

工具调用是 AI 智能体的关键功能之一,AI 智能体根据场景变化动态地选择和调用合适的工具,从而实现对复杂任务的自动化处理。例如,在智能办公场景中,模型可同时调用文档编辑工具、数据处理工具和通信工具,完成文档撰写、数据统计和信息沟通等多项任务。
业界已发布的工具调用模型,在特定评测基准上有接近甚至超越闭源 SOTA 模型(比如 GPT-4)的表现,但在其他评测基准上下降明显,难以泛化到新工具和新场景。为应对这一挑战,来自 OPPO 研究院和上海交通大学的研究团队提出函数掩码(Function Masking) 方法,构建了具备强大泛化能力的轻量化工具调用系列模型:Hammer,并开源了完整的技术栈,旨在帮助开发者构建个性化的终端智能应用。
在工具调用典型评测基准上,包括 Berkeley Function-Calling Leaderboard(BFCL)、API-Bank、Seal-Tools 等,Hammer 系列模型展现了出色的总体性能,特别是 Hammer-7B 模型,综合效果仅次于 GPT-4 等闭源大模型,在工具调用模型中综合排名第一,具备强大的新场景和新工具泛化能力。

模型地址:https://huggingface.co/MadeAgents
论文地址:https://arxiv.org/abs/2410.04587
