

在人工智能领域,模型参数的增多往往意味着性能的提升。但随着模型规模的扩大,其对终端设备的算力与内存需求也日益增加。低比特量化技术,由于可以大幅降低存储和计算成本并提升推理效率,已成为实现大模型在资源受限设备上高效运行的关键技术之一。然而,如果硬件设备不支持低比特量化后的数据模式,那么低比特量化的优势将无法发挥。
为了解决这一问题,微软亚洲研究院推出了全新的数据编译器 Ladder 和算法 T-MAC,使当前只支持对称精度计算的硬件能够直接运行混合精度矩阵乘法。测试结果表明,Ladder 在支持 GPU 原本不支持的自定义数据类型方面,最高提速可达 14.6 倍;T-MAC 在搭载了最新高通 Snapdragon X Elite 芯片组的 Surface AI PC 上,使 CPU 上运行的大模型吞吐率比专用加速器 NPU 快两倍。此外,研究员们还设计了 LUT Tensor Core 硬件架构,这种精简设计使硬件能够直接支持各种低比特混合精度计算,为人工智能硬件设计提供了新思路。
大模型已经越来越多地被部署在智能手机、笔记本电脑、机器人等端侧设备上,以提供先进的智能及实时响应服务。但包含上亿参数的大模型对终端设备的内存和计算能力提出了极高的要求,也因此限制了它们的广泛应用。低比特量化技术因其能显著压缩模型规模,降低对计算资源的需求,成为了大模型在端侧部署和实现高效推理的有效手段。
随着低比特量化技术的发展,数据类型日益多样化,如 int4、int2、int1 等低比特数据,使得大模型在推理中越来越多地采用低比特权重和高比特权重计算的混合精度矩阵乘法(mixed-precision matrix multiplication,mpGEMM)。然而,现有的 CPU、GPU 等硬件计算单元通常只支持对称计算模式,并不兼容这种混合精度的矩阵乘法。
混合精度矩阵乘法与传统的矩阵乘法有何不同?
在传统的矩阵乘法中,参与运算的两端数值是对称的,例如 FP16*FP16、int8*int8。但大模型的低比特量化打破了这种对称性,使乘法的一端是高比特,另一端是低比特,例如在 1-bit 的 BitNet 模型中实现的 int8*int1 或 int8*int2,以及浮点数与整数的混合乘法 FP16*int4。
为了充分发挥低比特量化的优势,让硬件设备能够直接支持混合精度矩阵乘法,确保大模型在端侧设备上的高速有效运行,微软亚洲研究院的研究员们针对现有 CPU、GPU 计算算子和硬件架构进行创新:
推出了数据类型编译器 Ladder,支持各种低精度数据类型的表达和相互转换,将硬件不支持的数据类型无损转换为硬件支持的数据类型指令,在传统计算模式下,使得硬件能够支持混合精度的 DNN(深度神经网络) 计算;
研发了全新算法 T-MAC,基于查找表(Lookup Table,LUT)的方法,实现了硬件对混合精度矩阵乘法的直接支持,软件层面,在 CPU 上的计算相比传统计算模式取得了更好的加速;
提出了新的硬件架构 LUT Tensor Core,为下一代人工智能硬件设计打开了新思路。
Ladder:自定义数据类型无损转换成硬件支持的数据类型
