

本文第一作者陈谋祥是浙江大学计算机四年级博士生,研究方向为时间序列预测、LLM 代码生成和无偏排序学习。通讯作者刘成昊是 Salesforce 亚洲研究院高级科学家,曾提出时序预测基础模型 Moirai。该工作由浙江大学、道富科技和 Salesforce 共同完成。
机器之心曾在两个月前报道过,大语言模型(LLM)用于时序预测真的不行,连推理能力都没用到。近期,浙大和 Salesforce 学者进一步发现:语言模型或许帮助有限,但是图像模型能够有效地迁移到时序预测领域。
他们提出的 VisionTS 时序预测框架,基于何恺明的代表作 ——MAE 模型。VisionTS 仅从自然图像(ImageNet)中预训练而无需时间序列微调,即可直接跨界比肩(甚至超越)一众强大的时序预测基础模型,如 Moirai 和 TimesFM 等,而这些基础模型均使用了大量时间序列数据预训练。
这篇论文证明了:计算机视觉和时间序列这两个看似风马牛不相及的领域,可能具有密切联系。其实,这也符合人类的习惯:我们很难从一串数字序列直接看出规律,但如果将其转成一张时序趋势图,就能更容易地从中看出图片变化的规律。

论文题目:VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
论文地址:https://arxiv.org/abs/2408.17253
代码仓库:https://github.com/Keytoyze/VisionTS
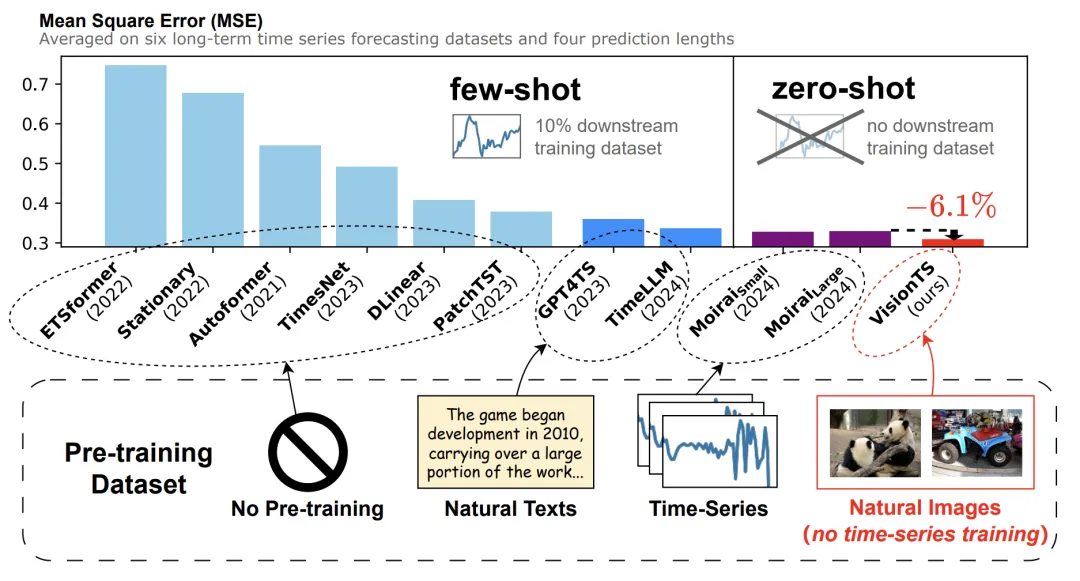
图一:VisionTS 无需时序数据微调,即可在零样本情况下超越最大的时序基础模型 Moirai。