代码地址:https://github.com/MadeAgents/Hammer
工具调用任务说明
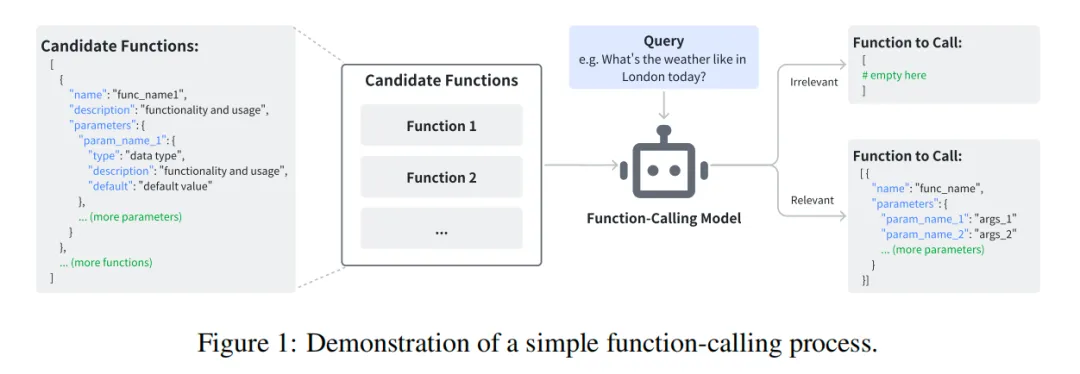
工具调用作为 AI 智能体执行复杂任务所必备的核心能力,要求模型不仅能够识别正确的函数,还要准确填写函数的输入参数;如果给定函数列表无法满足用户的意图,模型也应具备拒绝任务的能力。下图是工具调用模型输入输出的一个样例:
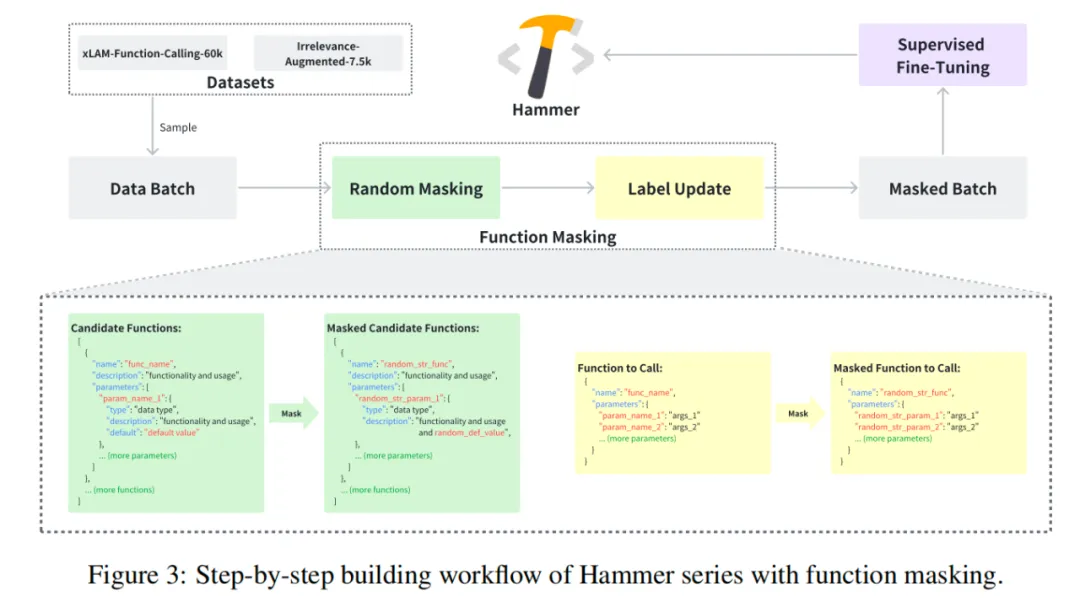
Hammer 训练方法
研究团队在 Hammer 的训练过程中引入了一项关键技术:函数掩码(Function Masking) 和一个增强数据集:不相关性检测增强数据集(Irrelevance-Augmented Dataset)。
函数掩码旨在减少模型对函数名称和参数名称的依赖,核心是通过哈希化函数名称和参数名称,使模型在执行工具调用任务时不得不依赖更完备且可靠的功能描述信息,而不是对名称的记忆或匹配。这种方式有助于减少因命名差异导致的误判问题,提升模型在多样化命名风格和应用场景中的稳定性和适应性。
不相关性检测增强数据集旨在帮助模型在给定用户意图而当前无适用函数的情况下,能够正确判断并给出「不相关」信号。该数据集包含了 7,500 个增强样本,设计时平衡了工具调用任务和不相关性检测任务的比例,以达到最佳的综合效果。(已开源至:https://huggingface.co/datasets/MadeAgents/xlam-irrelevance-7.5k)
