

近年来,随着文本属性图(TAG)在社交媒体、电子商务、推荐系统和学术引用网络等领域的广泛应用,研究人员对如何有效地从这些复杂数据结构中学习变得越来越感兴趣。TAG不仅包含了节点之间的结构关系,还包含了节点本身的文本特征,因此如何同时处理这两种信息成为研究中的一个核心问题。
当前,图神经网络(GNN)在TAG学习中得到了广泛的应用,然而其训练过程通常需要大量的人工标注数据,这在实际应用中往往难以获取。
大语言模型(LLM)以其在少样本和零样本学习中的出色表现,为解决数据稀缺问题带来了曙光。然而,LLM的部署和使用成本高昂,且存在隐私数据泄露的风险,这使得LLM在一些实际场景中的应用受到了限制。
为了解决这些问题,埃默里大学(Emory)大学的研究团队提出了一种通过知识蒸馏将LLM的能力转移到本地图模型的方法,该方法创新性地结合了LLM的推理能力与GNN的结构化学习能力,通过将LLM生成的详细推理过程转化为图模型能够理解的信息,从而在无需依赖LLM的情况下,实现高效的TAG学习。

论文链接:https://arxiv.org/pdf/2402.12022
在将LLM蒸馏到本地模型的目标下,研究团队面临了多重挑战,主要集中在以下几个方面:
1. 如何让语言模型教会图模型?
大语言模型是生成性模型,能够输出详细而丰富的文本信息,而图神经网络则通常是判别性模型,其输入和输出都相对简洁。传统的知识蒸馏方法通过对齐输出的方式,难以让图模型充分吸收语言模型中的知识。因此,如何在训练过程中有效地将语言模型中的丰富知识传递给图模型,是研究团队面临的一个重要难题。
2. 如何将文本推理转化为图推理?
大语言模型生成的推理依据通常以自然语言的形式存在,而图模型难以直接理解这些文本信息。因此,如何将这些文本推理转化为图模型能够理解的图推理,是一个未被充分探索且具有挑战性的问题。研究团队需要设计出一种方法,使得图模型能够利用语言模型的推理依据来增强自身的学习能力。
3. 如何在蒸馏过程中协同文本和图信息?
文本属性图(TAG)同时包含文本和图结构信息,这两者之间高度异构。在知识蒸馏过程中,如何确保学生模型能够同时保留文本和图信息以及它们之间的相互作用,是研究团队面临的另一重大挑战。研究团队需要找到一种方法,使得学生模型不仅能从解释器模型中继承知识,还能在没有语言模型支持的情况下,独立处理并理解这些异构信息。
