

近日,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院联合团队发布基于异常检测预训练的心电长尾诊断模型。

论文链接:http://arxiv.org/abs/2408.17154
论文标题:Self-supervised Anomaly Detection Pretraining Enhances Long-tail ECG Diagnosis
研究背景
随着医疗技术的不断进步,使用无创手段来准确诊断心脏疾病变得尤为重要。在这些手段中,心电图(ECG)因其低成本和广泛使用的特点,被认为是诊断心脏健康的关键工具。然而,分析 ECG 数据面临着一个重大挑战:数据的长尾分布。这意味着大部分 AI 技术虽然能有效检测常见的心脏病,但对于稀有或非典型的异常往往难以察觉。这些未被识别的异常(如室上性心动过速、室颤和高级房室传导阻滞)可能是心源性休克和猝死等致命事件的前兆。因此,开发能够处理这些罕见异常的 AI 模型至关重要。
为了应对这些挑战,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院的研究团队提出了首个基于异常检测预训练的心电长尾诊断模型,并在以下三个方面做出了显著贡献:
创新性方法:该研究首次将自监督异常检测引入为预训练方式,模拟专业医生的诊断流程,成功开发出具有长尾诊断能力的心电 AI 模型,大幅提升了对常见及稀有心脏疾病的诊断准确性。
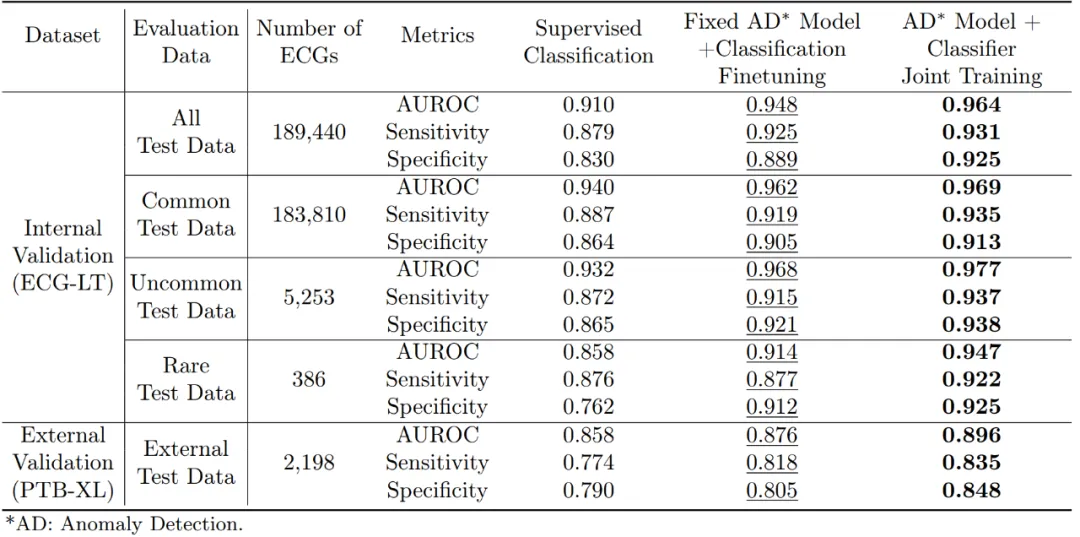