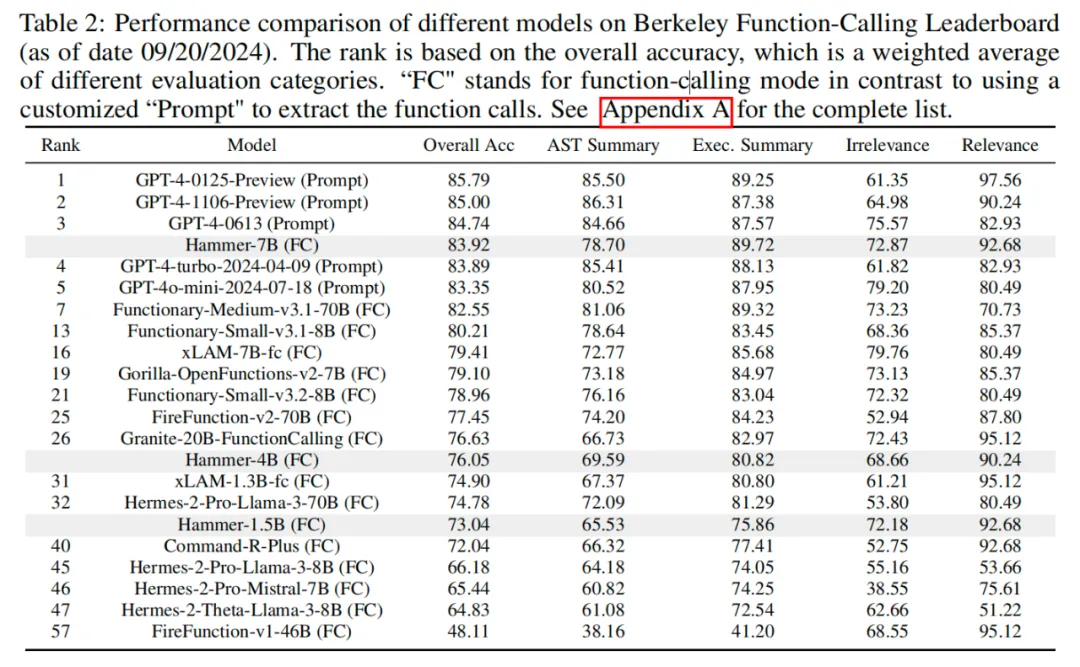
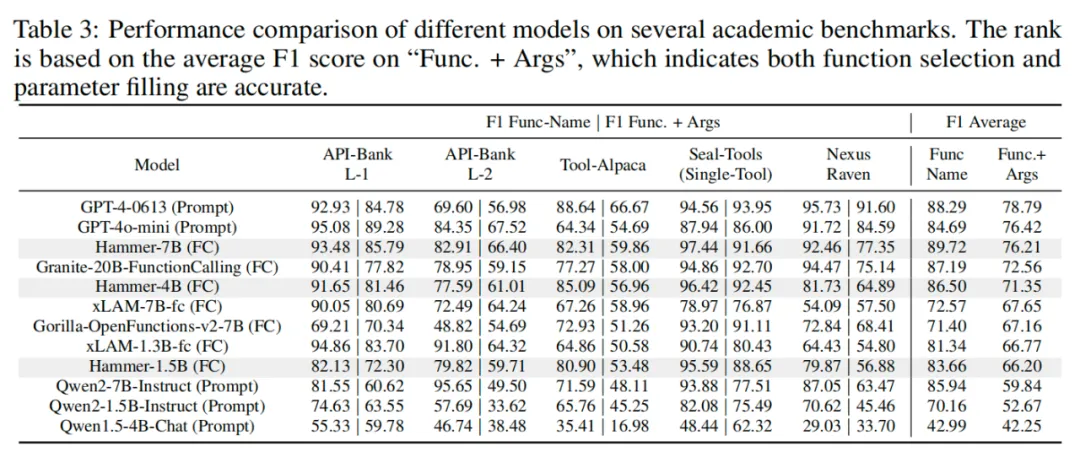
Hammer 总体表现
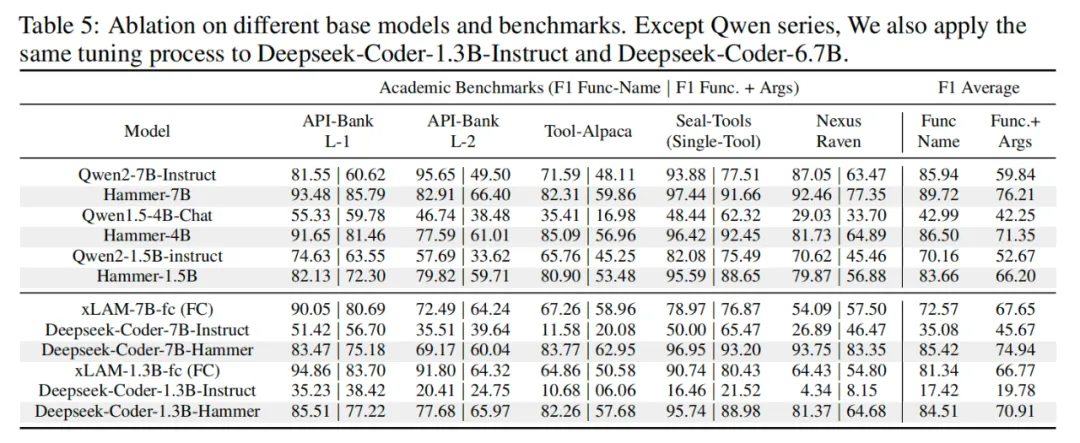
Hammer 系列模型在工具调用典型评测基准上均展现了出色的性能,具体表现如下面的两张表格所示。可以看到,在 BFCL 榜单上,Hammer-7B 模型的总体准确率达到 83.92%,接近闭源 SOTA 模型 GPT-4 的 95.79%,优于其他工具调用模型。同时,在其他评测基准上,Hammer-7B 模型的平均 F1 达到 76.21%,接近闭源模型 GPT-4 的 78.79%,大幅领先其他工具调用模型。Hammer-7B 能够在参数规模较小的情况下,在不同评测基准上与闭源 SOTA 大模型竞争,充分展示了 Hammer 模型在各种工具调用任务中的准确性和稳定性。
函数掩码技术的通用性