方法
在这项研究中,Emory大学的研究团队提出了一种创新的框架,通过蒸馏大语言模型(LLM)的知识来增强图神经网络(GNN)在文本属性图(TAG)学习中的性能。该方法分为两大核心部分:解释器模型的训练和学生模型的对齐优化。
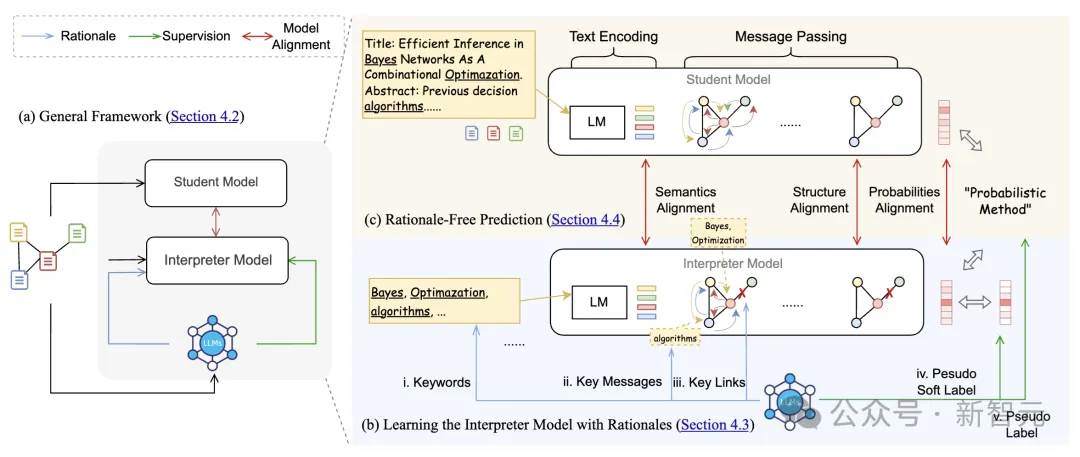
1. 解释器模型的训练
多层次特征增强: 研究团队首先设计了一个解释器模型,该模型的主要任务是理解并吸收LLM生成的推理依据。为了让解释器模型能够有效地学习LLM的知识,研究团队将LLM的推理依据转化为多层次的图推理增强特征。具体来说,这些特征包括:
文本级特征:LLM识别并提取与分类最相关的关键词,从而减少文本中可能干扰模型分类的噪声信息。这些关键词通过文本编码器进行处理,以生成增强的文本嵌入。
结构级特征:LLM分析每个节点的邻居节点,识别出对节点分类最重要的邻居节点,并提取这些邻居节点中的关键信息。这些增强的结构特征用于图卷积网络(GNN)的信息传递过程中。
消息级特征:在结构级特征的基础上,LLM进一步识别出每个邻居节点中最关键的消息内容,并将其整合到消息传递的第一层中。通过这种方式,解释器模型能够聚焦于更具相关性的邻居信息,从而提高分类精度。
伪标签与伪软标签生成:为了提供更加细腻的监督信号,研究团队使用LLM生成的伪标签和伪软标签来训练解释器模型。伪软标签包含了每个类别的概率信息,这比硬分类标签提供了更多的监督信息,有助于解释器模型更好地学习LLM的推理逻辑。
2. 学生模型的对齐优化
模型对齐方法: 为了让学生模型在没有LLM支持的情况下也能做出准确预测,研究团队设计了一种新的TAG模型对齐方法,该方法同时考虑了语义和结构的对齐。
语义对齐:研究团队通过对比解释器模型和学生模型的文本嵌入,特别是那些在结构中出现频率较高且关键词差异较大的节点,来实现语义对齐。这种对齐方式确保了学生模型能够更好地继承解释器模型中的语义信息。