严谨的数据验证:研究团队在一个大规模的临床 ECG 记录数据集上对模型进行了严格验证。该数据集包含了 2012 年至 2021 年期间在上海真实医院环境中收集的超过一百万份 ECG 样本,涵盖了 116 种不同的 ECG 类型。经过异常检测预训练的模型在 ECG 诊断及异常检测 / 定位的内部和外部评估中均展现了显著的整体准确性提升。尤其是在处理稀有 ECG 类型时,该模型实现了 94.7% 的 AUROC、92.2% 的灵敏度和 92.5% 的特异性,明显优于传统方法,并显著缩小了与常见 ECG 类型诊断性能之间的差距。
前瞻性临床验证:在前瞻性验证中,采用该模型辅助诊断的心脏病医生相比于单独工作的医生,诊断准确率提高了 6.7%,诊断完整性提升了 11.8%,诊断时间减少了 32%。这些结果表明,将异常检测预训练集成到 ECG 分析中,具有极大的潜力来解决临床诊断中长尾数据分布的挑战。
接下来将从数据、方法与实验结果三个方面介绍原文细节。
数据介绍
本研究使用了一个涵盖从 2012 年至 2021 年期间上海真实医院数据的大规模心电图(ECG)数据集,总共包含 1089367 个样本。每个样本不仅包括心电图信号图像,还包含一个详细的诊断摘要,记录了特定的异常情况。数据集中涵盖了从常见到罕见的 116 种心电异常类型。例如,房室传导阻滞是一种较常见的类型,有数万个样本;而双室肥大则是一种非常罕见的异常,仅有极少的样本。这种明显的长尾分布突出了研究中的挑战。
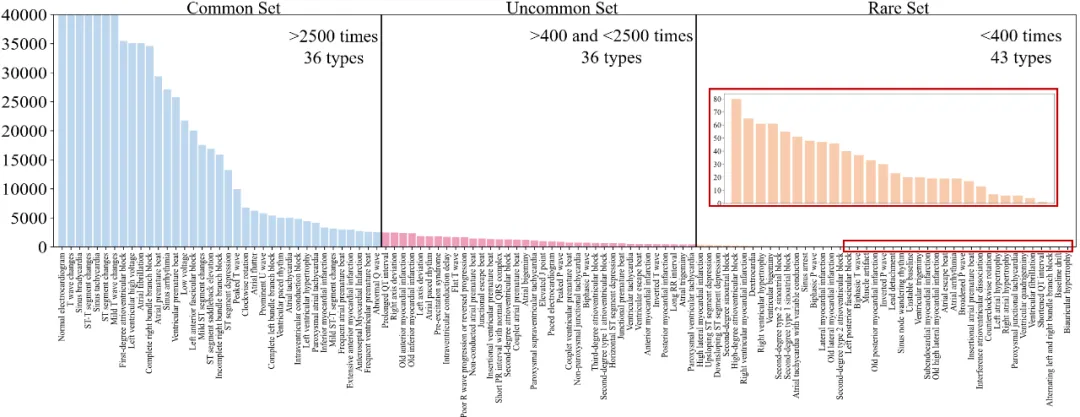
图一:心电类型长尾分布情况
