

这是7月份采用大语言模型研究自动驾驶的论文“Drive Like a Human: Rethinking Autonomous Driving with Large Language Models“,来自上海AI实验室和华东师范。
本文探讨用大型语言模型(LLM)以类似人类的方式理解驾驶环境的潜力,并分析其在面对复杂场景时的推理、解释和记忆能力。传统的基于优化和模块化的自动驾驶(AD)系统在处理长尾极端情况时面临固有的性能限制。为了解决这个问题,作者思考一个理想的AD系统应该像人一样驾驶,通过连续驾驶积累经验,用常识解决问题。为了实现这一目标,确定AD系统所需的三个关键能力:推理、解释和记忆。通过构建闭环系统来展示LLM在驾驶场景中使用LLM的可行性,展示其理解和环境交互能力。
如图就是GPT-3.5 在 高速环境中进行闭环驾驶的示意图:(a) GPT-3.5 用感知工具观察高速环境并做出控制车辆的决策,形成闭环。(b) GPT-3.5 采用 ReAct 策略(来自论文“React: Synergizing reasoning and acting in language models”. arXiv 2210.03629)来规划动作和使用工具,同时通过思考、行动和观察的循环来感知周围环境。
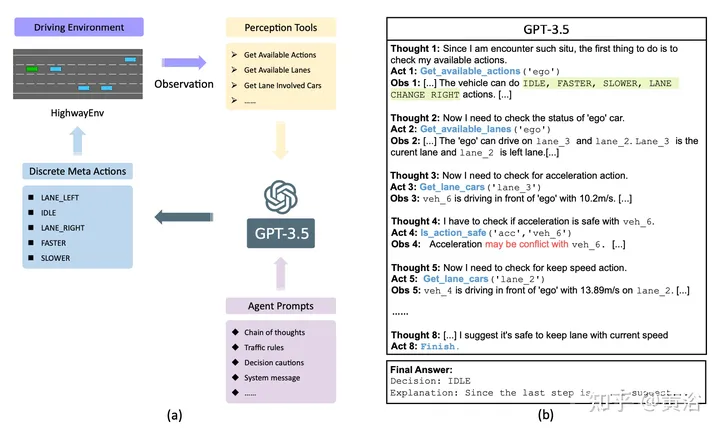
与人类一样,GPT-3.5 在驾驶时评估其行为的潜在后果,并权衡结果以做出最明智的决定。与广泛使用的基于强化学习 (RL) 和基于搜索的方法不同,GPT-3.5 不仅可以解释场景和操作,还可以利用常识来优化其决策过程。
与基于 RL 的方法相比,GPT-3.5 在 高速环境中实现了超过 60% 的零样本通过率,无需任何微调。相比之下,基于 RL 的方法严重依赖多次迭代来实现有竞争力的性能。例如,如图(a)所示,由于碰撞受到严厉惩罚,基于RL的智体学习了一种策略,为了防止碰撞,在开始时减速,为随后的加速创造广阔的空间。这表明基于RL的方法经常产生这种意想不到的解决方案。基于搜索的方法通过优化目标函数来做出决策,忽略函数中未提及的未定义部分。如图(b)所示,基于搜索的智体可能会表现出激进的变道行为以实现高驾驶效率,从而增加碰撞风险。此外,即使没有其他车辆在前方,基于搜索的方法也可能进行无意义的变道操作。这可能是因为,对于基于搜索的智体来说,在安全的前提下,变道和保持速度在目标功能中具有同等的优先级。因此,智体随机选择其中一个操作。
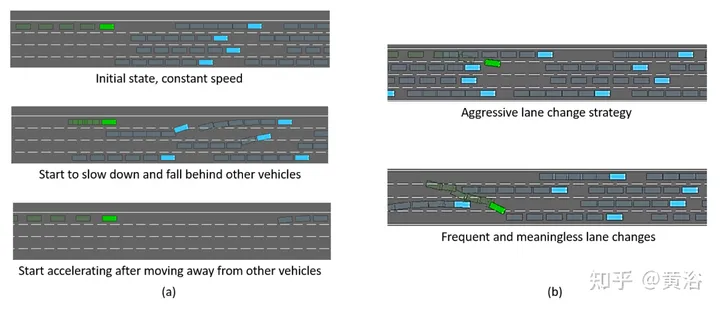
总之,基于RL和基于搜索的方法都不能真正像人类一样思考和驾驶,因为缺乏常识、解释场景以及权衡利弊的能力。相比之下,GPT-3.5 可以解释每个动作的后果,通过提供提示,可以使 GPT-3.5 以价值为导向、并做出更像人类的决策。
虽然人类驾驶员和以前基于优化的AD系统都拥有基本的驾驶技能,但根本区别在于人类对世界有常识性的理解。常识是,从日常生活中积累的对周围发生的事情做合理而实用的判断[11]。有助于驾驶的常识可以从日常生活的各个方面得出。当出现新的驾驶情况时,人类驾驶员可以根据常识快速评估场景并做出合理的决定。相比之下,传统的AD系统可能在驾驶领域有经验,但缺乏常识,因此无法应对这种情况。
像GPT-3.5这样的LLM已经接受了大量自然语言数据的训练,并且对常识了如指掌[2]。这标志着与传统AD方法的重大背离,使LLM能够像人类驾驶员一样用常识推理复杂的驾驶场景。
如图所示,两张相似但不同的照片被输入LLM。第一张照片描绘了一辆皮卡车在卡车车厢里携带几个交通锥前往目的地。第二张照片还描绘了一辆皮卡的卡车车厢里有交通锥,但周围地面上散落着其他交通锥。由于 GPT-3.5 缺乏处理包括图像在内的多模态输入的能力,文中用 LLaMA-Adapter v2 视觉指令模型(来自论文“Llama-adapter v2: Parameter-efficient visual instruction model“,arXiv 2304.15010)作为图像处理前端。指示LLaMA Adapter尽可能详细地描述照片。然后将此描述用作观察,要求 GPT-3.5 评估该场景是否具有潜在危险,并为假设跟随卡车的自车做出决定。在图(a)中描述的第一个案例中,LLaMA-Adapter识别出照片中的皮卡车携带多个交通锥,并推断它可能正在将它们运送到目的地。基于这些观察结果,GPT-3.5 成功分析了驾驶场景。GPT-3.5 没有被交通锥的存在所误导,而是认为这种情况是无害的,基于卡车将货物运送到目的地是很常见的。GPT-3.5 建议自车没有必要减速,并警告说不必要的减速可能对交通流量造成危险。对于图(b)中描述的第二个案例,交通锥不仅在卡车车厢内,而且散落在地面上,用LLaMA-Adapter准确表示这个内容。尽管与第一个案例略有不同,但 GPT-3.5 的反应截然相反。它认为这种情况具有潜在的危险,因为卡车周围散落的交通锥,并建议自车减速并保持一定距离,避免与这些交通锥发生任何碰撞。