结构对齐:在结构对齐中,研究团队关注那些邻居结构变化较大的节点,计算这些节点的原始邻居结构与增强邻居结构之间的相似度。通过最小化这些差异,确保学生模型能够在图结构信息上与解释器模型保持一致。
多任务学习与对齐目标:在训练过程中,研究团队采用多任务学习的方法,使用交叉熵损失来优化伪标签的预测,同时使用均方误差损失来对齐解释器模型和学生模型的输出。最终的训练目标整合了语义对齐和结构对齐的损失,使得学生模型能够在没有LLM的情况下进行高效推理。
实验与结果
研究团队在四个广泛使用的文本属性图数据集上验证了他们的方法,包括Cora、PubMed、ogbn-products和arxiv-2023数据集。实验结果显示,该方法在所有数据集上均表现出色,特别是在标签稀缺的情况下,性能提升尤为显著。
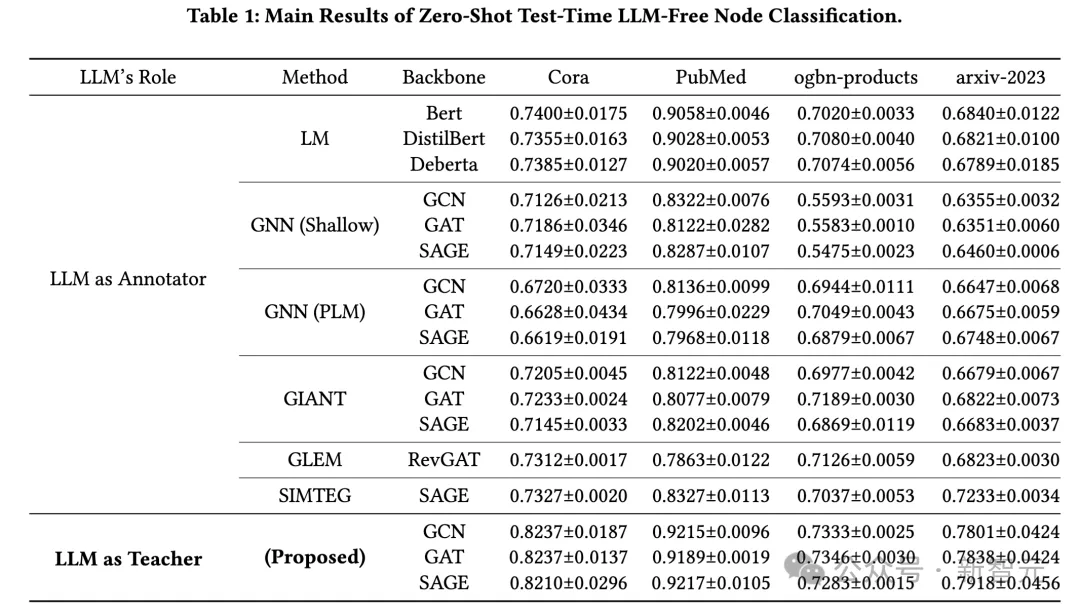
在Cora数据集上,该方法的准确率相比现有方法提高了10.3%,而在PubMed和ogbn-products数据集上,分别提高了2.2%和4%。特别是在arxiv-2023数据集上,由于其内容超出了现有大语言模型的知识截止日期,研究团队的方法依然实现了8.3%的性能提升,进一步证明了该方法在处理新颖和未见数据方面的能力。
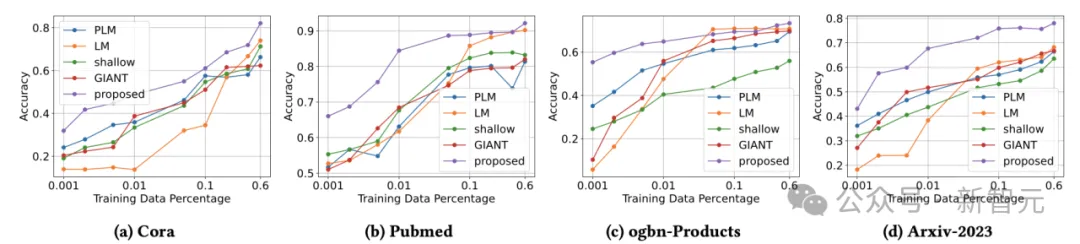
研究团队进一步分析了不同训练数据比例下的模型性能,结果显示该方法在训练数据稀缺的情况下仍能保持优异的表现。这表明,通过蒸馏LLM的推理能力到学生模型,该方法能够在有限的数据下有效学习,显示出强大的泛化能力。
在计算成本方面,尽管研究团队的方法在训练时需要处理更多的输入输出数据(如LLM生成的推理依据),但其训练和测试时间与现有方法相当,显示出良好的效率。尤其是在处理大型数据集时,这种蒸馏方法能够显著降低计算成本,使其在实际应用中更具可行性。
结论
研究团队的工作为如何在不依赖LLM的情况下有效利用其能力提供了新的思路。通过将大语言模型的知识蒸馏到本地图模型中,研究人员不仅成功解决了TAG学习中的标签稀缺问题,还显著提升了模型的性能和迁移性。这一研究不仅在学术界具有重要意义,也为工业界在隐私保护和成本控制方面提供了实用的解决方案。




还没有评论,来说两句吧...