这 116 种心电图类型可以大致分为三类:疾病分类、非特异性特征以及信号采集。研究团队收集了截至 2020 年的所有心电图记录,共计 416,951 个正常心电图和 482,976 个异常心电图,并将其用于模型训练。为有效评估模型在长尾分布场景下的分类性能,研究团队在 2021 年的心电图数据上进行了内部验证,验证数据包括 94,304 个正常心电图和 95,136 个异常心电图。为进一步测试模型的适应性,团队根据心电图类型的出现频率将验证集划分为三种不同的测试集:常见类型、不常见类型和罕见类型。
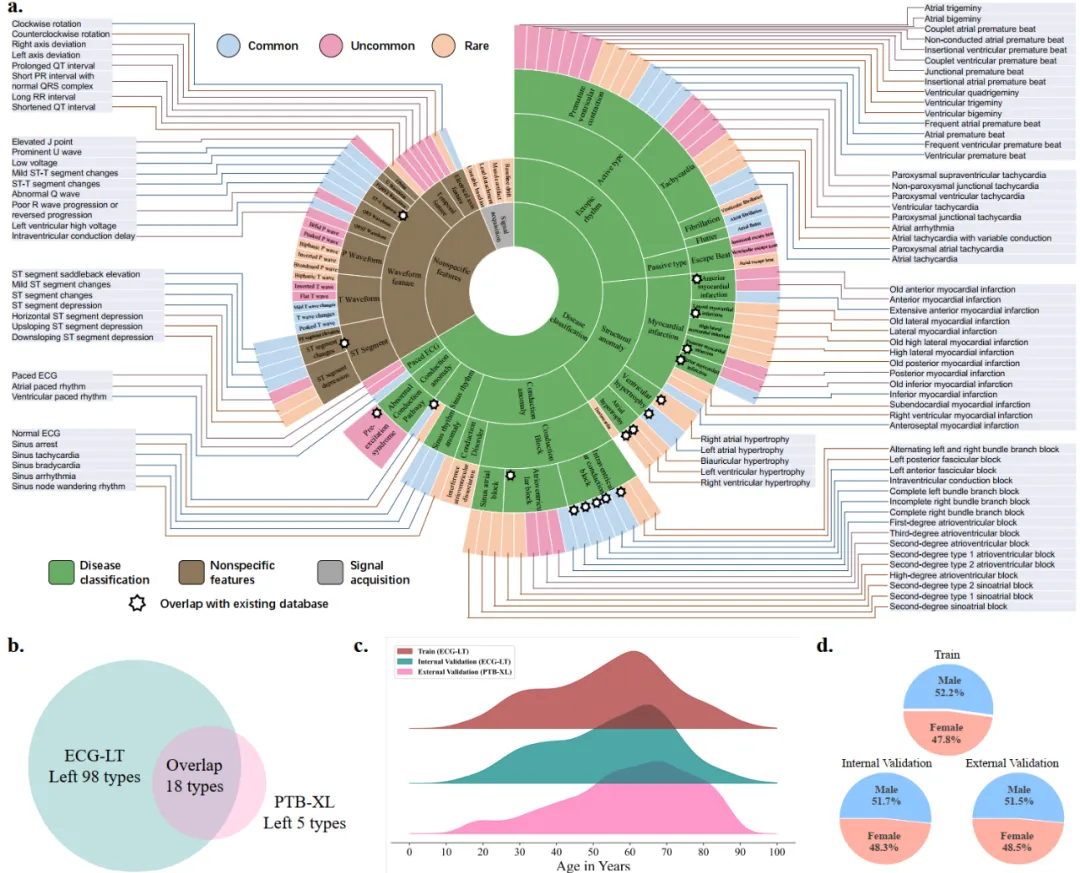
图二:数据集具体类型,年龄性别分布,与外部验证的开源数据集 PTB-XL 对比
方法介绍
本研究提出了一个新颖的两阶段框架,将 ECG 诊断转化为一个细粒度、长尾分类问题。首先,框架通过异常检测预训练阶段来定位心电图中的异常区域,这有助于后续分类任务的集中和精确执行。基础假设是,预训练通过专注于区分正常和异常信号,使模型能够更有效地识别罕见异常的特征,进而提升模型在长尾数据分布上的表现。分类组件无缝集成到预训练的异常检测模型中,作为一个额外分类头,确保一个统一的诊断流程,模拟专家心脏病学家所进行的全面、逐步分析。
该框架的核心创新在于,设计了一种专门针对 ECG 信号的新型掩码和恢复技术,用于自监督异常检测预训练。该框架的核心组件是多尺度交叉注意力模块,大大增强了模型在整合全局与局部信号特征方面的能力。与现有主要聚焦于时间序列分析的异常检测方法不同,本研究还整合了 QRS 和 QT 间期等关键 ECG 参数以及年龄、性别等人口统计因素,这些因素对于准确理解个体心脏状况至关重要。通过这种综合集成,该框架能够更细致地解读 ECG 信号,减少个体差异对诊断的影响,从而显著提升诊断的准确性。