以上的例子展示了LLM在驾驶场景中强大的零样本理解和推理能力。利用常识知识,不仅让LLM能够更好地理解场景中的语义信息,还能让其做出更理性的决策,更符合人类的驾驶行为。因此,拥有常识知识可以提高自动驾驶系统能力的上限,使其能够处理未知的长尾情况,真正接近人类驾驶员的驾驶能力。
持续学习[28]是人类驾驶的另一个关键方面。新手司机在遇到复杂的交通状况时,由于经验有限,通常会谨慎驾驶。随着时间的推移,随着驾驶经验的积累,驾驶员会遇到新的交通场景,发展新的驾驶技能,并巩固他们以前的经验,最终成为经验丰富的驾驶员。基于优化的方法旨在通过获取越来越多的失败案例并重新训练神经网络来模仿持续学习的过程。然而,这种方法不仅乏味且昂贵,而且从根本上无法实现持续学习。常规驾驶和长尾极端情况案例之间的分布差异对平衡两者构成了重大挑战,最终导致“灾难性遗忘”。因此,需要一种更有效的方法来实现自动驾驶系统中真正的持续学习。
下图给出了记忆过程的示例。该场景涉及一辆蓝色自车和一辆黄车在一条略宽于汽车两倍的狭窄车道上在相反方向相遇。将场景转换为结构化文本输入GPT-3.5后,模型很好地理解了场景,包括车辆的状态、方向和目的地。然而,当要求它对场景做出决定时,GPT-3.5 给出了一个安全但过于谨慎的建议,即自车应该停下来等待另一辆车先通过。为了提高LLM的性能,专家就人类驾驶员如何处理这种情况提供了实用的建议,其中包括保持汽车移动并将其稍微向左轻推。LLM然后认识到有足够的空间让两辆车通过,减速可能会扰乱交通流量。它将情况总结为“同一车道上的两辆车相互靠近”,并记录记忆以及正确的决定。利用这些记忆,输入了另一个场景,即两辆车以不同的速度和位置在狭窄的小巷中相遇,并要求LLM做出决定。LLM成功地认识到这只是“同一车道上的两辆车相互靠近”决策场景的另一种变型,并建议自车继续行驶而不需减速等待,是一种安全的办法。
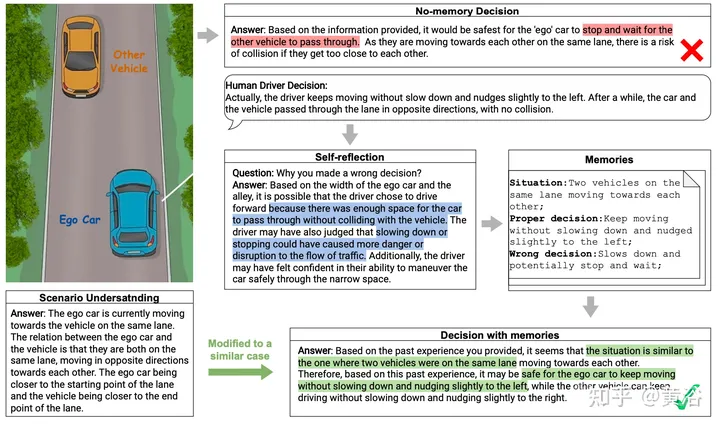
记忆能力不断收集驾驶案例以获得经验,并通过检索现有记忆来辅助决策,赋予LLM在自动驾驶领域的持续学习能力。此外,这大大降低了LLM在类似情况下的决策成本,并提高了其实际性能。




还没有评论,来说两句吧...