

Scaling Law 最近被业内不少人士唱衰,一方面以OpenAI为代表大模型厂商们,基本上还是围绕着GPT-4在探索周边,虽说不是原地打转,但单就性能提升而言,就连OpenAI自家的员工都爆料说非常有限。
1.OpenAI内部人士:Orion性能提升遇到瓶颈
昨天,外媒媒体曝出消息称,奥特曼一直吊胃口的下一代模型“Orion”,也被自家的两位知情人士,坦承:GPT-4与Orion之间的质量差距明显小于GPT-3与GPT-4之间的差距,并透露截止到夏末,Orion在回答未经训练的编码问题时表现不佳,仅在语言处理能力方面显示出提升。
这可影响大了,业界都在向着OpenAI学习、追赶,OpenAI的放缓自然也就意味着大模型进展在放缓。
其实,不止这些头部的模型厂商面临着规模定律的扩大困境,就连算力有限,只能量化做小模型(例如只有1bit参数的BitNet,再有业内很多基于Llama做量化的小模型)的那些机构同样也面临着困境。
那接下来大模型的大小厂商们还能怎么走?除了o1的“慢思考推理”、强化学习外,规模定律短期还有别的出路吗?
2.新规模定律来了
答案终于来了!
最近,哈佛、斯坦福大学发表了一篇研究论文《Scaling Laws of Precision》掀起了AI圈不小的波澜,得到了许多研究人士的疯狂转发与讨论。
 图片
图片
论文中,研究人员进行了一项新研究,指出精度(即模型中用于表示数字的比特数)在模型扩展规律中比之前认为的更为重要,可以显著影响语言模型的性能。
研究人员指出,在以往描述模型性能随参数量和训练数据量变化的扩展规律基本忽略了精度这一因素。
3.大模型已经被过度训练,Llama3越来越难以量化
论文作者之一Kumar指出了两点,一点是基于Llama3的量化越来越难,第二点则是发现提高数据精度可以提高量化的性能。
“由于模型在大量数据上过度训练,因此训练后量化变得更加困难,因此,如果在训练后量化,最终原来更多的预训练数据可能会造成危害!在预训练期间以不同的精度放置权重、激活或注意力的效果是一致且可预测的,并且拟合缩放定律表明,高精度(BF16)和下一代精度(FP4)的预训练可能都是次优的设计选择!”
 图片
图片