研究团队还将函数掩码和数据增强技术应用于不同的基础模型,以验证其通用性。实验选择了 Qwen 系列和 Deepseek-Coder 系列模型作为基准,并在相同的训练和测试条件下进行比较。下表中的结果显示,经过函数掩码技术调优后的 Hammer 版本显著提升了基础模型的工具调用准确性,远高于未调优版本,证明了函数掩码和不相关性数据增强对不同模型架构均有显著的优化效果。同时,在使用相同的基座模型和基础数据的情况下,与 xLAM(同样基于 Deepseek 微调而来的工具调用模型)的对比,也体现了函数掩码及不相关性数据增强的作用。
不相关性数据增强比例的权衡
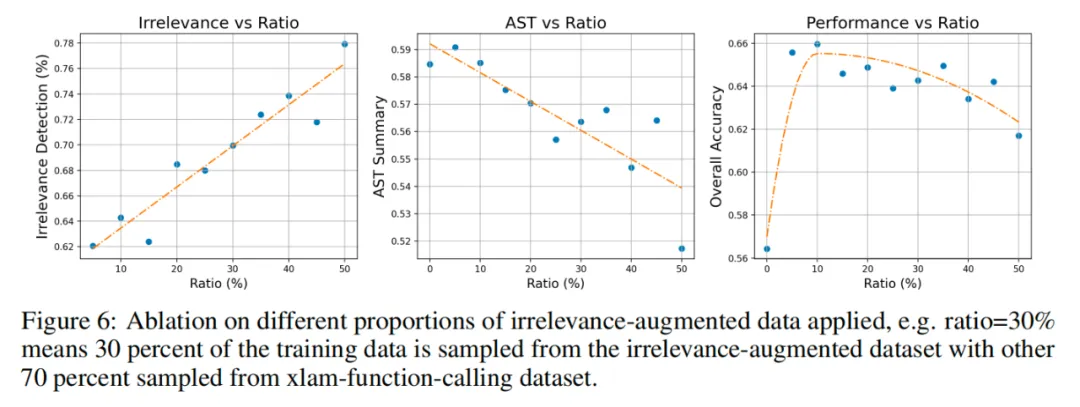
在设计不相关性数据增强时,研究团队测试了不同比例的不相关性数据样本对模型表现的影响。下图实验结果表明,合理比例的不相关性增强数据(约占总数据的 10%)能够在提升工具调用准确性的同时,显著增强模型在不相关检测场景中的识别能力,降低错误调用的风险。实验结果还显示,进一步增加不相关性数据会略微降低功能调用的准确性,因此找到适当的平衡点至关重要。
总结
Hammer 模型通过函数掩码技术和不相关性检测数据增强,在多个评测基准中取得了良好的效果,表现出强大的泛化能力和稳定性,为轻量化工具调用模型在终端应用向前迈了一步。
Hammer 系列目前已更新至 2.0 版本,欢迎感兴趣的读者通过 huggingface 进行体验!




还没有评论,来说两句吧...