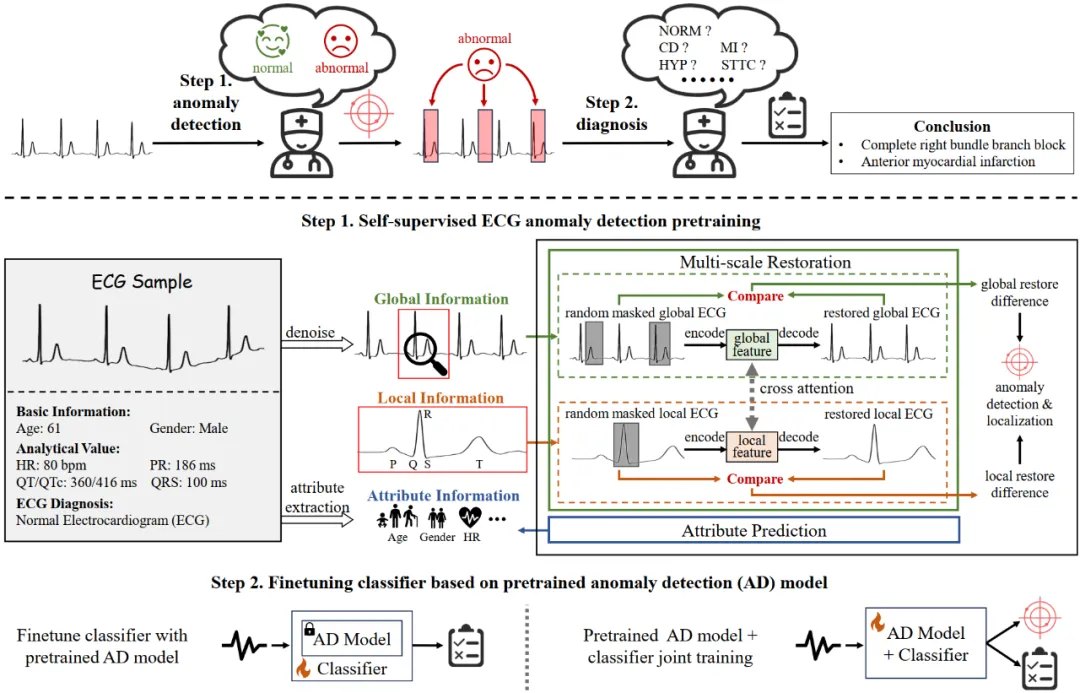
图三:提出的两阶段 ECG 诊断框架仿照医生的诊断流程,包括两个主要步骤,即自监督的心电图异常检测预训练和基于预训练的异常检测模型微调分类器
实验结果
(1)内部验证
实验结果显示,使用简单的监督分类方法时,随着 ECG 类型从常见转为稀有,模型性能显著下降。然而,当引入基于预训练的异常检测模型(使用正常 ECG 数据进行训练)后,这种性能下降得到了明显缓解。在实验中,研究团队通过两种设置(1. 固定异常检测模型,仅微调分类器,2. 联合训练异常检测模型和分类器)对模型进行了评估,结果显示,无论哪种设置,模型在处理所有数据子集时的指标均有所改善,尤其是在应对长尾稀有数据时表现尤为突出。
表一:心电诊断内 / 外部验证结果
除了评估总体诊断性能外,确保模型在关键人口特征上的公平性也至关重要,尤其是在临床应用中,不同年龄组和性别之间的诊断准确性需要保持一致。实验结果显示,男性和女性之间的诊断性能基本相当。在所有测试数据中,不同年龄组的诊断性能也相对一致,虽然在 10 岁以下和 90 岁以上患者中的表现略低,但在 10 岁至 90 岁之间的年龄组中,模型的 AUROC 和特异性均保持在 90% 以上。
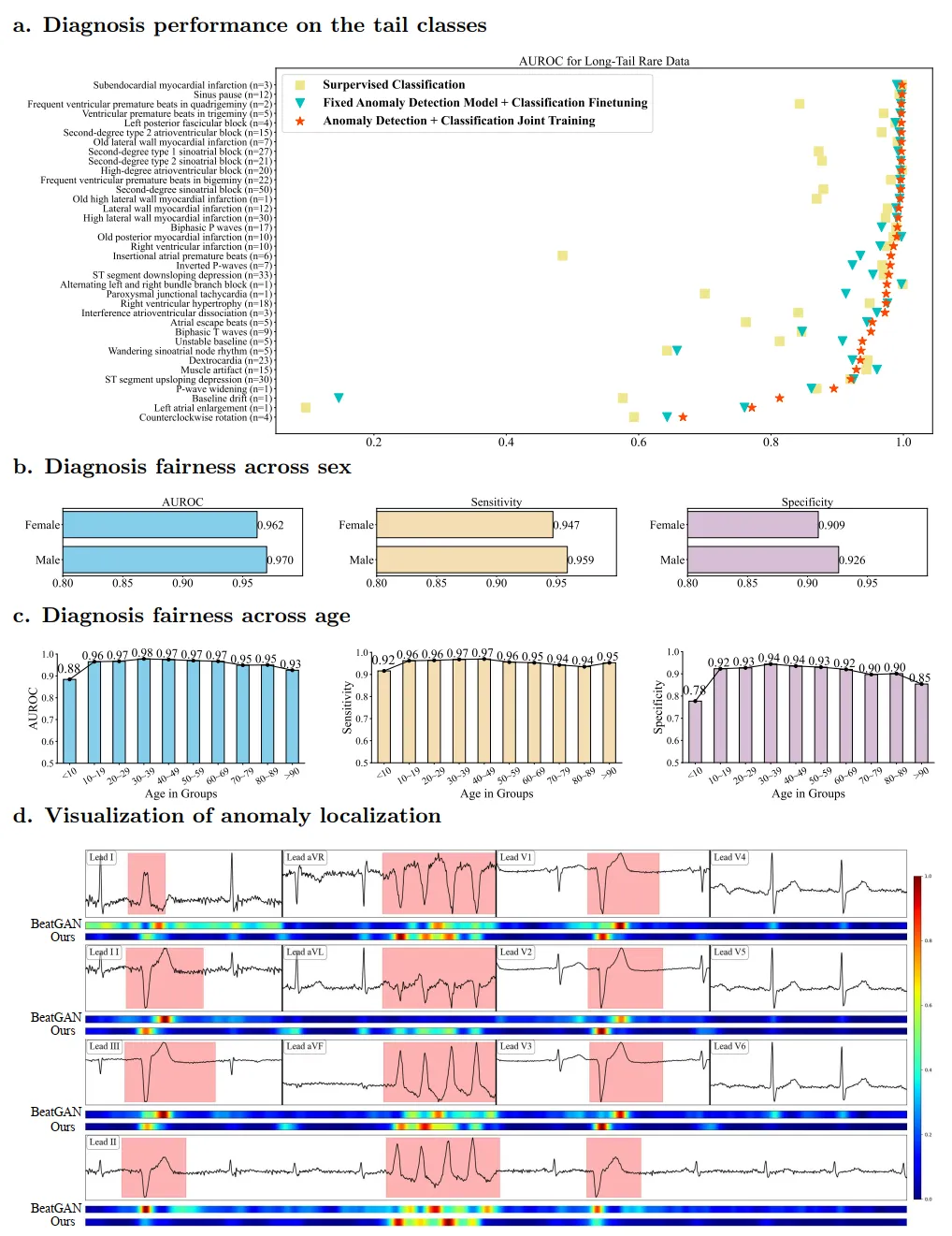
图四:长尾类型的诊断结果,诊断公平性与异常定位效果