具体实验上,研究团队进行了超过465次训练,测试不同精度(3到16位)对模型的影响。实验使用的语言模型规模达到17亿参数,训练数据量达260亿个tokens。研究发现,过度训练的模型在训练后对量化处理更为敏感。模型如果在训练数据量远超“Chinchilla最优”值20倍时,即被视为过度训练,这次实验测试的比率达到了1000倍。
研究人员首先对训练后量化模型权重的常用技术进行了研究,发现训练时间越长/预训练期间用到的数据越多,模型对推理时的量化就越敏感,这解释了为什么 Llama-3 可能更难量化。
“事实上,这种损失下降大致是预训练期间的token/参数比率的幂律,因此你可以提前预测临界数据大小,如果你正在为量化模型提供服务,则超过该临界数据大小,对更多数据进行预训练将会产生积极影响。”
“直觉可能是,随着你在更多数据上进行训练,越来越多的知识被压缩为权重,给定的扰动将对性能造成更大的损害。 ”
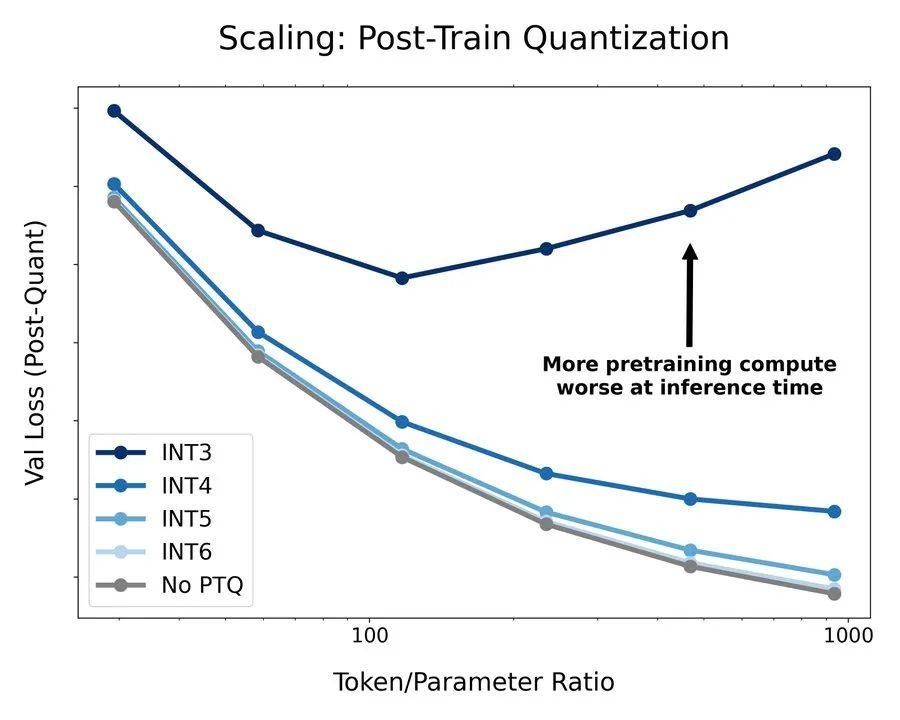
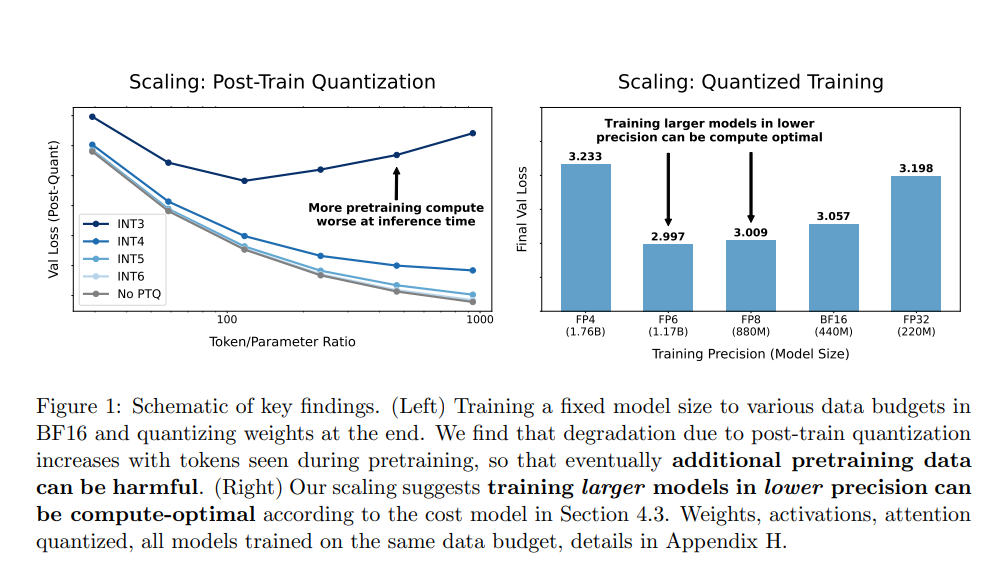
下面是一个固定语言模型,该模型对各种数据预算进行了过度训练,最高可达 300 亿个 token,之后进行训练后量化。这表明,更多的预训练 FLOP 并不一定能带来更好的生产模型。具体的实验数字和图示如下:
 图片
图片
(左)以固定的模型大小,针对不同的数据量在BF16精度下进行训练,并在最后对权重进行量化。研究发现,由于训练后量化所导致的性能下降会随着预训练期间观察到的标记(token)数量的增加而增加,因此,最终额外的预训练数据可能会产生负面影响。
(右)我们的扩展研究表明,根据论文中的成本模型,以较低的精度训练更大的模型可能是计算上最优的选择。权重、激活值、注意力机制均进行了量化,所有模型均在同一数据量下进行训练,具体细节见附录H。
然后该研究将注意力转向低精度训练,主要研究量化感知训练(仅权重)和低精度训练。该研究将模型分解为权重、激活和 KV 缓存,找到其中任何一个量化到任意精度时损失的 Scaling Law,并开发一种组合且可解释的函数形式来预测在预训练期间,量化这三者的任意组合对损失的影响。
4.新Scaling Law:精度扩展定律
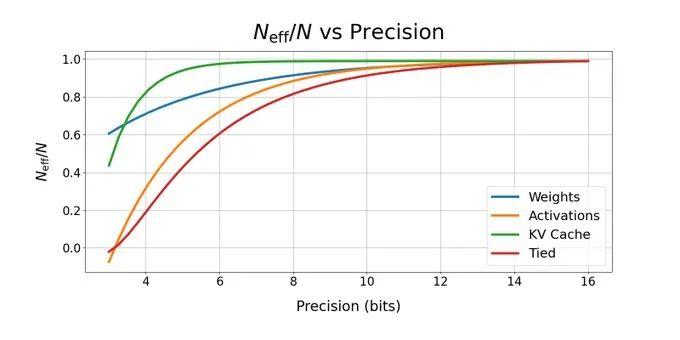
作者介绍道,新发现的精度扩展定律依赖于“有效参数数量”的概念,“我们假设它是在固定数量的真实参数下降低精度时减少的数量,因此在 FP4 中训练的 10 亿参数模型具有与 BF16 中的 2.5亿参数模型相当的‘有效参数’数量。”