近年来,预训练基础模型(Foundation Models)已经促进了自然语言处理(NLP)和计算机视觉(CV)领域的变革。通过在大量数据上进行预训练,这些模型在各种下游任务中表现出色,甚至在没有见过的数据上也能很好地完成任务。
这种趋势正在推动时间序列预测发生重大变化,从传统的「单数据集训练单模型」 转向「通用预测」,即采用一个预训练模型来处理不同领域的预测任务。
目前,训练能够通用预测的时序预测基础模型有两条主要研究路径。第一条路径是尝试把已经在文本数据上训练好的 LLM 应用于时间序列预测任务。然而,由于这两种数据模式之间存在显著差异,这种语言与时序之间的可迁移性最近受到了一些质疑。
第二条路径是从零开始收集大量来自不同领域的时间序列大数据集,直接训练一个基础模型(如 Moirai,TimesFM 等)。然而,不同领域的时间序列数据之间在长度、频率、维度和语义上有很大差异,这限制了他们之间的迁移效果。到目前为止,构建高质量的时间序列数据集仍然充满挑战,处于探索阶段。
在本文中,论文作者提出了创新的第三条路径:用预训练好的视觉模型来构建时序预测基础模型。这是因为图像中的像素变化可以自然地看作是时间序列。这一序列和现实中的时序数据有许多相似的特点:
1. 相似的形式:图像和时序都是连续的,而语言是离散的。
2. 相似的起源:图像和时序是自然信号,源于对真实世界物理现象的观测结果,而语言是人类创造的。
3. 相似的信息密度:图像和时间序列通常包含大量冗余数据,而语言的密度更高。
4. 相似的时序特征:图像中常见的许多特征也在真实世界的时间序列数据中出现,而这些特征在语言中很少见,如下图所示。