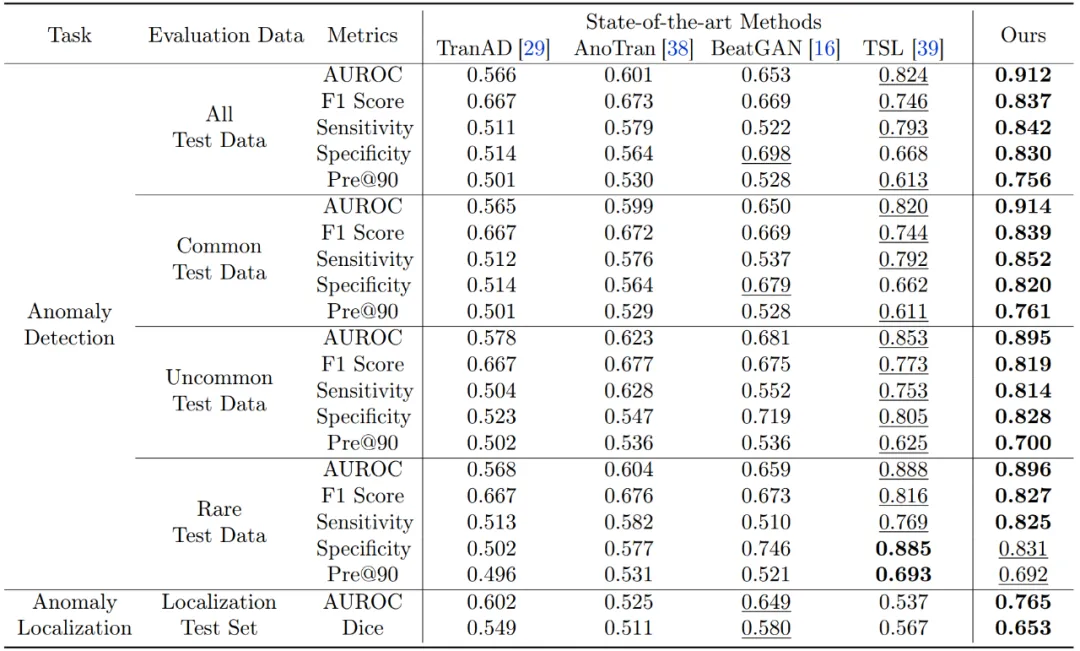
在异常检测性能评估上,研究团队提出的方法在大多数评价指标上均优于现有方法,涵盖所有测试数据集。具体来说,该方法实现了 91.2% 的 AUROC,83.7% 的 F1 分数,84.2% 的敏感性,83.0% 的特异性,以及在固定 90% 召回率下 75.6% 的精度,显著超越了其他竞争方法。该模型对细微信号模式变化的敏感性更高,能够比真实情况中的广泛标注更精确地定位异常。这些精准定位为潜在异常提供了宝贵的见解,从而为医疗从业者提供了显著支持。
表二:心电异常检测与定位实验结果
(2)外部验证
研究团队使用欧洲的开源心电数据集 PTB-XL 对研究方法和基线模型进行了外部验证。与内部数据集相比,该数据集在年龄分布、信号采集质量和心电图信号类型方面存在显著差异。通过线性探测将本方法应用于外部验证数据集时,联合训练的异常检测模型与分类器实现了最高的诊断准确性。值得注意的是,在线性探测过程中,只有分类器的最终线性层参与了训练,而其余模型参数则保持不变。
(3)前瞻验证
为了严格评估模型在真实临床环境中的表现,研究团队在不进行微调的情况下,将模型部署在医院环境中,设置了 AI 辅助诊断组和对照组,通过对比两组医生的诊断准确率、诊断效率和结论完整度,来验证 AI 模型辅助诊断对心脏病专家诊断过程的影响。每份心电图都由至少三位心脏病专家在不同条件下进行评估:
a. 心脏病专家 A 的任务是在尽可能短的时间内提供诊断结论,模拟紧急情况下需要快速决策的场景。
b. 心脏病专家 B 在没有时间限制的情况下独立进行诊断,代表常规诊断流程。