当前,前沿加速器正在将更低比特的计算单元,如 FP32、FP16,甚至 FP8 的运算集成到新一代的架构中。然而,受限于芯片面积和高昂的硬件成本,每个加速器只能为标准的数据类型提供有限类型的计算单元,比如 NVIDIA V100 TENSOR CORE GPU 仅支持 FP16,而 A100 虽然加入了对 int2、int4、int8 的支持,但并未涵盖更新的 FP8 或 OCP-MXFP 等数据格式。此外,大模型的快速迭代与硬件升级的缓慢步伐之间存在差距,导致许多新数据类型无法得到硬件支持,进而影响大模型的加速和运行。
微软亚洲研究院的研究员们发现,尽管硬件加速器缺乏针对自定义数据类型的计算指令,但其内存系统可以将它们转换为固定位宽的不透明数据块来存储任意数据类型。同时,大多数自定义数据类型可以无损地转换为现有硬件计算单元支持的更多位的标准数据类型。例如,NF4 张量可以转换成 FP16 或 FP32 以执行浮点运算。
基于这些发现,研究员们提出了一种通过分离数据存储和计算来支持所有自定义数据类型的方法,并研发了数据编译器 Ladder,以弥合不断出现的自定义数据类型与当前硬件支持的固有精度格式之间的差距。
Ladder 定义了一套数据类型系统,包括数据类型之间无损转换的抽象,它能够表示算法和硬件支持的各种数据类型,并定义了数据类型之间的转换规则。当处理低比特算法应用时,Ladder 通过一系列优化,将低比特数据转译成当前硬件上最高效的执行格式,包括对计算和存储的优化 —— 将算法映射到匹配的计算指令,并将不同格式的数据存储到不同级别的存储单元中,以实现最高效的运算。
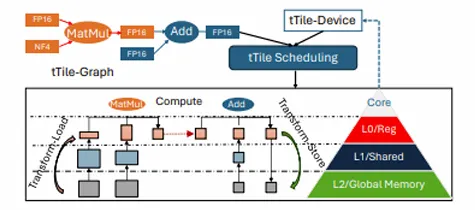
图 1:Ladder 的系统架构
在 NVIDIA A100、NVIDIA V100、NVIDIA RTX A6000、NVIDIA RTX 4090 和 AMD Instinct MI250 GPU 上运行的 DNN 推理性能评估显示,Ladder 在原生支持数据类型上超越了现有最先进的 DNN 编译器,并且在支持 GPU 原本不支持的自定义数据类型方面表现出色,最高提速可达 14.6 倍。
Ladder 是首个在现代硬件加速器上运行 DNN 时,可以系统性地支持以自定义数据类型表示低比特精度数据的系统。这为模型研究者提供了更灵活的数据类型优化方法,同时也让硬件架构开发者在不改变硬件的情况下,支持更广泛的数据类型。
T-MAC:无需乘法的通用低比特混合精度矩阵乘计算
为了让现有硬件设备支持不同的数据模式和混合精度矩阵乘法,在端侧部署大模型时,常见的做法是对低比特模型进行反量化。然而,这种方法存在两大问题:首先,从性能角度来看,反量化过程中的转换开销可能会抵消低比特量化带来的性能提升;其次,从开发角度来看,开发者需要针对不同的混合精度重新设计数据布局和计算内核。微软亚洲研究院的研究员们认为,在设备上部署低比特量化的大模型,关键在于如何基于低比特的特点来突破传统矩阵乘法的实现。