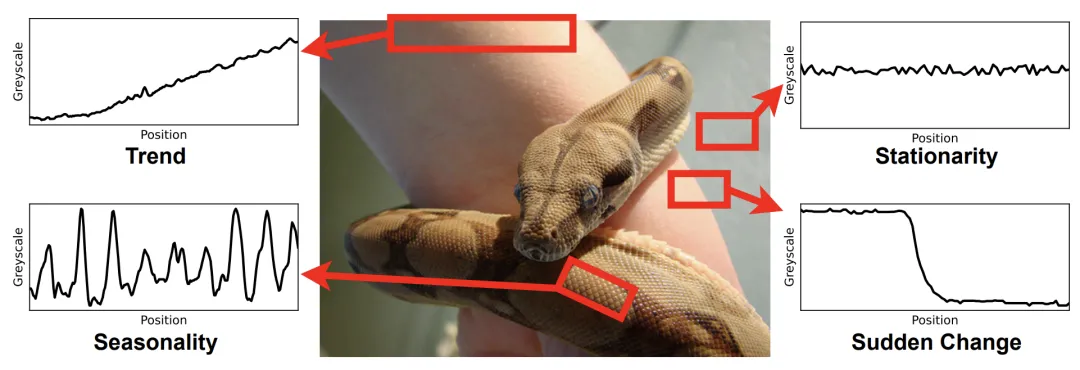 图二:ImageNet 上的一张图片:像素变化序列经常呈现出现实世界时间序列的特点,如趋势性(Trend)、周期性(Seasonality)和稳定性(Stationarity)。
图二:ImageNet 上的一张图片:像素变化序列经常呈现出现实世界时间序列的特点,如趋势性(Trend)、周期性(Seasonality)和稳定性(Stationarity)。
基于这些见解,该论文希望回答这样一个问题:一个在图像上已经训练好的视觉模型,能否直接作为通用时间序列预测的基础模型,一站式加入午餐豪华大礼包?
方法:基于何恺明的视觉 MAE
来预测时间序列
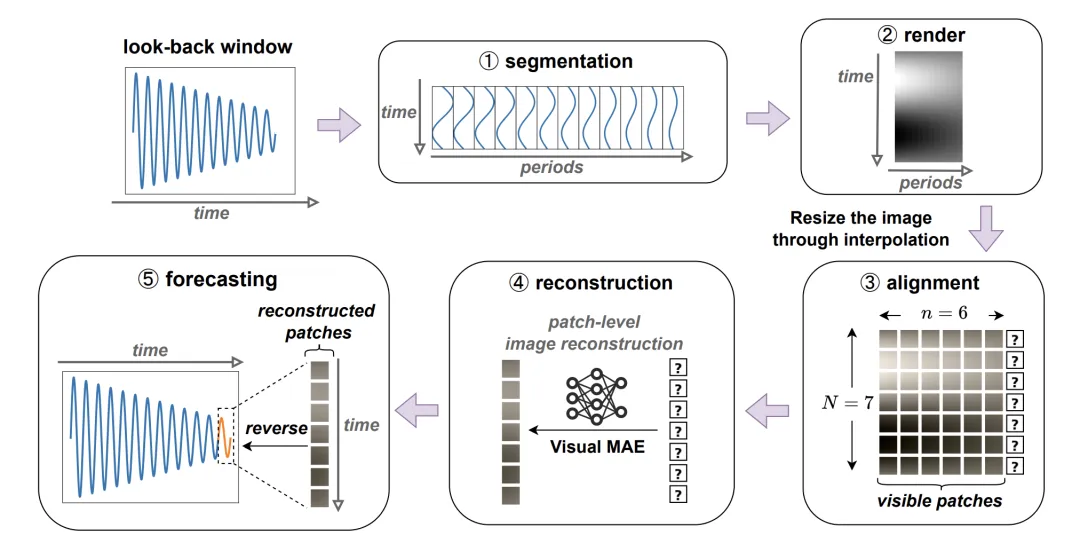
图三:VisionTS 架构。
该论文基于提示学习(prompt learning)的思想,将时间序列预测任务重构为 MAE 预训练使用的块级图像补全任务。思路很简单:将时间序列的历史窗口转变为可见的图像块(visible patches),预测窗口转变为被遮挡的图像块(masked patches),如图三所示。
1. 分割(Segmentation)
对于一个长度为 L 的输入序列窗口,第一个目标是将其转换为二维矩阵。首先将其分割成 L/P 个长度为 P 的子序列,其中 P 是周期长度(如果时间序列没有明显的周期性,可以直接设置 P=1)。接着,这些子序列被堆叠成一个二维矩阵,形状 (P, L/P)。
2. 标准化(Normalization)
MAE 会对输入进行标准化。因此,该论文提出标准化二维矩阵,将其转变为标准差为 0.4 左右的数据。
3. 渲染(Render)