c. 心脏病专家 C 在 AI 模型的辅助下进行诊断,模型为每个病例提供了五种最有可能的异常类型作为参考。
在时间限制下,心脏病专家的诊断准确性较低,心脏病专家 A 的结论不够全面,主要集中于识别关键疾病。相比之下,在没有时间限制的情况下,心脏病专家 B 的诊断全面性和准确性都有显著提升。AI 方法的优势在于分析一份心电图只需 0.055 秒,速度大约是人类急诊诊断时间的 1000 倍。除了速度优势外,AI 方法还实现了 81.9% 的诊断准确率,明显优于未使用辅助工具的人类 67.7% 的诊断准确率。当结合临床实践时,AI 辅助的心脏病专家诊断准确率达到了 84.0%,比未使用辅助工具的诊断提高了 6.7%。此外,诊断效率显著提高,平均诊断时间缩短了 36 秒。AI 系统还提供了更详细的信号模式和节律分析,特别是在识别 T 波变化和窦性心动过速等细微变化方面,使 11.8% 的心电图结论更加全面,从而提升了诊断结果的整体质量。
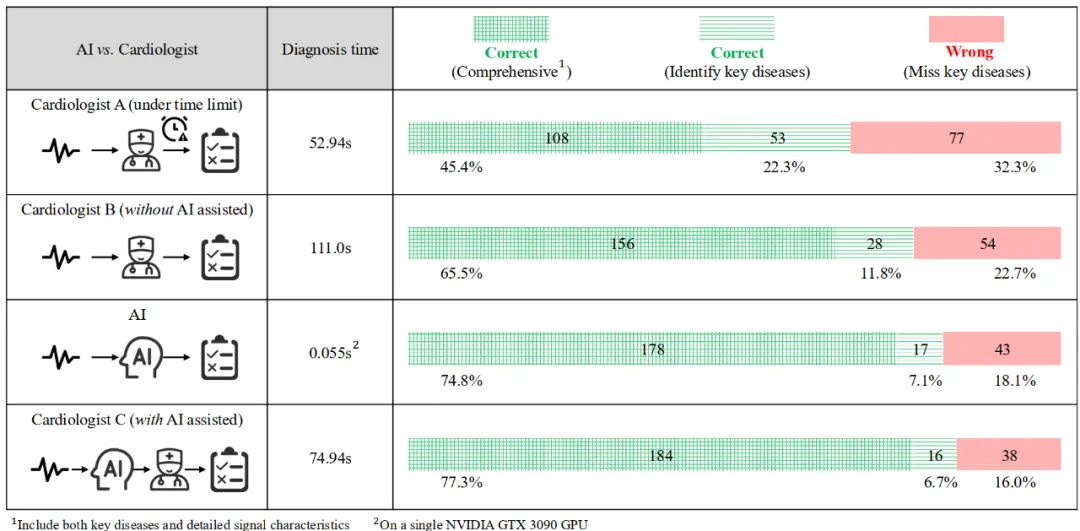
图五:前瞻验证中,诊断准确率,结论完整性与诊断时间对比
在临床诊断中,尤其是面对长尾异常,心脏病专家在时间限制或经验不足的情况下,容易出现误诊,通常表现为较高的特异性(>99%)但敏感性却非常低(<50%)。将 AI 整合到诊断过程中,显著减少了这些误诊,提高了对罕见异常的检测能力,并突出了关键的信号模式。当 AI 作为辅助工具使用时,心脏病专家在处理长尾数据时的敏感性从 46.9% 提高到 71.4%,同时特异性仍保持在 99.7% 的高水平。这表明 AI 在增强临床决策,特别是在具有挑战性的诊断场景中,展现出了巨大的潜力。