为此,研究员们从系统和算法层面提出了一种基于查找表(LUT,Look-Up Table)的方法 T-MAC,帮助低比特量化的大模型在 CPU 上实现高效推理。T-MAC 的核心思想在于利用混合精度矩阵乘法的一端为极低比特(如 1 比特或 2 比特)的特点。它们的输出结果只有 2 的 1 次方和 2 的 2 次方种可能,这些较少的输出结果完全可以提前计算并存储在表中,在运算时,只需从表中读取结果,避免了重复计算,大幅减少了乘法和加法的运算次数。
具体而言,T-MAC 将传统的以数据类型为中心的乘法转变为基于位的查找表操作,实现了一种统一且可扩展的混合精度矩阵乘法解决方案,减小了表的大小并使其停留在最快的内存单元中,降低了随机访问表的成本。这一创新为在资源受限的边缘设备上部署低比特量化大模型铺平了道路。
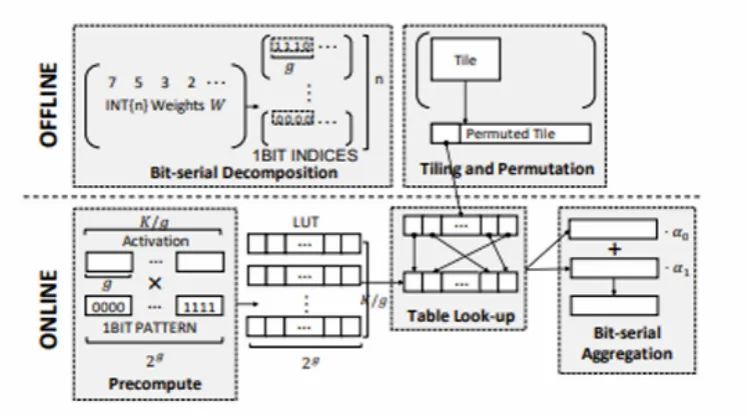
图 2:T-MAC 示意图
在针对低比特量化的 Llama 和 1 比特的 BitNet 大语言模型的测试中,T-MAC 展现出了显著的性能优势。在搭载了最新高通 Snapdragon X Elite 芯片组的 Surface Laptop 7 上,T-MAC 让 3B BitNet-b1.58 模型的生成速率达到每秒 48 个 token,2bit 7B Llama 模型的生成速率达到每秒 30 个 token,4bit 7B Llama 模型的生成速率可达每秒 20 个 token,这些速率均远超人类的平均阅读速度。与原始的 Llama.cpp 框架相比,其提升了 4 至 5 倍,甚至比专用的 NPU 加速器还快两倍。
即使是在性能较低的设备上,如 Raspberry Pi(树莓派)5,T-MAC 也能使 3B BitNet-b1.58 模型达到每秒 11 个 token 的生成速率。T-MAC 还具有显著的功耗优势,在资源受限的设备上可以达到相同的生成速率,而它所需的核心数仅为原始 Llama.cpp 的 1/4 至 1/6。
这些结果表明,T-MAC 提供了一种实用的解决方案,使得在使用通用 CPU 的边缘设备上部署大语言模型更为高效,且无需依赖 GPU,让大模型在资源受限的设备上也能高效运行,从而推动大模型在更广泛的场景中的应用。
LUT Tensor Core:推动下一代硬件加速器原生支持混合精度矩阵乘法
T-MAC 和 Ladder 都是在现有 CPU 和 GPU 架构上,实现对混合精度矩阵乘法的优化支持。尽管这些软件层面的创新显著提升了计算效率,但它们在效率上仍无法与能够直接实现一个专门查找表的硬件加速器相比。研究员们认为,最理想的方法是重新设计硬件加速器,让 CPU、GPU 等能够原生支持混合精度矩阵乘法,但这一目标面临三大挑战:
效率:设计和实现方式必须具有成本效益,通过优化芯片的利用面积,最大限度地提高低比特数据的计算效益。
灵活性:由于不同的模型和场景需要不同的权重和激活精度,因此硬件中的混合精度矩阵乘法设计必须能够处理各种权重精度 (如 int4/2/1) 和激活精度 (如 FP16/8、int8) 及其组合。
兼容性:新设计必须与现有的 GPU 架构和软件生态系统无缝集成,以加速新技术的应用。