虽然权重可以在低精度下训练而不会出现问题,但激活和 KV 缓存却很敏感。下面是标准化的“有效参数计数”,作为每个(权重、激活、KV 缓存)的精度函数,以及当它们都保持相同精度(绑定)时,基于我们的拟合。
 图片
图片
实验还揭示了基于新扩展规律的计算最优精度。研究表明,当模型参数、数据和精度联合优化时,这一最优精度通常独立于计算预算。划重点:下面的结论很重要——
首先,通过实验,研究人员制定了新的精度缩放定律。另一项重要发现则提出了预训练期间计算的最优精度。根据该研究,当同时优化参数数量、数据和精度时,这一精度通常与计算预算无关。
其次,普遍采用的16位模型训练法并非最优,因为很多位是多余的。然而,使用4位进行训练则需要不成比例地增加模型大小,以维持损失缩放。研究人员的计算表明,对于较大的模型而言,7-8位是计算最优的。
但是,当模型大小从一开始就固定时,情况就会发生变化:更大且训练更好的模型应以更高的精度进行训练——例如,使用16位的Llama 3.1 8B模型。
然而,实际的计算节省还取决于硬件对更低精度的支持。此外,这里研究的模型(参数最多达17亿个)尚未在最大的实际规模上进行测试。不过,这些一般趋势仍然适用于更大的模型。
5.写在最后OpenAI或转向专有模型或应用
正如文章开头提到的,OpenAI难产的下一代大模型,如果按照此前的设想,将会面临短期难以克服的困难:模型的参数规模没有更大的算力储备,即便储备充足,这一新模型也会在数据中心的运行成本只会更加昂贵,再者还有一个硬伤:
这也是OpenAI内部研究人员指出的,高质量训练数据的缺乏是性能提升放缓的原因之一,因为大部分公开的文本和数据已被使用。为此,OpenAI创建了一个由Nick Ryder领导的“基础团队”(Foundations Team),以应对数据资源短缺问题。
这些都需要大量的时间等待去补足。
而哈佛、斯坦福的这篇研究也被很多AI圈人士看好,比如知名AI研究员Tim Dettmers,认为这些结果揭示了量化的局限性。他预计,随着低精度带来的效率提升达到极限,将出现从纯规模扩张向专用模型和人本应用的转变。
简单理解,就是纯规模扩张的量化模型已迎来瓶颈,专用模型势必在接下来一年大放异彩。




还没有评论,来说两句吧...