天黑了,我们要开灯。”
这个过程中,父母不断调整孩子的理解和反应,类似于通过反向传播算法不断优化神经网络的参数,以更好的捕捉词汇之间的语义关系。
3. 代码实现
(1) 安装依赖
首先,安装所需的依赖库:
(2) 导入库
从 gensim.models 模块中导入 KeyedVectors 类,用于存储和操作词向量:
(3) 下载并加载词向量模型
https://github.com/Embedding/Chinese-Word-Vectors/blob/master/README_zh.md 下载中文词向量模型 Literature(文学作品),并加载该模型。
(4) 词向量模型的使用
词向量模型其实就像一本字典。在字典里,每个字对应的是一条解释;在词向量模型中,每个词对应的是一个向量。我们使用的词向量模型是300维的,为了方便查看,可以只显示前4个维度的数值。
输出结果如下:
二、计算余弦相似度
前面我们提出了疑问,“诸葛亮”是和“刘备”更相关,还是和“关羽”更相关呢?我们可以使用余弦相似度来计算。
输出结果如下:
看来,诸葛亮还是和刘备更相关。但是我们还不满足,我们还想知道,和诸葛亮最相关的是谁。
输出结果如下:
“诸葛亮”和“刘备”、“关羽”相关,这容易理解。为什么它还和“曹操”、“司马懿”相关呢?前面提到的词向量模型的训练原理解释,就是因为在训练文本中,“曹操”、“司马懿”经常出现在“诸葛亮”这个词的上下文中。这不难理解——在《三国演义》中,诸葛亮经常与曹操和司马懿进行智斗。
三、测试词向量模型
前面提到,训练词向量模型是为了让语义相关的词在向量空间中距离更近。那么,我们可以测试一下,给出四组语义相近的词,考一考词向量模型,看它能否识别出来。
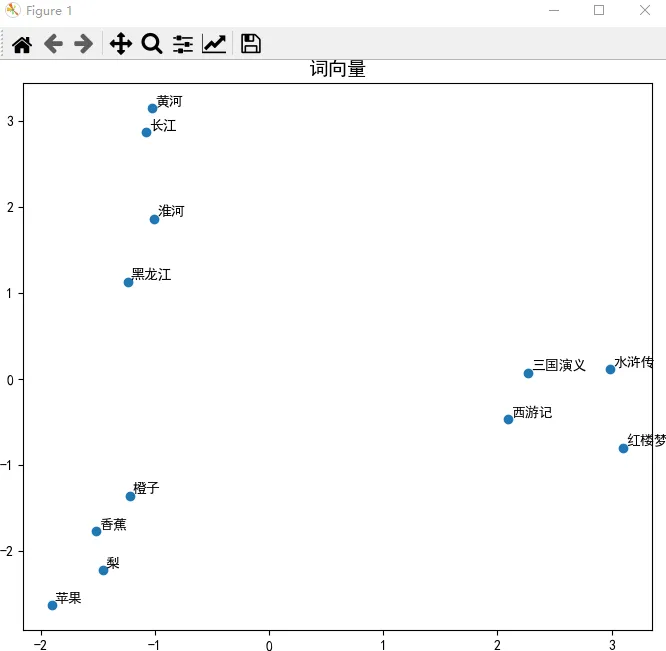
第一组:西游记、三国演义、水浒传、红楼梦
第二组:苹果、香蕉、橙子、梨
第三组:长江、黄河、淮河、黑龙江
首先,获取这四组词的词向量:
然后,使用 PCA (Principal Component Analysis,主成分分析)把200维的向量降到2维,一个维度作为 x 坐标,另一个维度作为 y 坐标,这样就把高维向量投影到平面了,方便我们在二维图形上显示它们。换句话说,PCA 相当于《三体》中的二向箔,对高维向量实施了降维打击。
最后,在二维图形上显示降维后的向量。
从图中可以看出,同一组词的确在图中的距离更近。
四、测试词向量模型
前面提到,训练词向量模型是为了让语义相关的词在向量空间中距离更近。那么,我们可以测试一下,给出四组语义相近的词,考一考词向量模型,看它能否识别出来。
假设我们想看看如果诸葛亮穿越到《水浒传》的世界,他会成为谁。我们可以用以下公式表示:诸葛亮 + 水浒传 - 三国演义。
计算结果如下:
你可能会感到惊讶,因为结果中的“刘备”、“刘邦”和“孔明”并不是《水浒传》中的人物。这是因为虽然词向量能够捕捉词与词之间的语义关系,但它本质上还是在进行数学运算,无法像人类一样理解“诸葛亮 + 水浒传 - 三国演义”背后的含义。结果中出现“刘备”、“刘邦”和“孔明”是因为它们与“诸葛亮”在向量空间中距离较近。
这些结果展示了词向量模型在捕捉词语之间关系方面的强大能力,尽管有时结果可能并不完全符合我们的预期。通过这些例子,我们可以更好地理解向量嵌入在自然语言处理中的应用。
五、一词多义如何解决?