为了应对这些挑战,微软亚洲研究院的研究员们设计了 LUT Tensor Core,这是一种利用查找表直接执行混合精度矩阵乘法的 GPU Tensor Core 微架构。一方面,基于查找表的设计将乘法运算简化为表预计算操作,可直接在表中查找结果,提高计算效率。另一方面,这种方法也简化了对硬件的需求,它只需用于表存储的寄存器和用于查找的多路选择器,无需乘法器和加法器。同时,LUT Tensor Core 通过比特串行设计实现了权重精度的灵活性,并利用表量化实现了激活精度的灵活性。
此外,为了与现有 GPU 微架构和软件堆栈集成,研究员们扩展了 GPU 中现有的 MMA 指令集,加入了一组 LMMA 指令,并设计了一个类似于 cuBLAS 的软件堆栈,用于集成到现有的 DNN 框架中。研究员们还设计了一个编译器,用于在具有 LUT Tensor Core 的 GPU 上进行端到端的执行计划。这些创新方法可以让 LUT Tensor Core 被无缝、快速地采用。
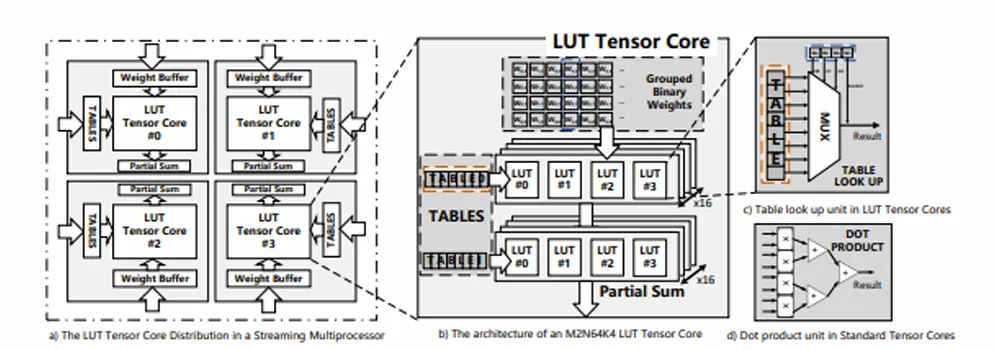
图 3:LUT Tensor Core 微架构概述
在 Llama 和 BitNet 模型上的测试显示,LUT Tensor Core 可以提供高达 6.93 倍的推理速度,且只占传统 Tensor Core 面积的 38.7%。在几乎相同的模型精度下,这相当于 20.7 倍的计算密度和 19.1 倍的能效提升。随着人工智能大模型规模和复杂性的不断增长,LUT Tensor Core 有助于进一步释放低比特大语言模型的潜力,推动人工智能在新场景中的应用。
“查找表方法引领了计算范式的转变。在过去,我们依赖于矩阵乘法和累加运算,而在大模型时代,得益于低比特量化技术,查找表方法将成为主流。相较于传统的浮点运算或矩阵乘法,查找表方法在计算上更轻便高效,而且在硬件层面上更易于扩展,能够实现更高的晶体管密度,在单位芯片面积上提供更大的吞吐量,从而推动硬件架构的革新。” 微软亚洲研究院首席研究员曹婷表示。
低比特量化的长尾效应:为具身智能带来新可能
低比特量化技术不仅优化了大模型在端侧设备上的运行效率,还通过减少单个参数的 “体积”,为模型参数的扩展(Scale up)提供了新的空间。这种参数扩展能力,使模型拥有了更强的灵活性和表达能力,正如 BitNet 模型所展示的,从低比特模型出发,逐步扩展至更大规模的训练。
微软亚洲研究院的 T-MAC、Ladder 和 LUT Tensor Core 等创新技术,为各种低比特量化大模型提供了高效能的运行方案,使得这些模型能够在各种设备上高效运行,并推动科研人员从低比特角度设计和优化大模型。其中部分技术已经在微软必应(Bing)搜索及其广告业务等搜索大模型中发挥作用。随着对内存和计算资源的降低,低比特大模型在机器人等具身智能系统上的部署也将成为可能,可以使这些设备更好地实现与环境的动态感知和实时交互。
目前,T-MAC 和 Ladder 已经在 GitHub 上开源,欢迎相关研发人员测试应用,与微软亚洲研究院共同探索人工智能技术的更多可能。




还没有评论,来说两句吧...