表三:前瞻验证中,常见与长尾心电类型的诊断敏感性,特异性对比

研究价值
作为首个基于异常检测预训练的心电长尾诊断模型,该研究在以下几个方面展现了其重要价值:
临床应用的巨大潜力:通过异常检测预训练,该模型能够以远超经验丰富的心脏病专家的速度,提供准确且全面的诊断结果。这表明,AI 辅助系统在临床诊断中具有广阔的应用前景,无论是在紧急情况下还是常规 ECG 评估中,均能发挥重要作用。
减轻长尾分布影响的能力:异常检测预训练通过识别可能的异常特征偏差,使模型能够集中关注特定异常区域,从而更精确地分类不同类型的异常。这种方法促进了对各种稀有异常的高效学习,有效应对了不平衡的长尾异常分布带来的挑战。
提供可解释且信息丰富的定位结果:除了提升诊断性能外,异常检测预训练还具备一个关键优势,即能够精确定位异常。这为模型的诊断决策提供了清晰且易于理解的解释,有助于医疗从业者更好地理解诊断结果。
临床诊断模型的公平性:该研究模型在男性和女性之间,以及 10 至 90 岁各年龄组中的诊断效果相当。这些发现强调了在临床实践中,考虑人口统计因素以提升诊断准确性和公平性的重要性。进一步研究有助于揭示这些年龄和性别差异的机制,从而开发改善所有患者群体健康结果的策略。
可扩展的 ECG 诊断框架:该框架专为解决 ECG 数据的长尾分布问题而设计,并经过对 116 种不同 ECG 类型的细致训练。这种全面覆盖确保了模型能够适应临床实践中遇到的几乎所有 ECG 类型,使其在多样化数据集中的适应性和通用性得到了高度保障。




还没有评论,来说两句吧...