前面提到,词向量模型就像是一本字典,每个词对应一个向量,而且是唯一一个向量。
然而,在语言中,一词多义的现象非常常见。例如:“小米”既可以指一家科技公司,也可以指谷物。词向量模型在训练“小米”这个词的向量时,会考虑这两种含义,因此它在向量空间中会位于“谷物”和“科技公司”之间。
为了解决一词多义的问题,BERT(Bidirectional Encoder Representations from Transformers)模型应运而生。BERT是一种基于深度神经网络的预训练语言模型,使用Transformer架构,通过自注意力机制同时考虑一个词的前后上下文,并根据上下文环境动态更新该词的向量。
例如,“小米”这个词的初始向量是从词库中获取的,向量的值是固定的。当BERT处理“小米”这个词时,如果上下文中出现了“手机”,BERT会根据“手机”这个词的权重,调整“小米”的向量,使其更靠近“科技公司”的方向。如果上下文中有“谷物”,则会调整“小米”的向量,使其更靠近“谷物”的方向。
BERT的注意力机制是有策略的,它只会给上下文中与目标词关系紧密的词分配更多权重。因此,BERT能够理解目标词与上下文之间的语义关系,并根据上下文调整目标词的向量。
BERT的预训练分为两种方式:
掩码语言模型(Masked Language Model,MLM):类似于word2vec,BERT会随机遮住句子中的某些词,根据上下文信息预测被遮住的词,然后根据预测结果与真实结果的差异调整参数。
下一句预测(Next Sentence Prediction,NSP):每次输入两个句子,判断第二个句子是否是第一个句子的下一句,然后根据结果差异调整参数。
接下来,我们通过实际例子来验证BERT的效果。
1. 使用BERT模型
首先,导入BERT模型,并定义一个获取句子中指定单词向量的函数:
接下来,通过BERT和词向量模型分别获取两个句子中指定单词的向量:
最后,查看这三个向量的区别:
输出结果如下:
BERT模型果然能够根据上下文调整单词的向量。让我们进一步比较它们的余弦相似度:
输出结果如下:
观察结果发现,不同句子中的“苹果”语义果然不同。BERT模型能够根据上下文动态调整词向量,而传统的词向量模型则无法区分这些细微的语义差异。
六、获得句子的向量
我们虽然可以通过 BERT 模型获取单词的向量,但如何获得句子的向量呢?最简单的方法是计算句子中所有单词向量的平均值。然而,这种方法并不总是有效,因为它没有区分句子中不同单词的重要性。例如,将“我”和“亿万富翁”两个词的向量平均,得到的结果并不能准确反映句子的实际含义。
因此,我们需要使用专门的句子嵌入模型来生成更准确的句子向量。BGE_M3 模型就是这样一种嵌入模型,它能够直接生成句子级别的嵌入表示,更好地捕捉句子中的上下文信息,并且支持中文。
1. 使用 BERT 模型获取句子向量
首先,定义一个使用 BERT 模型获取句子向量的函数:
2. 使用 BGE_M3 模型获取句子向量
安装 pymilvus.model 库:
然后,定义一个使用 BGE_M3 模型获取句子向量的函数:
3. 比较两种方法的效果
接下来,我们通过实际例子来比较这两种方法的效果。
(1) 使用 BERT 模型
首先,计算 BERT 模型生成的句子向量之间的余弦相似度:
输出结果如下:
从结果可以看出,BERT 模型将前两个句子的相似度计算得较高,而将第三个句子与前两个句子的相似度也计算得较高,这并不符合我们的预期。
(2) 使用 BGE_M3 模型
接下来,计算 BGE_M3 模型生成的句子向量之间的余弦相似度:
输出结果如下:
从结果可以看出,BGE_M3 模型能够更好地区分句子的语义,前两个句子的相似度较高,而第三个句子与前两个句子的相似度较低,这更符合我们的预期。




还没有评论,来说两句吧...