众所周知,每个图像有三个通道。该论文简单地将归一化后的矩阵渲染为灰度图像,也就是三个通道都相同。
4. 对齐(Alignment)
考虑到预训练时图像的大小可能与这一矩阵大小不匹配,该论文提出将图像的尺寸从原始的 (P, L/P) 调整为适合 MAE 输入的尺寸。论文作者选择双线性插值来调整尺寸。
5. 重建与预测(Reconstruction & Forecasting)
在得到 MAE 重建的图像后,可以简单地逆转之前的步骤来进行预测。具体来说,论文作者选择将重建的整个图像重新调整回时间序列的分段,然后提取出预测窗口。
实验效果
测试结果显示,VisionTS 在涵盖多个领域的35个基准数据集上表现出色,涉及时序预测的各种场景。
下表展示了部分数据,其中 VisionTS 在无需时序数据微调的情况下,能够惊人地达到最佳预测性能。零样本情况下,能够比肩甚至超越 Moirai(一个在 27B 通用时序数据上训练的时序大模型),甚至超越了少样本训练的 LLM(TimeLLM 和 GPT4TS)以及其他常用的时序预测模型。
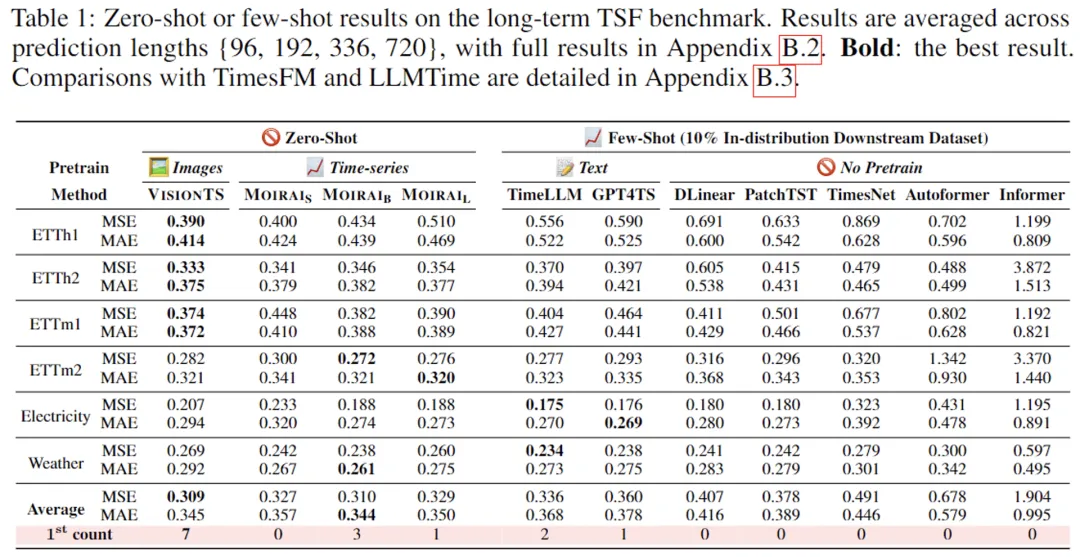
这些结果显示,图像→时间序列的迁移能力要强于文本→时间序列,甚至与不同时序数据领域之间的相互迁移能力相当。
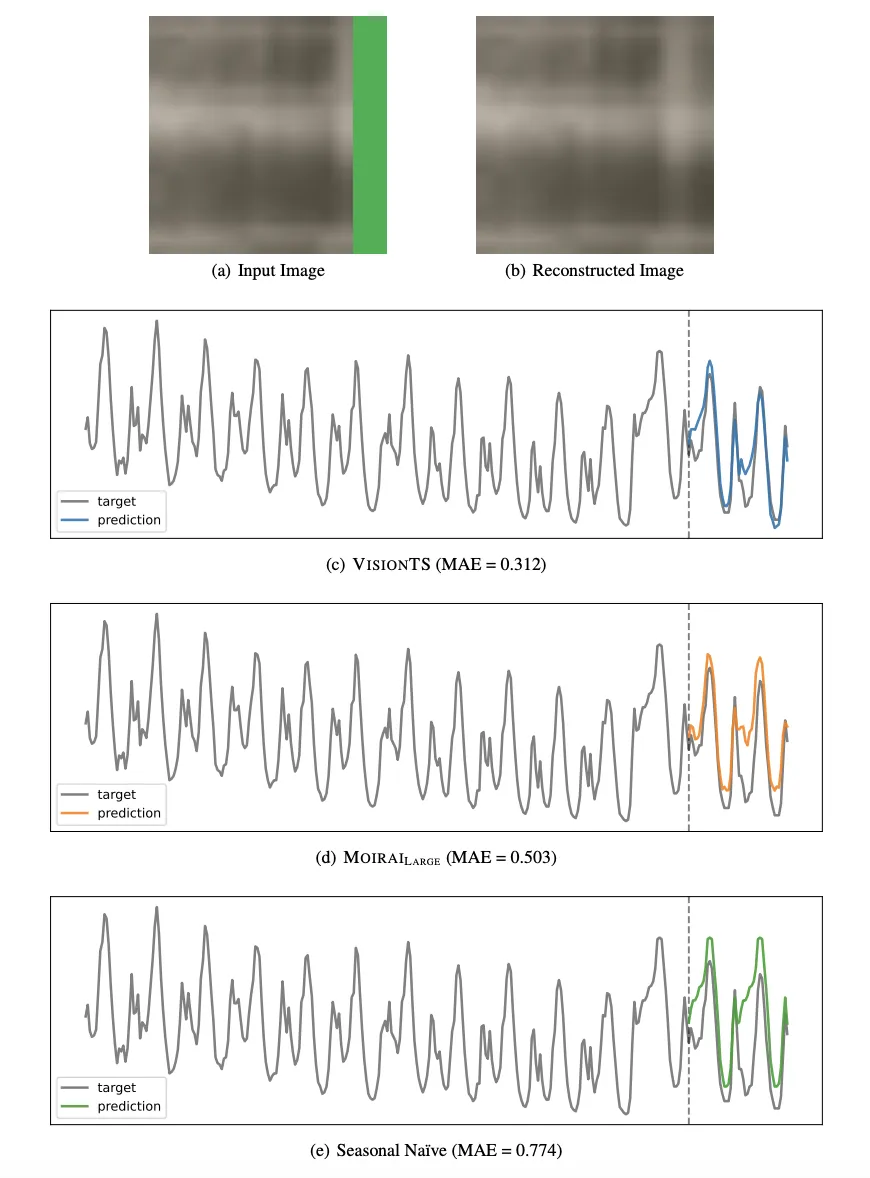
下图展示了 VisionTS 的一个预测样例,包括输入图像(a)、重建图像(b)以及对应的预测曲线(c)。可以发现,VisionTS 恰当地捕捉了这一数据的周期性和趋势性,而 Moirai 和 Seasonal Naïve 忽略了趋势性。
更多研究细节,可参考原论文。




还没有评论,来说两句吧...